 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmma Hart
Improving Algorithm-Selection and Performance-Prediction via Learning Discriminating Training Samples
Apr 08, 2024
The choice of input-data used to train algorithm-selection models is recognised as being a critical part of the model success. Recently, feature-free methods for algorithm-selection that use short trajectories obtained from running a solver as input have shown promise. However, it is unclear to what extent these trajectories reliably discriminate between solvers. We propose a meta approach to generating discriminatory trajectories with respect to a portfolio of solvers. The algorithm-configuration tool irace is used to tune the parameters of a simple Simulated Annealing algorithm (SA) to produce trajectories that maximise the performance metrics of ML models trained on this data. We show that when the trajectories obtained from the tuned SA algorithm are used in ML models for algorithm-selection and performance prediction, we obtain significantly improved performance metrics compared to models trained both on raw trajectory data and on exploratory landscape features.
An Investigation of the Factors Influencing Evolutionary Dynamics in the Joint Evolution of Robot Body and Control
Mar 15, 2024



In evolutionary robotics, jointly optimising the design and the controller of robots is a challenging task due to the huge complexity of the solution space formed by the possible combinations of body and controller. We focus on the evolution of robots that can be physically created rather than just simulated, in a rich morphological space that includes a voxel-based chassis, wheels, legs and sensors. On the one hand, this space offers a high degree of liberty in the range of robots that can be produced, while on the other hand introduces a complexity rarely dealt with in previous works relating to matching controllers to designs and in evolving closed-loop control. This is usually addressed by augmenting evolution with a learning algorithm to refine controllers. Although several frameworks exist, few have studied the role of the \textit{evolutionary dynamics} of the intertwined `evolution+learning' processes in realising high-performing robots. We conduct an in-depth study of the factors that influence these dynamics, specifically: synchronous vs asynchronous evolution; the mechanism for replacing parents with offspring, and rewarding goal-based fitness vs novelty via selection. Results show that asynchronicity combined with goal-based selection and a `replace worst' strategy results in the highest performance.
Understanding fitness landscapes in morpho-evolution via local optima networks
Feb 12, 2024Morpho-evolution (ME) refers to the simultaneous optimisation of a robot's design and controller to maximise performance given a task and environment. Many genetic encodings have been proposed which are capable of representing design and control. Previous research has provided empirical comparisons between encodings in terms of their performance with respect to an objective function and the diversity of designs that are evaluated, however there has been no attempt to explain the observed findings. We address this by applying Local Optima Network (LON) analysis to investigate the structure of the fitness landscapes induced by three different encodings when evolving a robot for a locomotion task, shedding new light on the ease by which different fitness landscapes can be traversed by a search process. This is the first time LON analysis has been applied in the field of ME despite its popularity in combinatorial optimisation domains; the findings will facilitate design of new algorithms or operators that are customised to ME landscapes in the future.
On the Utility of Probing Trajectories for Algorithm-Selection
Jan 23, 2024Machine-learning approaches to algorithm-selection typically take data describing an instance as input. Input data can take the form of features derived from the instance description or fitness landscape, or can be a direct representation of the instance itself, i.e. an image or textual description. Regardless of the choice of input, there is an implicit assumption that instances that are similar will elicit similar performance from algorithm, and that a model is capable of learning this relationship. We argue that viewing algorithm-selection purely from an instance perspective can be misleading as it fails to account for how an algorithm `views' similarity between instances. We propose a novel `algorithm-centric' method for describing instances that can be used to train models for algorithm-selection: specifically, we use short probing trajectories calculated by applying a solver to an instance for a very short period of time. The approach is demonstrated to be promising, providing comparable or better results to computationally expensive landscape-based feature-based approaches. Furthermore, projecting the trajectories into a 2-dimensional space illustrates that functions that are similar from an algorithm-perspective do not necessarily correspond to the accepted categorisation of these functions from a human perspective.
Generalized Early Stopping in Evolutionary Direct Policy Search
Aug 07, 2023



Lengthy evaluation times are common in many optimization problems such as direct policy search tasks, especially when they involve conducting evaluations in the physical world, e.g. in robotics applications. Often, when evaluating a solution over a fixed time period, it becomes clear that the objective value will not increase with additional computation time (for example, when a two-wheeled robot continuously spins on the spot). In such cases, it makes sense to stop the evaluation early to save computation time. However, most approaches to stop the evaluation are problem-specific and need to be specifically designed for the task at hand. Therefore, we propose an early stopping method for direct policy search. The proposed method only looks at the objective value at each time step and requires no problem-specific knowledge. We test the introduced stopping criterion in five direct policy search environments drawn from games, robotics, and classic control domains, and show that it can save up to 75% of the computation time. We also compare it with problem-specific stopping criteria and demonstrate that it performs comparably while being more generally applicable.
To Switch or not to Switch: Predicting the Benefit of Switching between Algorithms based on Trajectory Features
Feb 17, 2023



