 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmanuele Rodolà
COCOLA: Coherence-Oriented Contrastive Learning of Musical Audio Representations
Apr 29, 2024
We present COCOLA (Coherence-Oriented Contrastive Learning for Audio), a contrastive learning method for musical audio representations that captures the harmonic and rhythmic coherence between samples. Our method operates at the level of stems (or their combinations) composing music tracks and allows the objective evaluation of compositional models for music in the task of accompaniment generation. We also introduce a new baseline for compositional music generation called CompoNet, based on ControlNet, generalizing the tasks of MSDM, and quantify it against the latter using COCOLA. We release all models trained on public datasets containing separate stems (MUSDB18-HQ, MoisesDB, Slakh2100, and CocoChorales).
Zero-Shot Stitching in Reinforcement Learning using Relative Representations
Apr 19, 2024Visual Reinforcement Learning is a popular and powerful framework that takes full advantage of the Deep Learning breakthrough. However, it is also known that variations in the input (e.g., different colors of the panorama due to the season of the year) or the task (e.g., changing the speed limit for a car to respect) could require complete retraining of the agents. In this work, we leverage recent developments in unifying latent representations to demonstrate that it is possible to combine the components of an agent, rather than retrain it from scratch. We build upon the recent relative representations framework and adapt it for Visual RL. This allows us to create completely new agents capable of handling environment-task combinations never seen during training. Our work paves the road toward a more accessible and flexible use of reinforcement learning.
Generalized Multi-Source Inference for Text Conditioned Music Diffusion Models
Mar 18, 2024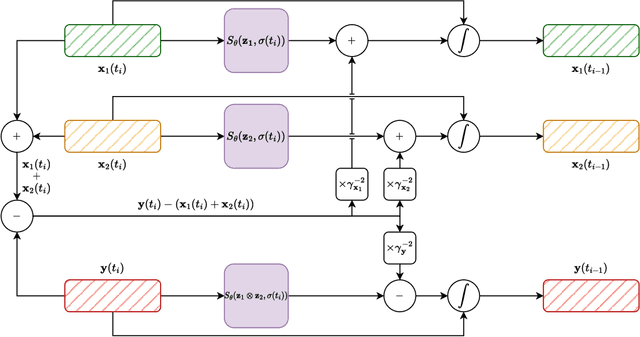
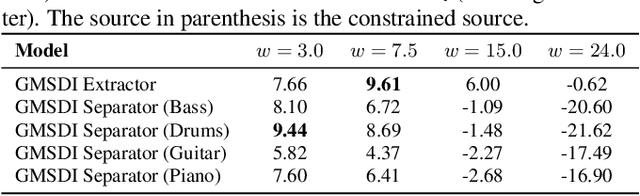
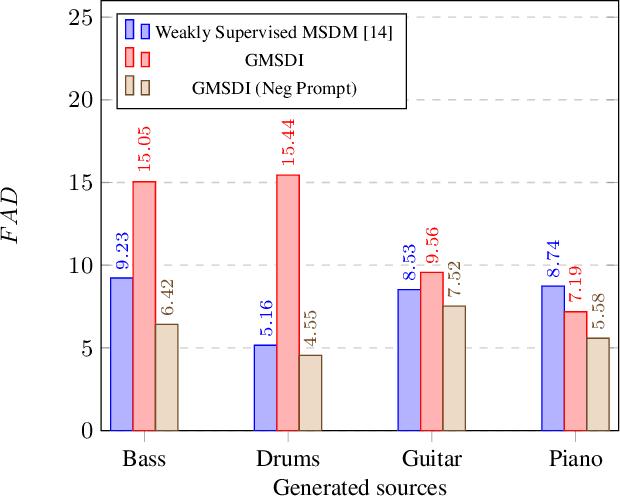

Multi-Source Diffusion Models (MSDM) allow for compositional musical generation tasks: generating a set of coherent sources, creating accompaniments, and performing source separation. Despite their versatility, they require estimating the joint distribution over the sources, necessitating pre-separated musical data, which is rarely available, and fixing the number and type of sources at training time. This paper generalizes MSDM to arbitrary time-domain diffusion models conditioned on text embeddings. These models do not require separated data as they are trained on mixtures, can parameterize an arbitrary number of sources, and allow for rich semantic control. We propose an inference procedure enabling the coherent generation of sources and accompaniments. Additionally, we adapt the Dirac separator of MSDM to perform source separation. We experiment with diffusion models trained on Slakh2100 and MTG-Jamendo, showcasing competitive generation and separation results in a relaxed data setting.
