 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmile van Krieken
ULLER: A Unified Language for Learning and Reasoning
May 01, 2024
The field of neuro-symbolic artificial intelligence (NeSy), which combines learning and reasoning, has recently experienced significant growth. There now are a wide variety of NeSy frameworks, each with its own specific language for expressing background knowledge and how to relate it to neural networks. This heterogeneity hinders accessibility for newcomers and makes comparing different NeSy frameworks challenging. We propose a unified language for NeSy, which we call ULLER, a Unified Language for LEarning and Reasoning. ULLER encompasses a wide variety of settings, while ensuring that knowledge described in it can be used in existing NeSy systems. ULLER has a neuro-symbolic first-order syntax for which we provide example semantics including classical, fuzzy, and probabilistic logics. We believe ULLER is a first step towards making NeSy research more accessible and comparable, paving the way for libraries that streamline training and evaluation across a multitude of semantics, knowledge bases, and NeSy systems.
On the Independence Assumption in Neurosymbolic Learning
Apr 12, 2024State-of-the-art neurosymbolic learning systems use probabilistic reasoning to guide neural networks towards predictions that conform to logical constraints over symbols. Many such systems assume that the probabilities of the considered symbols are conditionally independent given the input to simplify learning and reasoning. We study and criticise this assumption, highlighting how it can hinder optimisation and prevent uncertainty quantification. We prove that loss functions bias conditionally independent neural networks to become overconfident in their predictions. As a result, they are unable to represent uncertainty over multiple valid options. Furthermore, we prove that these loss functions are difficult to optimise: they are non-convex, and their minima are usually highly disconnected. Our theoretical analysis gives the foundation for replacing the conditional independence assumption and designing more expressive neurosymbolic probabilistic models.
BEARS Make Neuro-Symbolic Models Aware of their Reasoning Shortcuts
Feb 19, 2024Neuro-Symbolic (NeSy) predictors that conform to symbolic knowledge - encoding, e.g., safety constraints - can be affected by Reasoning Shortcuts (RSs): They learn concepts consistent with the symbolic knowledge by exploiting unintended semantics. RSs compromise reliability and generalization and, as we show in this paper, they are linked to NeSy models being overconfident about the predicted concepts. Unfortunately, the only trustworthy mitigation strategy requires collecting costly dense supervision over the concepts. Rather than attempting to avoid RSs altogether, we propose to ensure NeSy models are aware of the semantic ambiguity of the concepts they learn, thus enabling their users to identify and distrust low-quality concepts. Starting from three simple desiderata, we derive bears (BE Aware of Reasoning Shortcuts), an ensembling technique that calibrates the model's concept-level confidence without compromising prediction accuracy, thus encouraging NeSy architectures to be uncertain about concepts affected by RSs. We show empirically that bears improves RS-awareness of several state-of-the-art NeSy models, and also facilitates acquiring informative dense annotations for mitigation purposes.
Optimisation in Neurosymbolic Learning Systems
Jan 19, 2024Neurosymbolic AI aims to integrate deep learning with symbolic AI. This integration has many promises, such as decreasing the amount of data required to train a neural network, improving the explainability and interpretability of answers given by models and verifying the correctness of trained systems. We study neurosymbolic learning, where we have both data and background knowledge expressed using symbolic languages. How do we connect the symbolic and neural components to communicate this knowledge? One option is fuzzy reasoning, which studies degrees of truth. For example, being tall is not a binary concept. Instead, probabilistic reasoning studies the probability that something is true or will happen. Our first research question studies how different forms of fuzzy reasoning combine with learning. We find surprising results like a connection to the Raven paradox stating we confirm "ravens are black" when we observe a green apple. In this study, we did not use the background knowledge when we deployed our models after training. In our second research question, we studied how to use background knowledge in deployed models. We developed a new neural network layer based on fuzzy reasoning. Probabilistic reasoning is a natural fit for neural networks, which we usually train to be probabilistic. However, they are expensive to compute and do not scale well to large tasks. In our third research question, we study how to connect probabilistic reasoning with neural networks by sampling to estimate averages, while in the final research question, we study scaling probabilistic neurosymbolic learning to much larger problems than before. Our insight is to train a neural network with synthetic data to predict the result of probabilistic reasoning.
