 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmanuel Tewolde
Social Choice for AI Alignment: Dealing with Diverse Human Feedback
Apr 16, 2024
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, so that, for example, they refuse to comply with requests for help with committing crimes or with producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about ''collective'' preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
The Computational Complexity of Single-Player Imperfect-Recall Games
May 28, 2023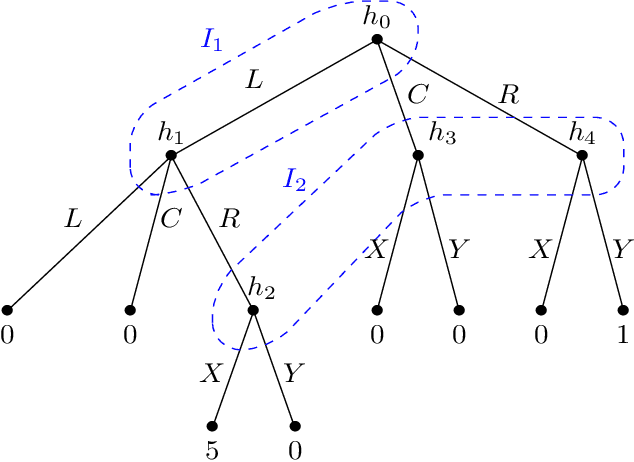
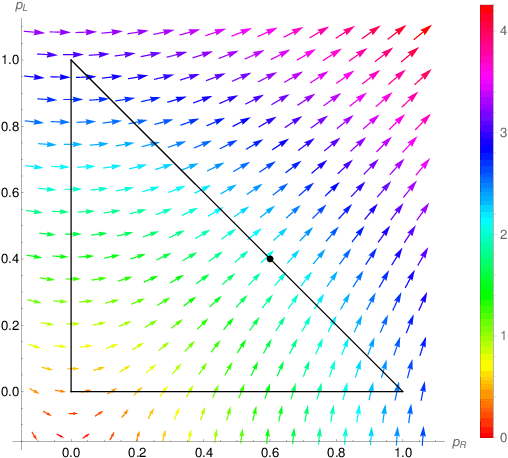
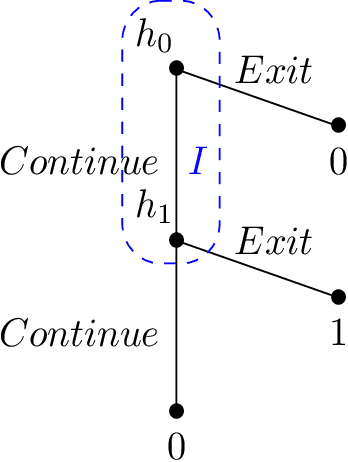
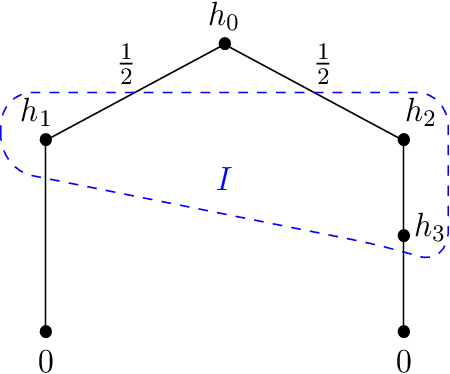
We study single-player extensive-form games with imperfect recall, such as the Sleeping Beauty problem or the Absentminded Driver game. For such games, two natural equilibrium concepts have been proposed as alternative solution concepts to ex-ante optimality. One equilibrium concept uses generalized double halving (GDH) as a belief system and evidential decision theory (EDT), and another one uses generalized thirding (GT) as a belief system and causal decision theory (CDT). Our findings relate those three solution concepts of a game to solution concepts of a polynomial maximization problem: global optima, optimal points with respect to subsets of variables and Karush-Kuhn-Tucker (KKT) points. Based on these correspondences, we are able to settle various complexity-theoretic questions on the computation of such strategies. For ex-ante optimality and (EDT,GDH)-equilibria, we obtain NP-hardness and inapproximability, and for (CDT,GT)-equilibria we obtain CLS-completeness results.