 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEric Moulines
Divide-and-Conquer Posterior Sampling for Denoising Diffusion Priors
Mar 18, 2024

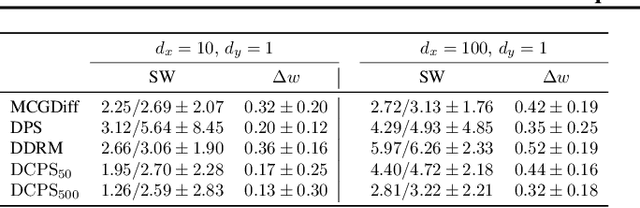
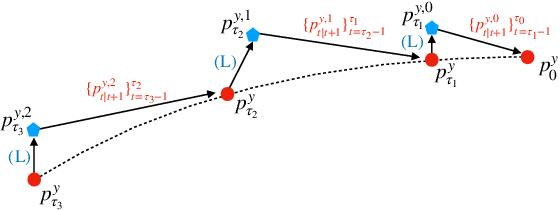

Interest in the use of Denoising Diffusion Models (DDM) as priors for solving inverse Bayesian problems has recently increased significantly. However, sampling from the resulting posterior distribution poses a challenge. To solve this problem, previous works have proposed approximations to bias the drift term of the diffusion. In this work, we take a different approach and utilize the specific structure of the DDM prior to define a set of intermediate and simpler posterior sampling problems, resulting in a lower approximation error compared to previous methods. We empirically demonstrate the reconstruction capability of our method for general linear inverse problems using synthetic examples and various image restoration tasks.
Incentivized Learning in Principal-Agent Bandit Games
Mar 06, 2024
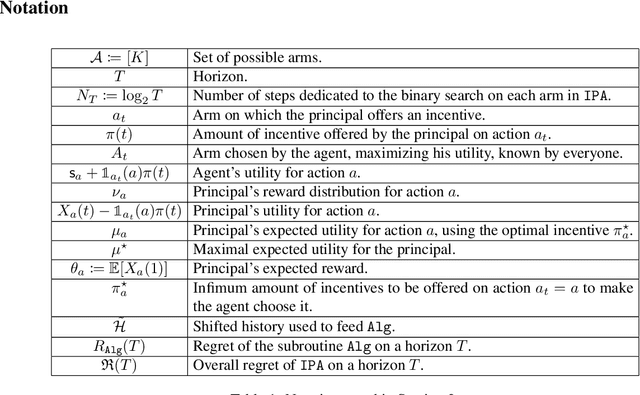
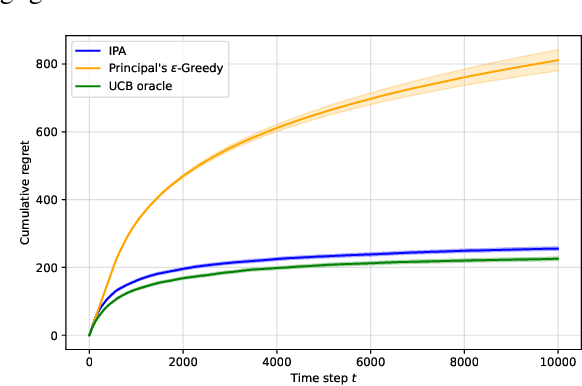
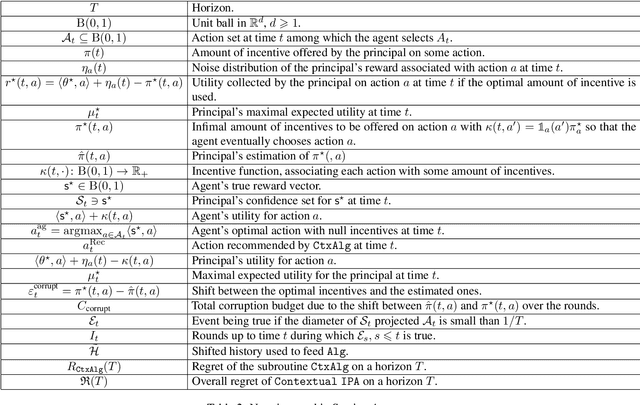
This work considers a repeated principal-agent bandit game, where the principal can only interact with her environment through the agent. The principal and the agent have misaligned objectives and the choice of action is only left to the agent. However, the principal can influence the agent's decisions by offering incentives which add up to his rewards. The principal aims to iteratively learn an incentive policy to maximize her own total utility. This framework extends usual bandit problems and is motivated by several practical applications, such as healthcare or ecological taxation, where traditionally used mechanism design theories often overlook the learning aspect of the problem. We present nearly optimal (with respect to a horizon $T$) learning algorithms for the principal's regret in both multi-armed and linear contextual settings. Finally, we support our theoretical guarantees through numerical experiments.
