 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEugene Ndiaye
Conformal Prediction via Regression-as-Classification
Apr 12, 2024
Conformal prediction (CP) for regression can be challenging, especially when the output distribution is heteroscedastic, multimodal, or skewed. Some of the issues can be addressed by estimating a distribution over the output, but in reality, such approaches can be sensitive to estimation error and yield unstable intervals.~Here, we circumvent the challenges by converting regression to a classification problem and then use CP for classification to obtain CP sets for regression.~To preserve the ordering of the continuous-output space, we design a new loss function and make necessary modifications to the CP classification techniques.~Empirical results on many benchmarks shows that this simple approach gives surprisingly good results on many practical problems.
* International Conference of Learning Representations 2024
Careful with that Scalpel: Improving Gradient Surgery with an EMA
Feb 05, 2024Beyond minimizing a single training loss, many deep learning estimation pipelines rely on an auxiliary objective to quantify and encourage desirable properties of the model (e.g. performance on another dataset, robustness, agreement with a prior). Although the simplest approach to incorporating an auxiliary loss is to sum it with the training loss as a regularizer, recent works have shown that one can improve performance by blending the gradients beyond a simple sum; this is known as gradient surgery. We cast the problem as a constrained minimization problem where the auxiliary objective is minimized among the set of minimizers of the training loss. To solve this bilevel problem, we follow a parameter update direction that combines the training loss gradient and the orthogonal projection of the auxiliary gradient to the training gradient. In a setting where gradients come from mini-batches, we explain how, using a moving average of the training loss gradients, we can carefully maintain this critical orthogonality property. We demonstrate that our method, Bloop, can lead to much better performances on NLP and vision experiments than other gradient surgery methods without EMA.
Finite Sample Confidence Regions for Linear Regression Parameters Using Arbitrary Predictors
Jan 27, 2024We explore a novel methodology for constructing confidence regions for parameters of linear models, using predictions from any arbitrary predictor. Our framework requires minimal assumptions on the noise and can be extended to functions deviating from strict linearity up to some adjustable threshold, thereby accommodating a comprehensive and pragmatically relevant set of functions. The derived confidence regions can be cast as constraints within a Mixed Integer Linear Programming framework, enabling optimisation of linear objectives. This representation enables robust optimization and the extraction of confidence intervals for specific parameter coordinates. Unlike previous methods, the confidence region can be empty, which can be used for hypothesis testing. Finally, we validate the empirical applicability of our method on synthetic data.
Revisiting Non-separable Binary Classification and its Applications in Anomaly Detection
Dec 03, 2023The inability to linearly classify XOR has motivated much of deep learning. We revisit this age-old problem and show that linear classification of XOR is indeed possible. Instead of separating data between halfspaces, we propose a slightly different paradigm, equality separation, that adapts the SVM objective to distinguish data within or outside the margin. Our classifier can then be integrated into neural network pipelines with a smooth approximation. From its properties, we intuit that equality separation is suitable for anomaly detection. To formalize this notion, we introduce closing numbers, a quantitative measure on the capacity for classifiers to form closed decision regions for anomaly detection. Springboarding from this theoretical connection between binary classification and anomaly detection, we test our hypothesis on supervised anomaly detection experiments, showing that equality separation can detect both seen and unseen anomalies.