GSEdit: Efficient Text-Guided Editing of 3D Objects via Gaussian Splatting
Mar 08, 2024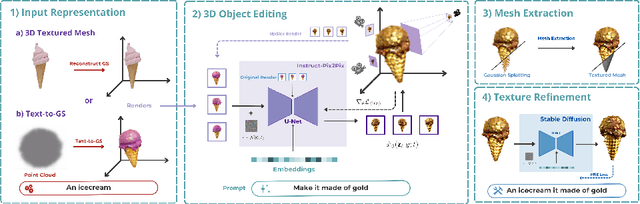

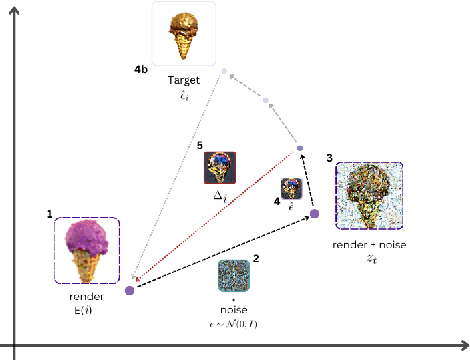

We present GSEdit, a pipeline for text-guided 3D object editing based on Gaussian Splatting models. Our method enables the editing of the style and appearance of 3D objects without altering their main details, all in a matter of minutes on consumer hardware. We tackle the problem by leveraging Gaussian splatting to represent 3D scenes, and we optimize the model while progressively varying the image supervision by means of a pretrained image-based diffusion model. The input object may be given as a 3D triangular mesh, or directly provided as Gaussians from a generative model such as DreamGaussian. GSEdit ensures consistency across different viewpoints, maintaining the integrity of the original object's information. Compared to previously proposed methods relying on NeRF-like MLP models, GSEdit stands out for its efficiency, making 3D editing tasks much faster. Our editing process is refined via the application of the SDS loss, ensuring that our edits are both precise and accurate. Our comprehensive evaluation demonstrates that GSEdit effectively alters object shape and appearance following the given textual instructions while preserving their coherence and detail.
Zero-Shot Duet Singing Voices Separation with Diffusion Models
Nov 13, 2023In recent studies, diffusion models have shown promise as priors for solving audio inverse problems. These models allow us to sample from the posterior distribution of a target signal given an observed signal by manipulating the diffusion process. However, when separating audio sources of the same type, such as duet singing voices, the prior learned by the diffusion process may not be sufficient to maintain the consistency of the source identity in the separated audio. For example, the singer may change from one to another occasionally. Tackling this problem will be useful for separating sources in a choir, or a mixture of multiple instruments with similar timbre, without acquiring large amounts of paired data. In this paper, we examine this problem in the context of duet singing voices separation, and propose a method to enforce the coherency of singer identity by splitting the mixture into overlapping segments and performing posterior sampling in an auto-regressive manner, conditioning on the previous segment. We evaluate the proposed method on the MedleyVox dataset and show that the proposed method outperforms the naive posterior sampling baseline. Our source code and the pre-trained model are publicly available at https://github.com/yoyololicon/duet-svs-diffusion.
From Charts to Atlas: Merging Latent Spaces into One
Nov 11, 2023Models trained on semantically related datasets and tasks exhibit comparable inter-sample relations within their latent spaces. We investigate in this study the aggregation of such latent spaces to create a unified space encompassing the combined information. To this end, we introduce Relative Latent Space Aggregation, a two-step approach that first renders the spaces comparable using relative representations, and then aggregates them via a simple mean. We carefully divide a classification problem into a series of learning tasks under three different settings: sharing samples, classes, or neither. We then train a model on each task and aggregate the resulting latent spaces. We compare the aggregated space with that derived from an end-to-end model trained over all tasks and show that the two spaces are similar. We then observe that the aggregated space is better suited for classification, and empirically demonstrate that it is due to the unique imprints left by task-specific embedders within the representations. We finally test our framework in scenarios where no shared region exists and show that it can still be used to merge the spaces, albeit with diminished benefits over naive merging.