SCAFFLSA: Quantifying and Eliminating Heterogeneity Bias in Federated Linear Stochastic Approximation and Temporal Difference Learning
Feb 06, 2024In this paper, we perform a non-asymptotic analysis of the federated linear stochastic approximation (FedLSA) algorithm. We explicitly quantify the bias introduced by local training with heterogeneous agents, and investigate the sample complexity of the algorithm. We show that the communication complexity of FedLSA scales polynomially with the desired precision $\epsilon$, which limits the benefits of federation. To overcome this, we propose SCAFFLSA, a novel variant of FedLSA, that uses control variates to correct the bias of local training, and prove its convergence without assumptions on statistical heterogeneity. We apply the proposed methodology to federated temporal difference learning with linear function approximation, and analyze the corresponding complexity improvements.
Efficient Conformal Prediction under Data Heterogeneity
Dec 25, 2023Conformal Prediction (CP) stands out as a robust framework for uncertainty quantification, which is crucial for ensuring the reliability of predictions. However, common CP methods heavily rely on data exchangeability, a condition often violated in practice. Existing approaches for tackling non-exchangeability lead to methods that are not computable beyond the simplest examples. This work introduces a new efficient approach to CP that produces provably valid confidence sets for fairly general non-exchangeable data distributions. We illustrate the general theory with applications to the challenging setting of federated learning under data heterogeneity between agents. Our method allows constructing provably valid personalized prediction sets for agents in a fully federated way. The effectiveness of the proposed method is demonstrated in a series of experiments on real-world datasets.
Model-free Posterior Sampling via Learning Rate Randomization
Oct 27, 2023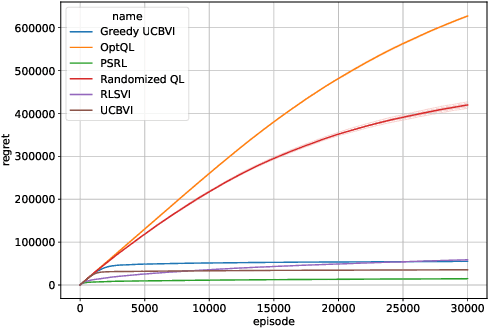
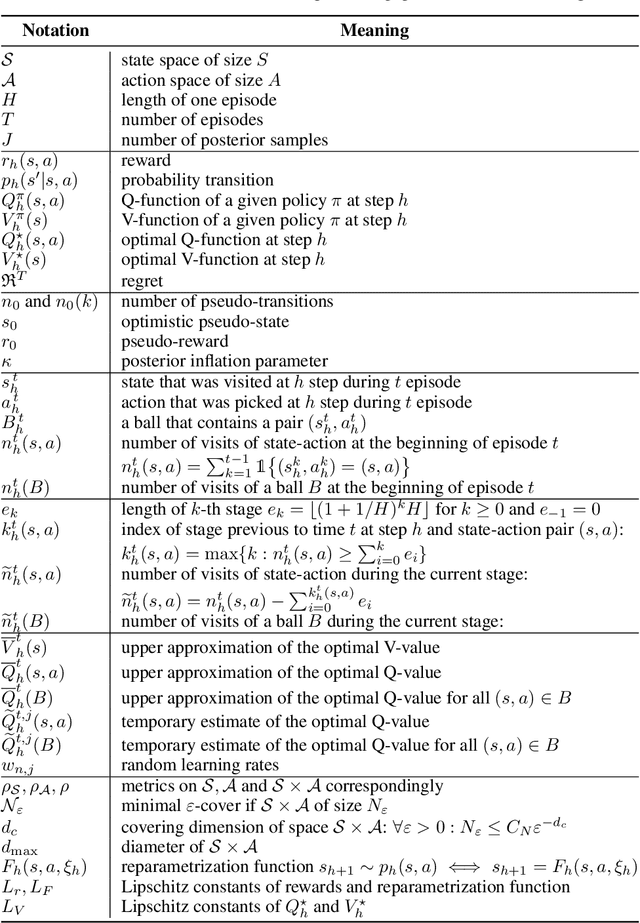
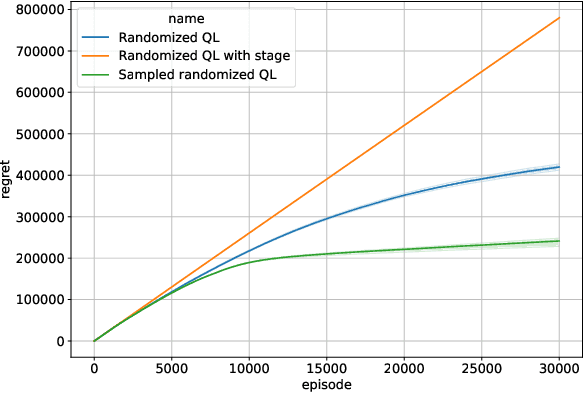

In this paper, we introduce Randomized Q-learning (RandQL), a novel randomized model-free algorithm for regret minimization in episodic Markov Decision Processes (MDPs). To the best of our knowledge, RandQL is the first tractable model-free posterior sampling-based algorithm. We analyze the performance of RandQL in both tabular and non-tabular metric space settings. In tabular MDPs, RandQL achieves a regret bound of order $\widetilde{\mathcal{O}}(\sqrt{H^{5}SAT})$, where $H$ is the planning horizon, $S$ is the number of states, $A$ is the number of actions, and $T$ is the number of episodes. For a metric state-action space, RandQL enjoys a regret bound of order $\widetilde{\mathcal{O}}(H^{5/2} T^{(d_z+1)/(d_z+2)})$, where $d_z$ denotes the zooming dimension. Notably, RandQL achieves optimistic exploration without using bonuses, relying instead on a novel idea of learning rate randomization. Our empirical study shows that RandQL outperforms existing approaches on baseline exploration environments.