Conformalization of Sparse Generalized Linear Models
Jul 11, 2023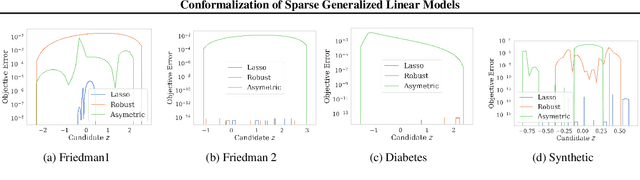
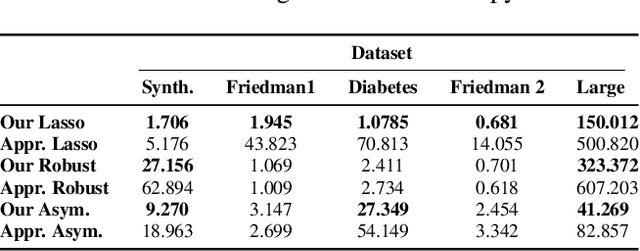

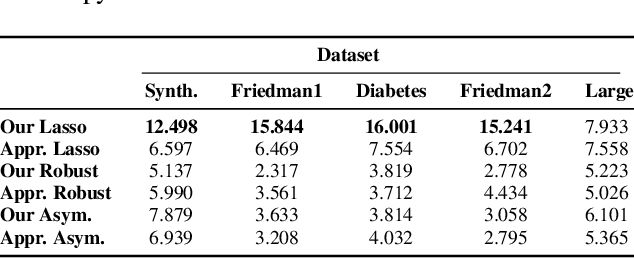
Given a sequence of observable variables $\{(x_1, y_1), \ldots, (x_n, y_n)\}$, the conformal prediction method estimates a confidence set for $y_{n+1}$ given $x_{n+1}$ that is valid for any finite sample size by merely assuming that the joint distribution of the data is permutation invariant. Although attractive, computing such a set is computationally infeasible in most regression problems. Indeed, in these cases, the unknown variable $y_{n+1}$ can take an infinite number of possible candidate values, and generating conformal sets requires retraining a predictive model for each candidate. In this paper, we focus on a sparse linear model with only a subset of variables for prediction and use numerical continuation techniques to approximate the solution path efficiently. The critical property we exploit is that the set of selected variables is invariant under a small perturbation of the input data. Therefore, it is sufficient to enumerate and refit the model only at the change points of the set of active features and smoothly interpolate the rest of the solution via a Predictor-Corrector mechanism. We show how our path-following algorithm accurately approximates conformal prediction sets and illustrate its performance using synthetic and real data examples.
Exact and Approximate Conformal Inference in Multiple Dimensions
Oct 31, 2022
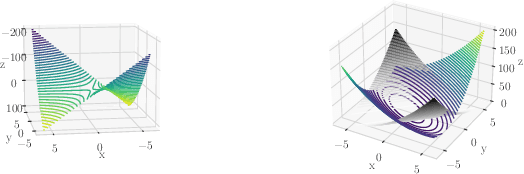
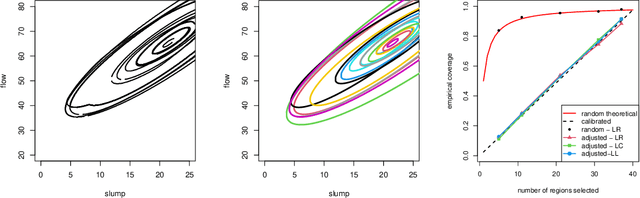
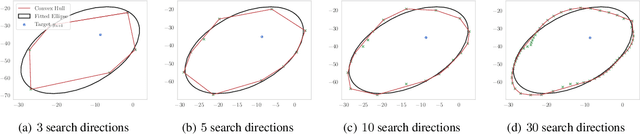
It is common in machine learning to estimate a response y given covariate information x. However, these predictions alone do not quantify any uncertainty associated with said predictions. One way to overcome this deficiency is with conformal inference methods, which construct a set containing the unobserved response y with a prescribed probability. Unfortunately, even with one-dimensional responses, conformal inference is computationally expensive despite recent encouraging advances. In this paper, we explore the multidimensional response case within a regression setting, delivering exact derivations of conformal inference p-values when the predictive model can be described as a linear function of y. Additionally, we propose different efficient ways of approximating the conformal prediction region for non-linear predictors while preserving computational advantages. We also provide empirical justification for these approaches using a real-world data example.