Latent Space Translation via Semantic Alignment
Nov 01, 2023While different neural models often exhibit latent spaces that are alike when exposed to semantically related data, this intrinsic similarity is not always immediately discernible. Towards a better understanding of this phenomenon, our work shows how representations learned from these neural modules can be translated between different pre-trained networks via simpler transformations than previously thought. An advantage of this approach is the ability to estimate these transformations using standard, well-understood algebraic procedures that have closed-form solutions. Our method directly estimates a transformation between two given latent spaces, thereby enabling effective stitching of encoders and decoders without additional training. We extensively validate the adaptability of this translation procedure in different experimental settings: across various trainings, domains, architectures (e.g., ResNet, CNN, ViT), and in multiple downstream tasks (classification, reconstruction). Notably, we show how it is possible to zero-shot stitch text encoders and vision decoders, or vice-versa, yielding surprisingly good classification performance in this multimodal setting.
SyncFusion: Multimodal Onset-synchronized Video-to-Audio Foley Synthesis
Oct 23, 2023Sound design involves creatively selecting, recording, and editing sound effects for various media like cinema, video games, and virtual/augmented reality. One of the most time-consuming steps when designing sound is synchronizing audio with video. In some cases, environmental recordings from video shoots are available, which can aid in the process. However, in video games and animations, no reference audio exists, requiring manual annotation of event timings from the video. We propose a system to extract repetitive actions onsets from a video, which are then used - in conjunction with audio or textual embeddings - to condition a diffusion model trained to generate a new synchronized sound effects audio track. In this way, we leave complete creative control to the sound designer while removing the burden of synchronization with video. Furthermore, editing the onset track or changing the conditioning embedding requires much less effort than editing the audio track itself, simplifying the sonification process. We provide sound examples, source code, and pretrained models to faciliate reproducibility
From Bricks to Bridges: Product of Invariances to Enhance Latent Space Communication
Oct 02, 2023It has been observed that representations learned by distinct neural networks conceal structural similarities when the models are trained under similar inductive biases. From a geometric perspective, identifying the classes of transformations and the related invariances that connect these representations is fundamental to unlocking applications, such as merging, stitching, and reusing different neural modules. However, estimating task-specific transformations a priori can be challenging and expensive due to several factors (e.g., weights initialization, training hyperparameters, or data modality). To this end, we introduce a versatile method to directly incorporate a set of invariances into the representations, constructing a product space of invariant components on top of the latent representations without requiring prior knowledge about the optimal invariance to infuse. We validate our solution on classification and reconstruction tasks, observing consistent latent similarity and downstream performance improvements in a zero-shot stitching setting. The experimental analysis comprises three modalities (vision, text, and graphs), twelve pretrained foundational models, eight benchmarks, and several architectures trained from scratch.
Camoscio: an Italian Instruction-tuned LLaMA
Jul 31, 2023

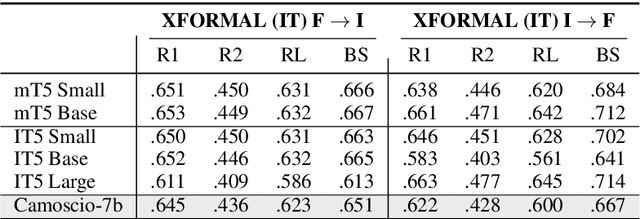
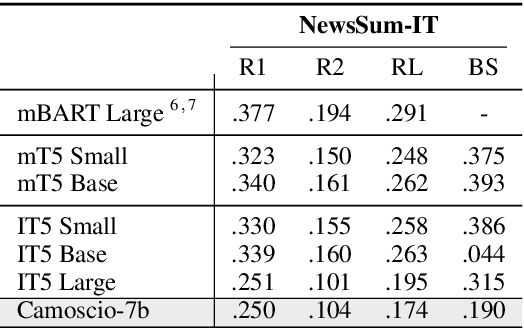
In recent years Large Language Models (LLMs) have increased the state of the art on several natural language processing tasks. However, their accessibility is often limited to paid API services, posing challenges for researchers in conducting extensive investigations. On the other hand, while some open-source models have been proposed by the community, they are typically multilingual and not specifically tailored for the Italian language. In an effort to democratize the available and open resources for the Italian language, in this paper we introduce Camoscio: a language model specifically tuned to follow users' prompts in Italian. Specifically, we finetuned the smallest variant of LLaMA (7b) with LoRA on a corpus of instruction prompts translated to Italian via ChatGPT. Results indicate that the model's zero-shot performance on various downstream tasks in Italian competes favorably with existing models specifically finetuned for those tasks. All the artifacts (code, dataset, model) are released to the community at the following url: https://github.com/teelinsan/camoscio