GRAPES: Learning to Sample Graphs for Scalable Graph Neural Networks
Oct 05, 2023Graph neural networks (GNNs) learn the representation of nodes in a graph by aggregating the neighborhood information in various ways. As these networks grow in depth, their receptive field grows exponentially due to the increase in neighborhood sizes, resulting in high memory costs. Graph sampling solves memory issues in GNNs by sampling a small ratio of the nodes in the graph. This way, GNNs can scale to much larger graphs. Most sampling methods focus on fixed sampling heuristics, which may not generalize to different structures or tasks. We introduce GRAPES, an adaptive graph sampling method that learns to identify sets of influential nodes for training a GNN classifier. GRAPES uses a GFlowNet to learn node sampling probabilities given the classification objectives. We evaluate GRAPES across several small- and large-scale graph benchmarks and demonstrate its effectiveness in accuracy and scalability. In contrast to existing sampling methods, GRAPES maintains high accuracy even with small sample sizes and, therefore, can scale to very large graphs. Our code is publicly available at https://github.com/dfdazac/grapes.
IntelliGraphs: Datasets for Benchmarking Knowledge Graph Generation
Jul 19, 2023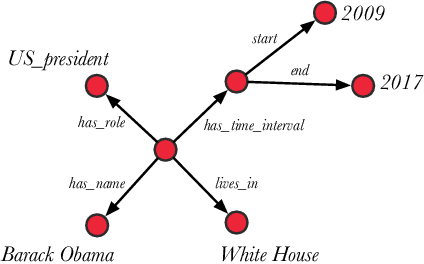
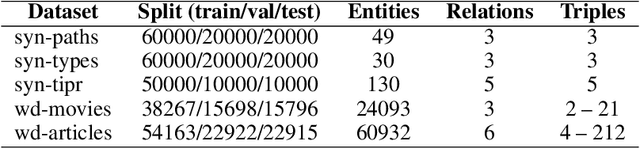
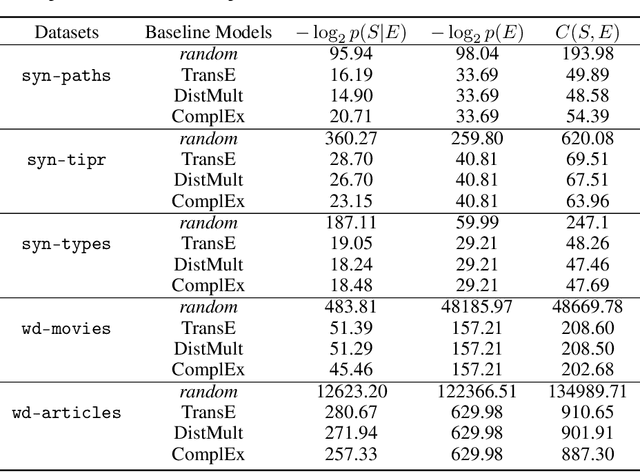
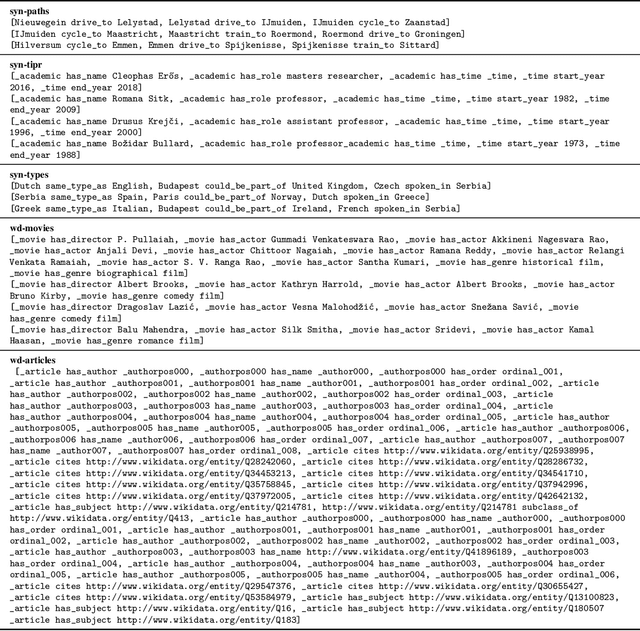
Knowledge Graph Embedding (KGE) models are used to learn continuous representations of entities and relations. A key task in the literature is predicting missing links between entities. However, Knowledge Graphs are not just sets of links but also have semantics underlying their structure. Semantics is crucial in several downstream tasks, such as query answering or reasoning. We introduce the subgraph inference task, where a model has to generate likely and semantically valid subgraphs. We propose IntelliGraphs, a set of five new Knowledge Graph datasets. The IntelliGraphs datasets contain subgraphs with semantics expressed in logical rules for evaluating subgraph inference. We also present the dataset generator that produced the synthetic datasets. We designed four novel baseline models, which include three models based on traditional KGEs. We evaluate their expressiveness and show that these models cannot capture the semantics. We believe this benchmark will encourage the development of machine learning models that emphasize semantic understanding.