A Confidence Machine for Sparse High-Order Interaction Model
May 28, 2022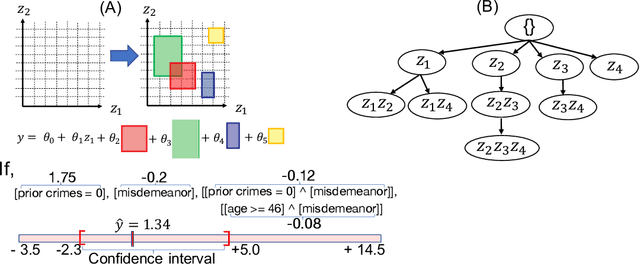
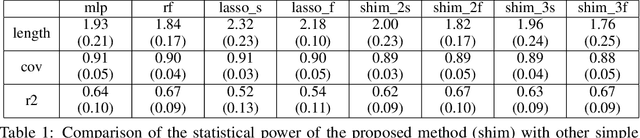
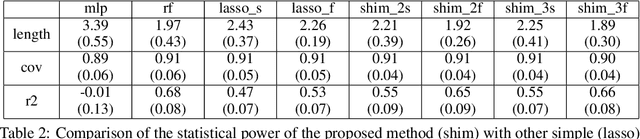
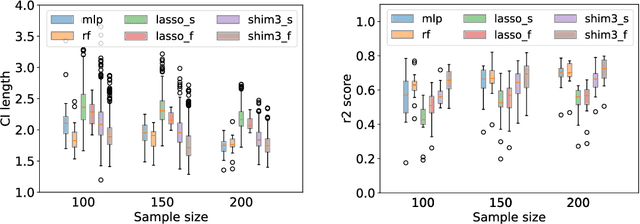
In predictive modeling for high-stake decision-making, predictors must be not only accurate but also reliable. Conformal prediction (CP) is a promising approach for obtaining the confidence of prediction results with fewer theoretical assumptions. To obtain the confidence set by so-called full-CP, we need to refit the predictor for all possible values of prediction results, which is only possible for simple predictors. For complex predictors such as random forests (RFs) or neural networks (NNs), split-CP is often employed where the data is split into two parts: one part for fitting and another to compute the confidence set. Unfortunately, because of the reduced sample size, split-CP is inferior to full-CP both in fitting as well as confidence set computation. In this paper, we develop a full-CP of sparse high-order interaction model (SHIM), which is sufficiently flexible as it can take into account high-order interactions among variables. We resolve the computational challenge for full-CP of SHIM by introducing a novel approach called homotopy mining. Through numerical experiments, we demonstrate that SHIM is as accurate as complex predictors such as RF and NN and enjoys the superior statistical power of full-CP.
Stable Conformal Prediction Sets
Dec 19, 2021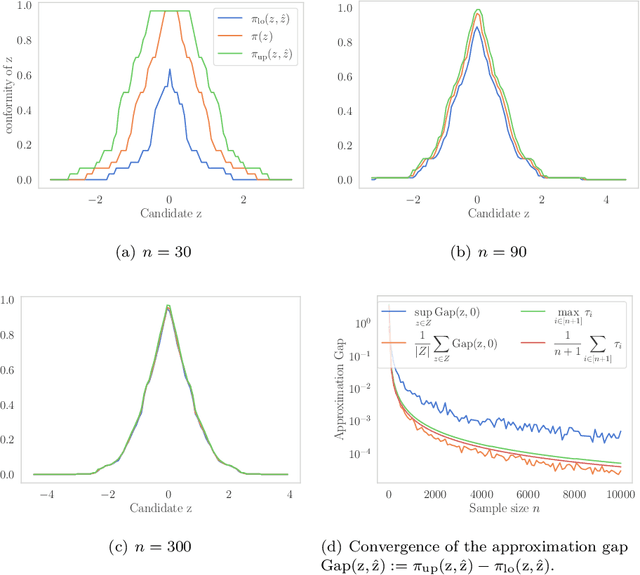
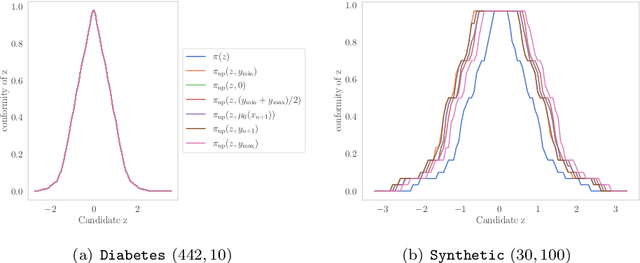
When one observes a sequence of variables $(x_1, y_1), ..., (x_n, y_n)$, conformal prediction is a methodology that allows to estimate a confidence set for $y_{n+1}$ given $x_{n+1}$ by merely assuming that the distribution of the data is exchangeable. While appealing, the computation of such set turns out to be infeasible in general, e.g. when the unknown variable $y_{n+1}$ is continuous. In this paper, we combine conformal prediction techniques with algorithmic stability bounds to derive a prediction set computable with a single model fit. We perform some numerical experiments that illustrate the tightness of our estimation when the sample size is sufficiently large.
