 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEugene Yuta Bann
Measuring Cultural Relativity of Emotional Valence and Arousal using Semantic Clustering and Twitter
Apr 28, 2013

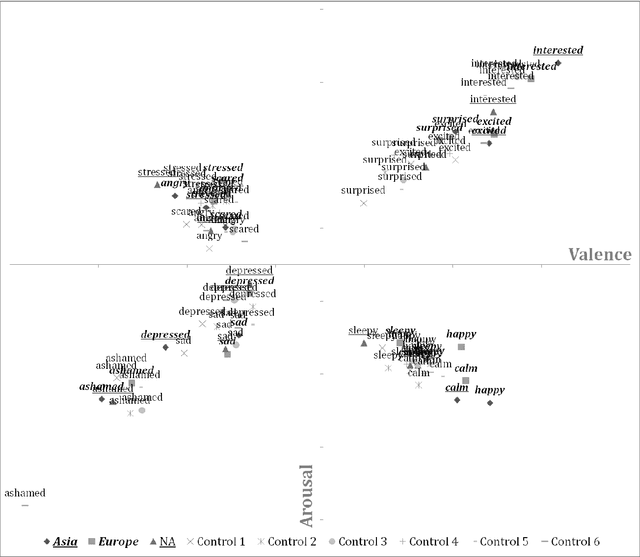
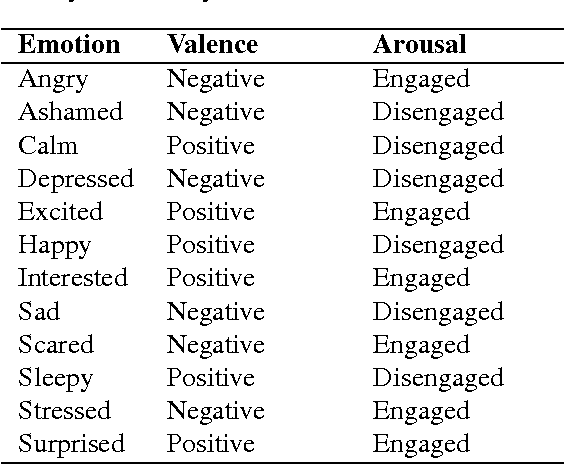
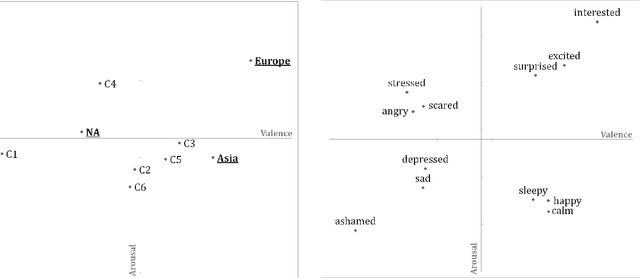
Researchers since at least Darwin have debated whether and to what extent emotions are universal or culture-dependent. However, previous studies have primarily focused on facial expressions and on a limited set of emotions. Given that emotions have a substantial impact on human lives, evidence for cultural emotional relativity might be derived by applying distributional semantics techniques to a text corpus of self-reported behaviour. Here, we explore this idea by measuring the valence and arousal of the twelve most popular emotion keywords expressed on the micro-blogging site Twitter. We do this in three geographical regions: Europe, Asia and North America. We demonstrate that in our sample, the valence and arousal levels of the same emotion keywords differ significantly with respect to these geographical regions --- Europeans are, or at least present themselves as more positive and aroused, North Americans are more negative and Asians appear to be more positive but less aroused when compared to global valence and arousal levels of the same emotion keywords. Our work is the first in kind to programatically map large text corpora to a dimensional model of affect.