Demonstration-Regularized RL
Oct 26, 2023Incorporating expert demonstrations has empirically helped to improve the sample efficiency of reinforcement learning (RL). This paper quantifies theoretically to what extent this extra information reduces RL's sample complexity. In particular, we study the demonstration-regularized reinforcement learning that leverages the expert demonstrations by KL-regularization for a policy learned by behavior cloning. Our findings reveal that using $N^{\mathrm{E}}$ expert demonstrations enables the identification of an optimal policy at a sample complexity of order $\widetilde{\mathcal{O}}(\mathrm{Poly}(S,A,H)/(\varepsilon^2 N^{\mathrm{E}}))$ in finite and $\widetilde{\mathcal{O}}(\mathrm{Poly}(d,H)/(\varepsilon^2 N^{\mathrm{E}}))$ in linear Markov decision processes, where $\varepsilon$ is the target precision, $H$ the horizon, $A$ the number of action, $S$ the number of states in the finite case and $d$ the dimension of the feature space in the linear case. As a by-product, we provide tight convergence guarantees for the behaviour cloning procedure under general assumptions on the policy classes. Additionally, we establish that demonstration-regularized methods are provably efficient for reinforcement learning from human feedback (RLHF). In this respect, we provide theoretical evidence showing the benefits of KL-regularization for RLHF in tabular and linear MDPs. Interestingly, we avoid pessimism injection by employing computationally feasible regularization to handle reward estimation uncertainty, thus setting our approach apart from the prior works.
Finite-Sample Analysis of the Temporal Difference Learning
Oct 22, 2023In this paper we consider the problem of obtaining sharp bounds for the performance of temporal difference (TD) methods with linear functional approximation for policy evaluation in discounted Markov Decision Processes. We show that a simple algorithm with a universal and instance-independent step size together with Polyak-Ruppert tail averaging is sufficient to obtain near-optimal variance and bias terms. We also provide the respective sample complexity bounds. Our proof technique is based on refined error bounds for linear stochastic approximation together with the novel stability result for the product of random matrices that arise from the TD-type recurrence.
Deep Reinforcement Learning Algorithms for Hybrid V2X Communication: A Benchmarking Study
Oct 04, 2023In today's era, autonomous vehicles demand a safety level on par with aircraft. Taking a cue from the aerospace industry, which relies on redundancy to achieve high reliability, the automotive sector can also leverage this concept by building redundancy in V2X (Vehicle-to-Everything) technologies. Given the current lack of reliable V2X technologies, this idea is particularly promising. By deploying multiple RATs (Radio Access Technologies) in parallel, the ongoing debate over the standard technology for future vehicles can be put to rest. However, coordinating multiple communication technologies is a complex task due to dynamic, time-varying channels and varying traffic conditions. This paper addresses the vertical handover problem in V2X using Deep Reinforcement Learning (DRL) algorithms. The goal is to assist vehicles in selecting the most appropriate V2X technology (DSRC/V-VLC) in a serpentine environment. The results show that the benchmarked algorithms outperform the current state-of-the-art approaches in terms of redundancy and usage rate of V-VLC headlights. This result is a significant reduction in communication costs while maintaining a high level of reliability. These results provide strong evidence for integrating advanced DRL decision mechanisms into the architecture as a promising approach to solving the vertical handover problem in V2X.
