 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErnest K. Ryu
Simple Drop-in LoRA Conditioning on Attention Layers Will Improve Your Diffusion Model
May 07, 2024
Current state-of-the-art diffusion models employ U-Net architectures containing convolutional and (qkv) self-attention layers. The U-Net processes images while being conditioned on the time embedding input for each sampling step and the class or caption embedding input corresponding to the desired conditional generation. Such conditioning involves scale-and-shift operations to the convolutional layers but does not directly affect the attention layers. While these standard architectural choices are certainly effective, not conditioning the attention layers feels arbitrary and potentially suboptimal. In this work, we show that simply adding LoRA conditioning to the attention layers without changing or tuning the other parts of the U-Net architecture improves the image generation quality. For example, a drop-in addition of LoRA conditioning to EDM diffusion model yields FID scores of 1.91/1.75 for unconditional and class-conditional CIFAR-10 generation, improving upon the baseline of 1.97/1.79.
LoRA Training in the NTK Regime has No Spurious Local Minima
Feb 19, 2024Low-rank adaptation (LoRA) has become the standard approach for parameter-efficient fine-tuning of large language models (LLM), but our theoretical understanding of LoRA has been limited. In this work, we theoretically analyze LoRA fine-tuning in the neural tangent kernel (NTK) regime with $N$ data points, showing: (i) full fine-tuning (without LoRA) admits a low-rank solution of rank $r\lesssim \sqrt{N}$; (ii) using LoRA with rank $r\gtrsim \sqrt{N}$ eliminates spurious local minima, allowing gradient descent to find the low-rank solutions; (iii) the low-rank solution found using LoRA generalizes well.
Image Clustering Conditioned on Text Criteria
Oct 30, 2023
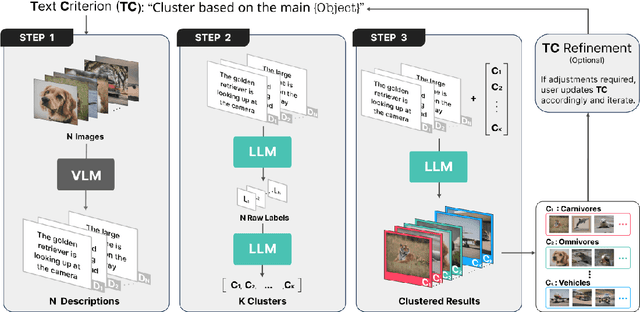


Classical clustering methods do not provide users with direct control of the clustering results, and the clustering results may not be consistent with the relevant criterion that a user has in mind. In this work, we present a new methodology for performing image clustering based on user-specified text criteria by leveraging modern vision-language models and large language models. We call our method Image Clustering Conditioned on Text Criteria (IC$|$TC), and it represents a different paradigm of image clustering. IC$|$TC requires a minimal and practical degree of human intervention and grants the user significant control over the clustering results in return. Our experiments show that IC$|$TC can effectively cluster images with various criteria, such as human action, physical location, or the person's mood, while significantly outperforming baselines.
Censored Sampling of Diffusion Models Using 3 Minutes of Human Feedback
Jul 06, 2023



Diffusion models have recently shown remarkable success in high-quality image generation. Sometimes, however, a pre-trained diffusion model exhibits partial misalignment in the sense that the model can generate good images, but it sometimes outputs undesirable images. If so, we simply need to prevent the generation of the bad images, and we call this task censoring. In this work, we present censored generation with a pre-trained diffusion model using a reward model trained on minimal human feedback. We show that censoring can be accomplished with extreme human feedback efficiency and that labels generated with a mere few minutes of human feedback are sufficient. Code available at: https://github.com/tetrzim/diffusion-human-feedback.
Accelerating Value Iteration with Anchoring
May 26, 2023Value Iteration (VI) is foundational to the theory and practice of modern reinforcement learning, and it is known to converge at a $\mathcal{O}(\gamma^k)$-rate, where $\gamma$ is the discount factor. Surprisingly, however, the optimal rate for the VI setup was not known, and finding a general acceleration mechanism has been an open problem. In this paper, we present the first accelerated VI for both the Bellman consistency and optimality operators. Our method, called Anc-VI, is based on an \emph{anchoring} mechanism (distinct from Nesterov's acceleration), and it reduces the Bellman error faster than standard VI. In particular, Anc-VI exhibits a $\mathcal{O}(1/k)$-rate for $\gamma\approx 1$ or even $\gamma=1$, while standard VI has rate $\mathcal{O}(1)$ for $\gamma\ge 1-1/k$, where $k$ is the iteration count. We also provide a complexity lower bound matching the upper bound up to a constant factor of $4$, thereby establishing optimality of the accelerated rate of Anc-VI. Finally, we show that the anchoring mechanism provides the same benefit in the approximate VI and Gauss--Seidel VI setups as well.
Rotation and Translation Invariant Representation Learning with Implicit Neural Representations
Apr 27, 2023