Discovering Basic Emotion Sets via Semantic Clustering on a Twitter Corpus
Dec 28, 2012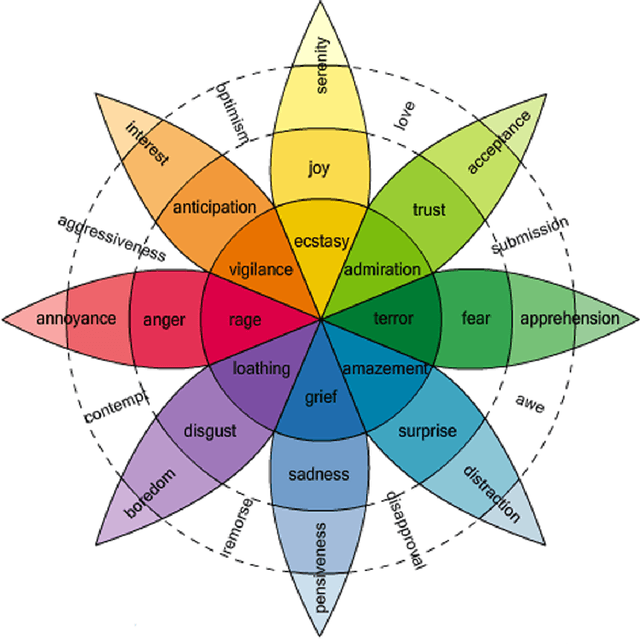
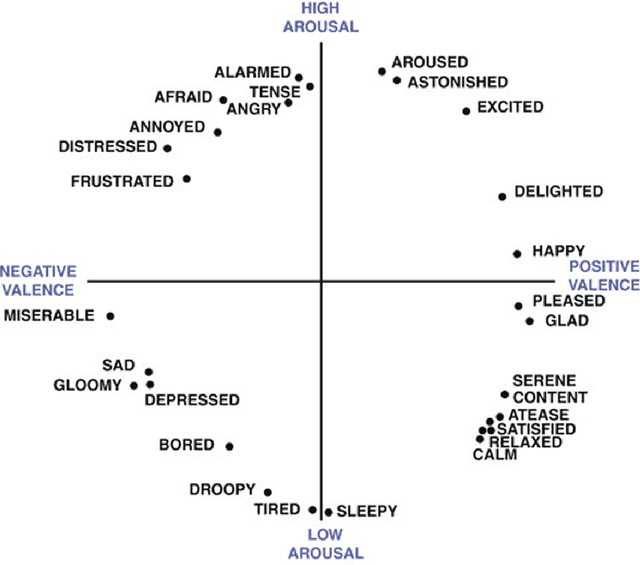
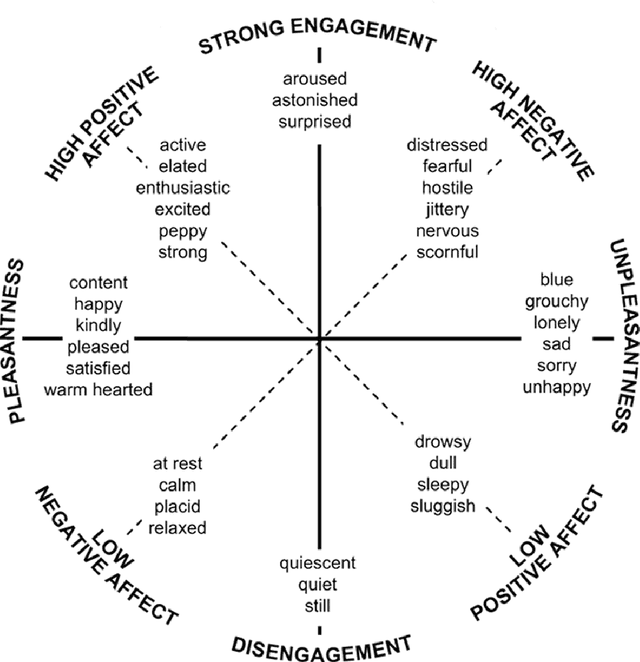

A plethora of words are used to describe the spectrum of human emotions, but how many emotions are there really, and how do they interact? Over the past few decades, several theories of emotion have been proposed, each based around the existence of a set of 'basic emotions', and each supported by an extensive variety of research including studies in facial expression, ethology, neurology and physiology. Here we present research based on a theory that people transmit their understanding of emotions through the language they use surrounding emotion keywords. Using a labelled corpus of over 21,000 tweets, six of the basic emotion sets proposed in existing literature were analysed using Latent Semantic Clustering (LSC), evaluating the distinctiveness of the semantic meaning attached to the emotional label. We hypothesise that the more distinct the language is used to express a certain emotion, then the more distinct the perception (including proprioception) of that emotion is, and thus more 'basic'. This allows us to select the dimensions best representing the entire spectrum of emotion. We find that Ekman's set, arguably the most frequently used for classifying emotions, is in fact the most semantically distinct overall. Next, taking all analysed (that is, previously proposed) emotion terms into account, we determine the optimal semantically irreducible basic emotion set using an iterative LSC algorithm. Our newly-derived set (Accepting, Ashamed, Contempt, Interested, Joyful, Pleased, Sleepy, Stressed) generates a 6.1% increase in distinctiveness over Ekman's set (Angry, Disgusted, Joyful, Sad, Scared). We also demonstrate how using LSC data can help visualise emotions. We introduce the concept of an Emotion Profile and briefly analyse compound emotions both visually and mathematically.