 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEric Yang
Event Detection from Social Media for Epidemic Prediction
Apr 02, 2024
Social media is an easy-to-access platform providing timely updates about societal trends and events. Discussions regarding epidemic-related events such as infections, symptoms, and social interactions can be crucial for informing policymaking during epidemic outbreaks. In our work, we pioneer exploiting Event Detection (ED) for better preparedness and early warnings of any upcoming epidemic by developing a framework to extract and analyze epidemic-related events from social media posts. To this end, we curate an epidemic event ontology comprising seven disease-agnostic event types and construct a Twitter dataset SPEED with human-annotated events focused on the COVID-19 pandemic. Experimentation reveals how ED models trained on COVID-based SPEED can effectively detect epidemic events for three unseen epidemics of Monkeypox, Zika, and Dengue; while models trained on existing ED datasets fail miserably. Furthermore, we show that reporting sharp increases in the extracted events by our framework can provide warnings 4-9 weeks earlier than the WHO epidemic declaration for Monkeypox. This utility of our framework lays the foundations for better preparedness against emerging epidemics.
GloFlow: Global Image Alignment for Creation of Whole Slide Images for Pathology from Video
Nov 12, 2020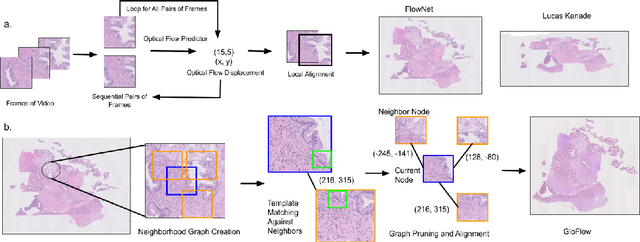
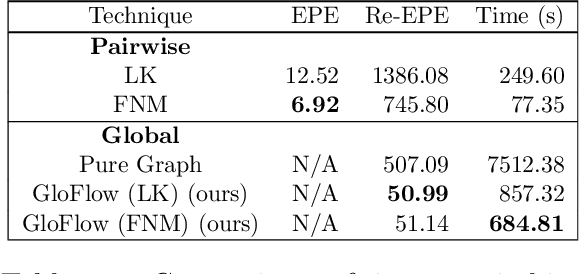
The application of deep learning to pathology assumes the existence of digital whole slide images of pathology slides. However, slide digitization is bottlenecked by the high cost of precise motor stages in slide scanners that are needed for position information used for slide stitching. We propose GloFlow, a two-stage method for creating a whole slide image using optical flow-based image registration with global alignment using a computationally tractable graph-pruning approach. In the first stage, we train an optical flow predictor to predict pairwise translations between successive video frames to approximate a stitch. In the second stage, this approximate stitch is used to create a neighborhood graph to produce a corrected stitch. On a simulated dataset of video scans of WSIs, we find that our method outperforms known approaches to slide-stitching, and stitches WSIs resembling those produced by slide scanners.
The NVIDIA PilotNet Experiments
Oct 17, 2020
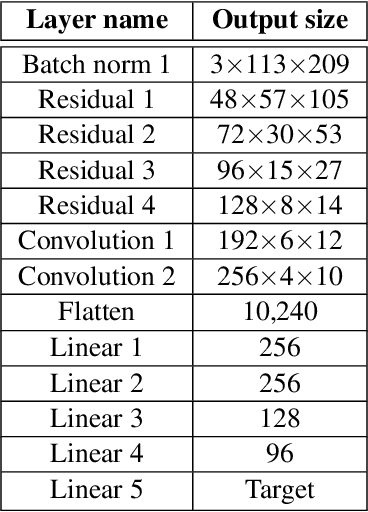


Four years ago, an experimental system known as PilotNet became the first NVIDIA system to steer an autonomous car along a roadway. This system represents a departure from the classical approach for self-driving in which the process is manually decomposed into a series of modules, each performing a different task. In PilotNet, on the other hand, a single deep neural network (DNN) takes pixels as input and produces a desired vehicle trajectory as output; there are no distinct internal modules connected by human-designed interfaces. We believe that handcrafted interfaces ultimately limit performance by restricting information flow through the system and that a learned approach, in combination with other artificial intelligence systems that add redundancy, will lead to better overall performing systems. We continue to conduct research toward that goal. This document describes the PilotNet lane-keeping effort, carried out over the past five years by our NVIDIA PilotNet group in Holmdel, New Jersey. Here we present a snapshot of system status in mid-2020 and highlight some of the work done by the PilotNet group.