Continuation Path with Linear Convergence Rate
Dec 09, 2021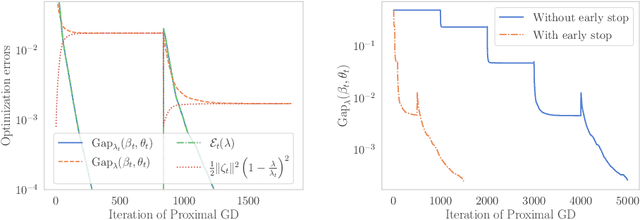
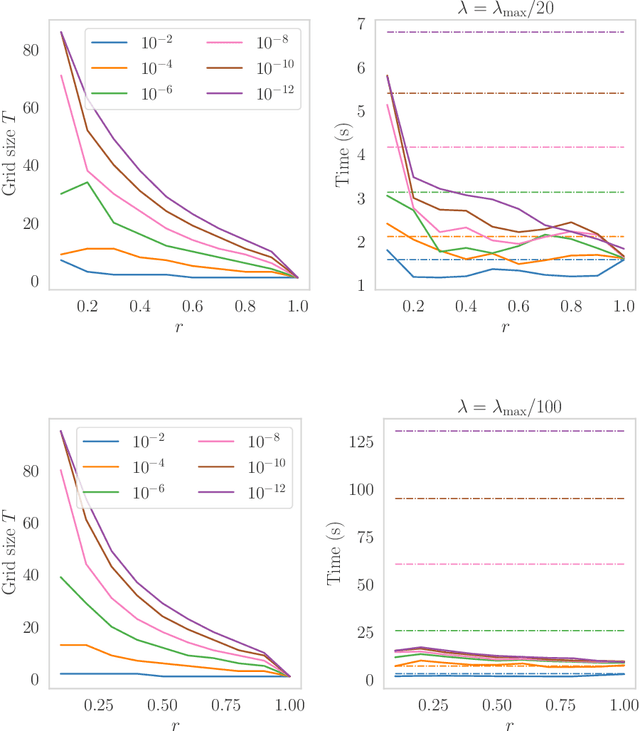
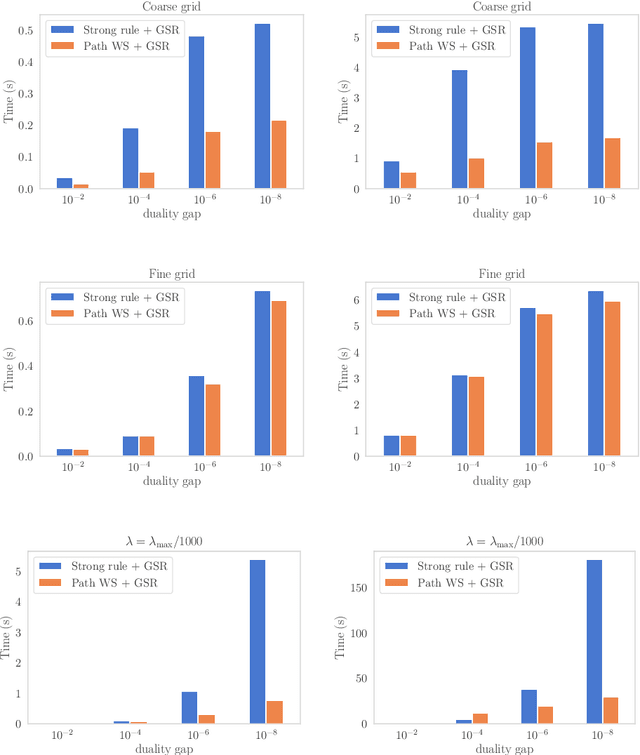
Path-following algorithms are frequently used in composite optimization problems where a series of subproblems, with varying regularization hyperparameters, are solved sequentially. By reusing the previous solutions as initialization, better convergence speeds have been observed numerically. This makes it a rather useful heuristic to speed up the execution of optimization algorithms in machine learning. We present a primal dual analysis of the path-following algorithm and explore how to design its hyperparameters as well as determining how accurately each subproblem should be solved to guarantee a linear convergence rate on a target problem. Furthermore, considering optimization with a sparsity-inducing penalty, we analyze the change of the active sets with respect to the regularization parameter. The latter can then be adaptively calibrated to finely determine the number of features that will be selected along the solution path. This leads to simple heuristics for calibrating hyperparameters of active set approaches to reduce their complexity and improve their execution time.