In many computer vision applications, images are acquired with arbitrary or random rotations and translations, and in such setups, it is desirable to obtain semantic representations disentangled from the image orientation. Examples of such applications include semiconductor wafer defect inspection, plankton microscope images, and inference on single-particle cryo-electron microscopy (cryo-EM) micro-graphs. In this work, we propose Invariant Representation Learning with Implicit Neural Representation (IRL-INR), which uses an implicit neural representation (INR) with a hypernetwork to obtain semantic representations disentangled from the orientation of the image. We show that IRL-INR can effectively learn disentangled semantic representations on more complex images compared to those considered in prior works and show that these semantic representations synergize well with SCAN to produce state-of-the-art unsupervised clustering results.
Robust Probabilistic Time Series Forecasting
Feb 24, 2022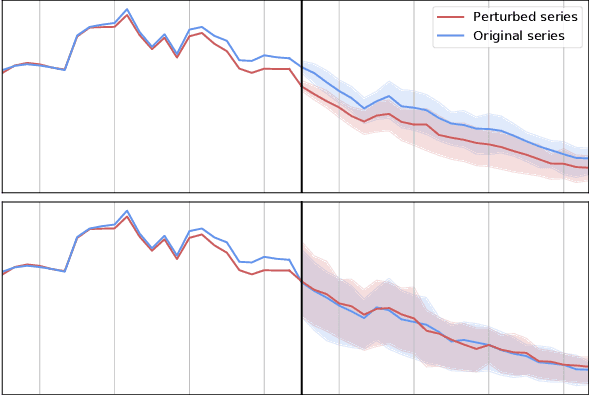



Probabilistic time series forecasting has played critical role in decision-making processes due to its capability to quantify uncertainties. Deep forecasting models, however, could be prone to input perturbations, and the notion of such perturbations, together with that of robustness, has not even been completely established in the regime of probabilistic forecasting. In this work, we propose a framework for robust probabilistic time series forecasting. First, we generalize the concept of adversarial input perturbations, based on which we formulate the concept of robustness in terms of bounded Wasserstein deviation. Then we extend the randomized smoothing technique to attain robust probabilistic forecasters with theoretical robustness certificates against certain classes of adversarial perturbations. Lastly, extensive experiments demonstrate that our methods are empirically effective in enhancing the forecast quality under additive adversarial attacks and forecast consistency under supplement of noisy observations.
Neural Tangent Kernel Analysis of Deep Narrow Neural Networks
Feb 07, 2022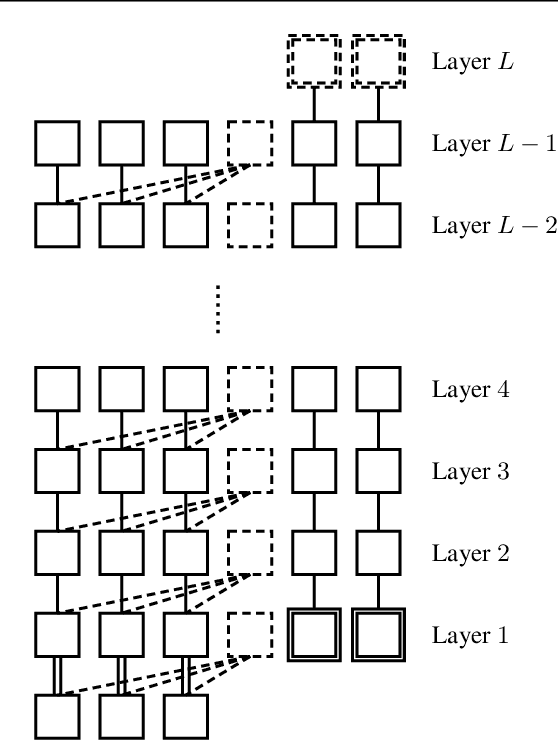


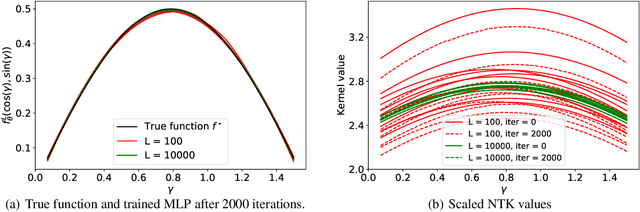
The tremendous recent progress in analyzing the training dynamics of overparameterized neural networks has primarily focused on wide networks and therefore does not sufficiently address the role of depth in deep learning. In this work, we present the first trainability guarantee of infinitely deep but narrow neural networks. We study the infinite-depth limit of a multilayer perceptron (MLP) with a specific initialization and establish a trainability guarantee using the NTK theory. We then extend the analysis to an infinitely deep convolutional neural network (CNN) and perform brief experiments
WGAN with an Infinitely Wide Generator Has No Spurious Stationary Points
Feb 15, 2021



Generative adversarial networks (GAN) are a widely used class of deep generative models, but their minimax training dynamics are not understood very well. In this work, we show that GANs with a 2-layer infinite-width generator and a 2-layer finite-width discriminator trained with stochastic gradient ascent-descent have no spurious stationary points. We then show that when the width of the generator is finite but wide, there are no spurious stationary points within a ball whose radius becomes arbitrarily large (to cover the entire parameter space) as the width goes to infinity.
ODE Analysis of Stochastic Gradient Methods with Optimism and Anchoring for Minimax Problems and GANs
Jun 06, 2019



Despite remarkable empirical success, the training dynamics of generative adversarial networks (GAN), which involves solving a minimax game using stochastic gradients, is still poorly understood. In this work, we analyze last-iterate convergence of simultaneous gradient descent (simGD) and its variants under the assumption of convex-concavity, guided by a continuous-time analysis with differential equations. First, we show that simGD, as is, converges with stochastic sub-gradients under strict convexity in the primal variable. Second, we generalize optimistic simGD to accommodate an optimism rate separate from the learning rate and show its convergence with full gradients. Finally, we present anchored simGD, a new method, and show convergence with stochastic subgradients.