A-NeSI: A Scalable Approximate Method for Probabilistic Neurosymbolic Inference
Dec 23, 2022


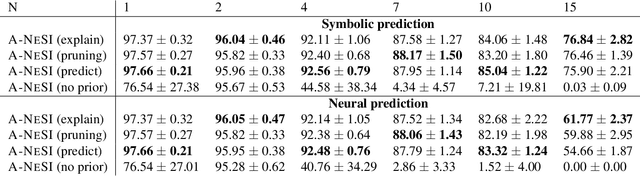
We study the problem of combining neural networks with symbolic reasoning. Recently introduced frameworks for Probabilistic Neurosymbolic Learning (PNL), such as DeepProbLog, perform exponential-time exact inference, limiting the scalability of PNL solutions. We introduce Approximate Neurosymbolic Inference (A-NeSI): a new framework for PNL that uses neural networks for scalable approximate inference. A-NeSI 1) performs approximate inference in polynomial time without changing the semantics of probabilistic logics; 2) is trained using data generated by the background knowledge; 3) can generate symbolic explanations of predictions; and 4) can guarantee the satisfaction of logical constraints at test time, which is vital in safety-critical applications. Our experiments show that A-NeSI is the first end-to-end method to scale the Multi-digit MNISTAdd benchmark to sums of 15 MNIST digits, up from 4 in competing systems. Finally, our experiments show that A-NeSI achieves explainability and safety without a penalty in performance.
Prompting as Probing: Using Language Models for Knowledge Base Construction
Aug 25, 2022
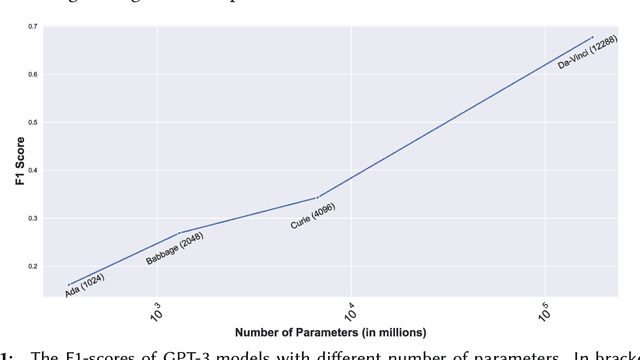

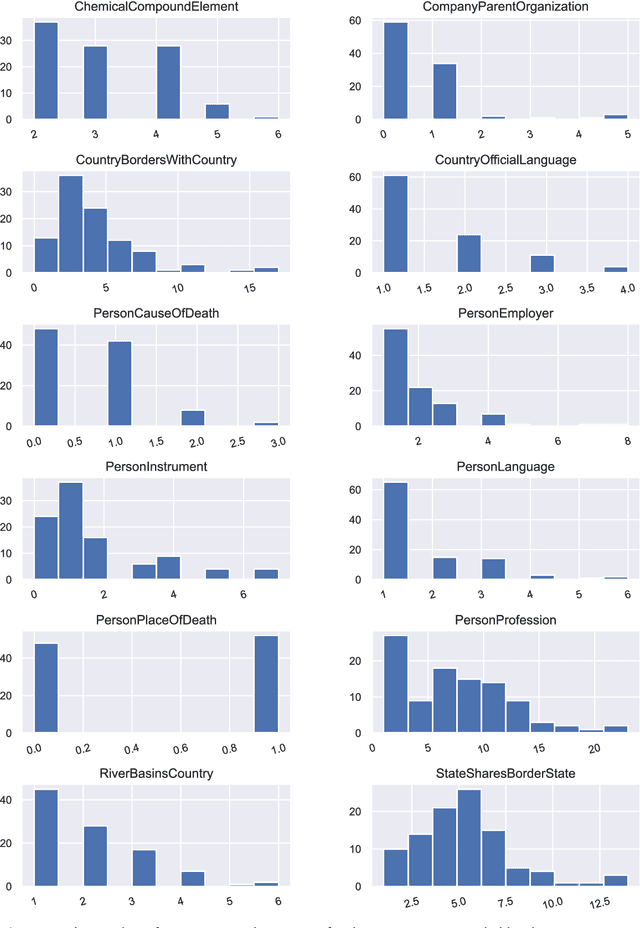
Language Models (LMs) have proven to be useful in various downstream applications, such as summarisation, translation, question answering and text classification. LMs are becoming increasingly important tools in Artificial Intelligence, because of the vast quantity of information they can store. In this work, we present ProP (Prompting as Probing), which utilizes GPT-3, a large Language Model originally proposed by OpenAI in 2020, to perform the task of Knowledge Base Construction (KBC). ProP implements a multi-step approach that combines a variety of prompting techniques to achieve this. Our results show that manual prompt curation is essential, that the LM must be encouraged to give answer sets of variable lengths, in particular including empty answer sets, that true/false questions are a useful device to increase precision on suggestions generated by the LM, that the size of the LM is a crucial factor, and that a dictionary of entity aliases improves the LM score. Our evaluation study indicates that these proposed techniques can substantially enhance the quality of the final predictions: ProP won track 2 of the LM-KBC competition, outperforming the baseline by 36.4 percentage points. Our implementation is available on https://github.com/HEmile/iswc-challenge.