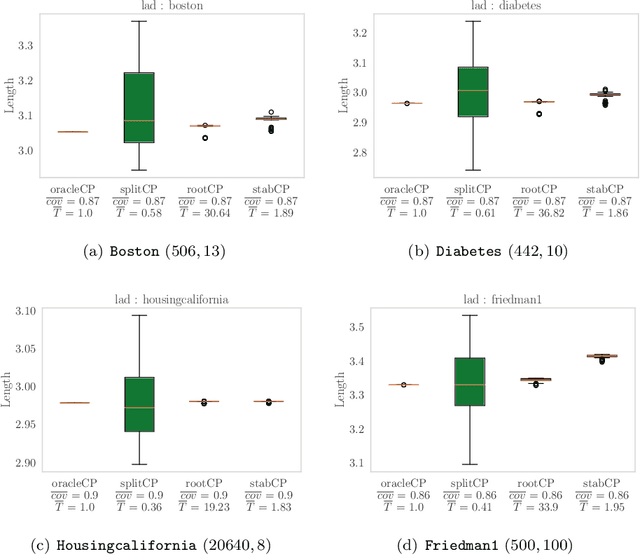
Root-finding Approaches for Computing Conformal Prediction Set
Apr 14, 2021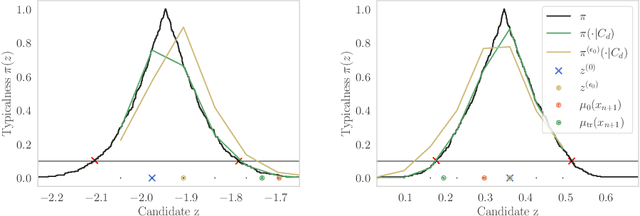

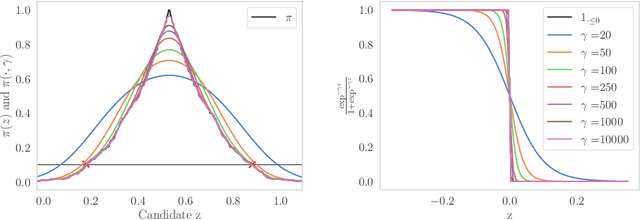

Conformal prediction constructs a confidence region for an unobserved response of a feature vector based on previous identically distributed and exchangeable observations of responses and features. It has a coverage guarantee at any nominal level without additional assumptions on their distribution. However, it requires a refitting procedure for all replacement candidates of the target response. In regression settings, this corresponds to an infinite number of model fit. Apart from relatively simple estimators that can be written as pieces of linear function of the response, efficiently computing such sets is difficult and is still considered as an open problem. We exploit the fact that, \emph{often}, conformal prediction sets are intervals whose boundaries can be efficiently approximated by classical root-finding software. We investigate how this approach can overcome many limitations of formerly used strategies and achieves calculations that have been unattainable so far. We discuss its complexity as well as its drawbacks and evaluate its efficiency through numerical experiments.