Dynamic algorithm selection aims to exploit the complementarity of multiple optimization algorithms by switching between them during the search. While these kinds of dynamic algorithms have been shown to have potential to outperform their component algorithms, it is still unclear how this potential can best be realized. One promising approach is to make use of landscape features to enable a per-run trajectory-based switch. Here, the samples seen by the first algorithm are used to create a set of features which describe the landscape from the perspective of the algorithm. These features are then used to predict what algorithm to switch to. In this work, we extend this per-run trajectory-based approach to consider a wide variety of potential points at which to perform the switch. We show that using a sliding window to capture the local landscape features contains information which can be used to predict whether a switch at that point would be beneficial to future performance. By analyzing the resulting models, we identify what features are most important to these predictions. Finally, by evaluating the importance of features and comparing these values between multiple algorithms, we show clear differences in the way the second algorithm interacts with the local landscape features found before the switch.
Automated Algorithm Selection: from Feature-Based to Feature-Free Approaches
Mar 24, 2022



We propose a novel technique for algorithm-selection, applicable to optimisation domains in which there is implicit sequential information encapsulated in the data, e.g., in online bin-packing. Specifically we train two types of recurrent neural networks to predict a packing heuristic in online bin-packing, selecting from four well-known heuristics. As input, the RNN methods only use the sequence of item-sizes. This contrasts to typical approaches to algorithm-selection which require a model to be trained using domain-specific instance features that need to be first derived from the input data. The RNN approaches are shown to be capable of achieving within 5% of the oracle performance on between 80.88% to 97.63% of the instances, depending on the dataset. They are also shown to outperform classical machine learning models trained using derived features. Finally, we hypothesise that the proposed methods perform well when the instances exhibit some implicit structure that results in discriminatory performance with respect to a set of heuristics. We test this hypothesis by generating fourteen new datasets with increasing levels of structure, and show that there is a critical threshold of structure required before algorithm-selection delivers benefit.
Augmenting Novelty Search with a Surrogate Model to Engineer Meta-Diversity in Ensembles of Classifiers
Feb 08, 2022



Using Neuroevolution combined with Novelty Search to promote behavioural diversity is capable of constructing high-performing ensembles for classification. However, using gradient descent to train evolved architectures during the search can be computationally prohibitive. Here we propose a method to overcome this limitation by using a surrogate model which estimates the behavioural distance between two neural network architectures required to calculate the sparseness term in Novelty Search. We demonstrate a speedup of 10 times over previous work and significantly improve on previous reported results on three benchmark datasets from Computer Vision -- CIFAR-10, CIFAR-100, and SVHN. This results from the expanded architecture search space facilitated by using a surrogate. Our method represents an improved paradigm for implementing horizontal scaling of learning algorithms by making an explicit search for diversity considerably more tractable for the same bounded resources.
Comparison of atlas-based and neural-network-based semantic segmentation for DENSE MRI images
Sep 29, 2021