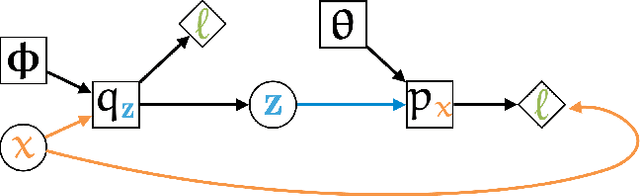
Refining neural network predictions using background knowledge
Jun 10, 2022

Recent work has showed we can use logical background knowledge in learning system to compensate for a lack of labeled training data. Many such methods work by creating a loss function that encodes this knowledge. However, often the logic is discarded after training, even if it is still useful at test-time. Instead, we ensure neural network predictions satisfy the knowledge by refining the predictions with an extra computation step. We introduce differentiable refinement functions that find a corrected prediction close to the original prediction. We study how to effectively and efficiently compute these refinement functions. Using a new algorithm, we combine refinement functions to find refined predictions for logical formulas of any complexity. This algorithm finds optimal refinements on complex SAT formulas in significantly fewer iterations and frequently finds solutions where gradient descent can not.
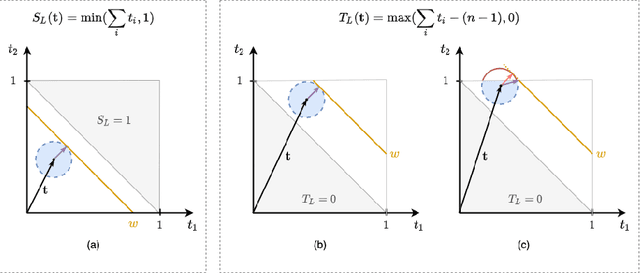
Storchastic: A Framework for General Stochastic Automatic Differentiation
Apr 01, 2021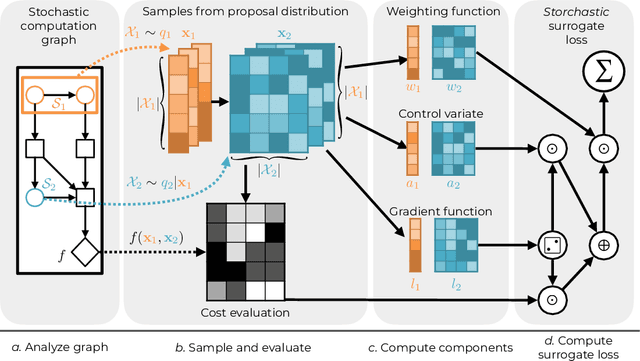

Modelers use automatic differentiation of computation graphs to implement complex Deep Learning models without defining gradient computations. However, modelers often use sampling methods to estimate intractable expectations such as in Reinforcement Learning and Variational Inference. Current methods for estimating gradients through these sampling steps are limited: They are either only applicable to continuous random variables and differentiable functions, or can only use simple but high variance score-function estimators. To overcome these limitations, we introduce Storchastic, a new framework for automatic differentiation of stochastic computation graphs. Storchastic allows the modeler to choose from a wide variety of gradient estimation methods at each sampling step, to optimally reduce the variance of the gradient estimates. Furthermore, Storchastic is provably unbiased for estimation of any-order gradients, and generalizes variance reduction techniques to higher-order gradient estimates. Finally, we implement Storchastic as a PyTorch library.