Monte Carlo guided Diffusion for Bayesian linear inverse problems
Aug 15, 2023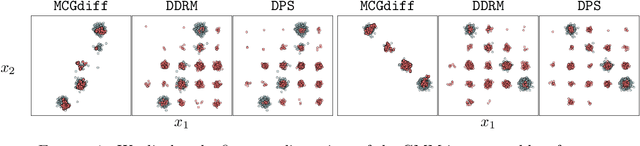
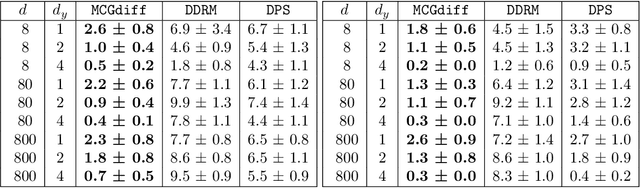


Ill-posed linear inverse problems that combine knowledge of the forward measurement model with prior models arise frequently in various applications, from computational photography to medical imaging. Recent research has focused on solving these problems with score-based generative models (SGMs) that produce perceptually plausible images, especially in inpainting problems. In this study, we exploit the particular structure of the prior defined in the SGM to formulate recovery in a Bayesian framework as a Feynman--Kac model adapted from the forward diffusion model used to construct score-based diffusion. To solve this Feynman--Kac problem, we propose the use of Sequential Monte Carlo methods. The proposed algorithm, MCGdiff, is shown to be theoretically grounded and we provide numerical simulations showing that it outperforms competing baselines when dealing with ill-posed inverse problems.
Conformal Prediction for Federated Uncertainty Quantification Under Label Shift
Jun 08, 2023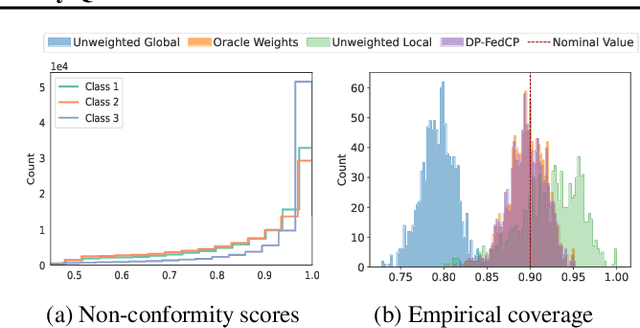
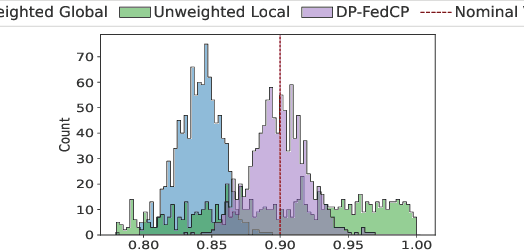
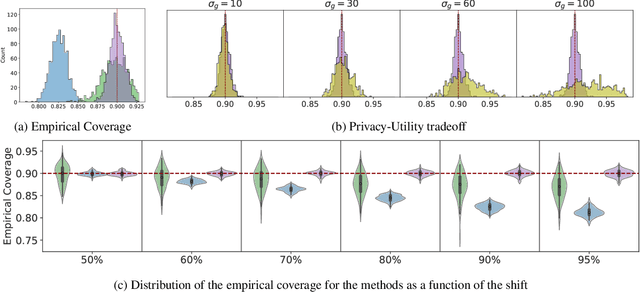
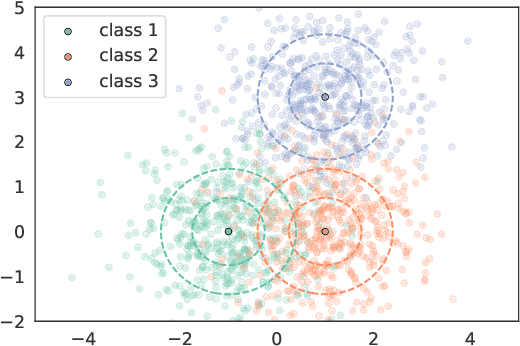
Federated Learning (FL) is a machine learning framework where many clients collaboratively train models while keeping the training data decentralized. Despite recent advances in FL, the uncertainty quantification topic (UQ) remains partially addressed. Among UQ methods, conformal prediction (CP) approaches provides distribution-free guarantees under minimal assumptions. We develop a new federated conformal prediction method based on quantile regression and take into account privacy constraints. This method takes advantage of importance weighting to effectively address the label shift between agents and provides theoretical guarantees for both valid coverage of the prediction sets and differential privacy. Extensive experimental studies demonstrate that this method outperforms current competitors.