Two segmentation methods, one atlas-based and one neural-network-based, were compared to see how well they can each automatically segment the brain stem and cerebellum in Displacement Encoding with Stimulated Echoes Magnetic Resonance Imaging (DENSE-MRI) data. The segmentation is a pre-requisite for estimating the average displacements in these regions, which have recently been proposed as biomarkers in the diagnosis of Chiari Malformation type I (CMI). In numerical experiments, the segmentations of both methods were similar to manual segmentations provided by trained experts. It was found that, overall, the neural-network-based method alone produced more accurate segmentations than the atlas-based method did alone, but that a combination of the two methods -- in which the atlas-based method is used for the segmentation of the brain stem and the neural-network is used for the segmentation of the cerebellum -- may be the most successful.
Morpho-evolution with learning using a controller archive as an inheritance mechanism
Apr 09, 2021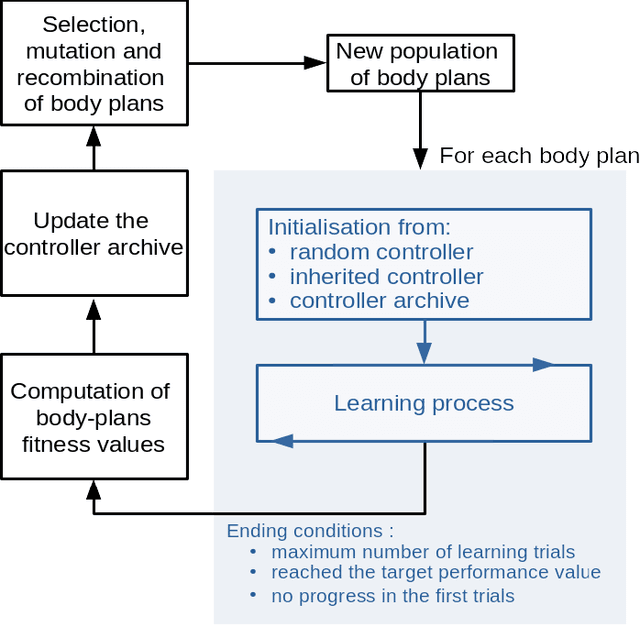
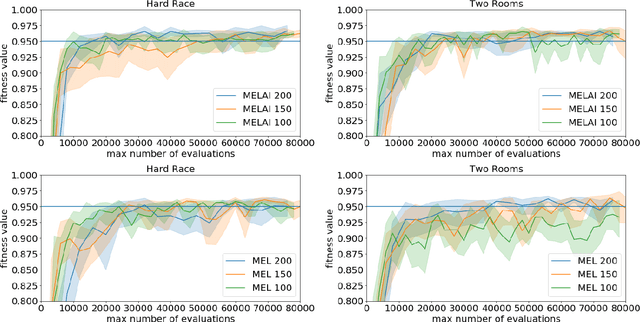
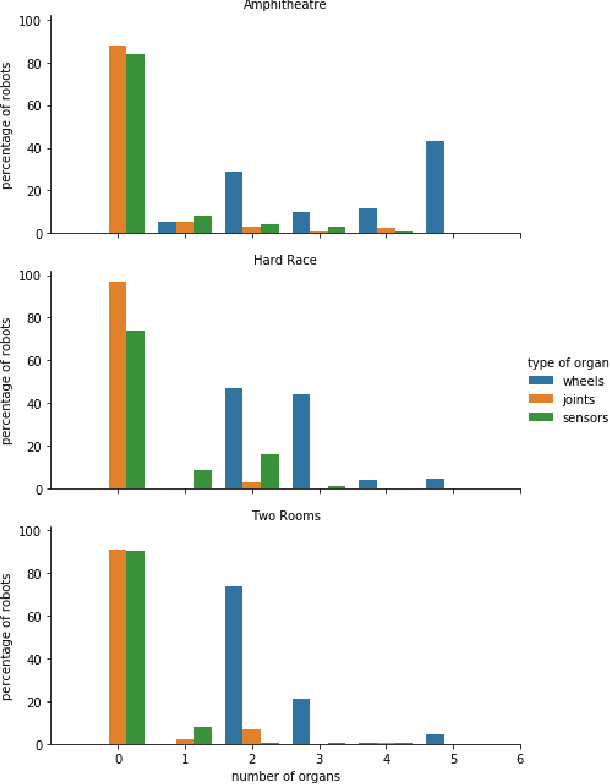
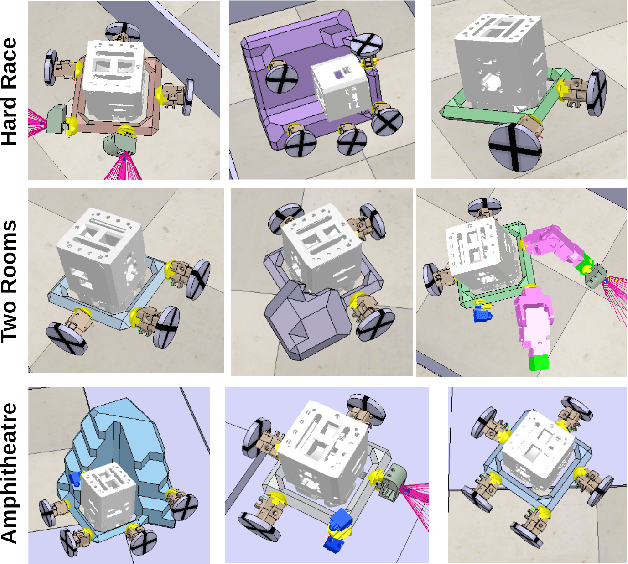
In evolutionary robotics, several approaches have been shown to be capable of the joint optimisation of body-plans and controllers by either using only evolution or combining evolution and learning. When working in rich morphological spaces, it is common for offspring to have body-plans that are very different from either of their parents, which can cause difficulties with respect to inheriting a suitable controller. To address this, we propose a framework that combines an evolutionary algorithm to generate body-plans and a learning algorithm to optimise the parameters of a neural controller where the topology of this controller is created once the body-plan of each offspring body-plan is generated. The key novelty of the approach is to add an external archive for storing learned controllers that map to explicit `types' of robots (where this is defined with respect the features of the body-plan). By inheriting an appropriate controller from the archive rather than learning from a randomly initialised one, we show that both the speed and magnitude of learning increases over time when compared to an approach that starts from scratch, using three different test-beds. The framework also provides new insights into the complex interactions between evolution and learning, and the role of morphological intelligence in robot design.