 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEunseop Yoon
C-TPT: Calibrated Test-Time Prompt Tuning for Vision-Language Models via Text Feature Dispersion
Mar 31, 2024
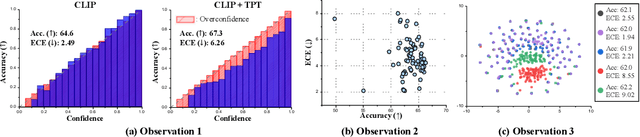
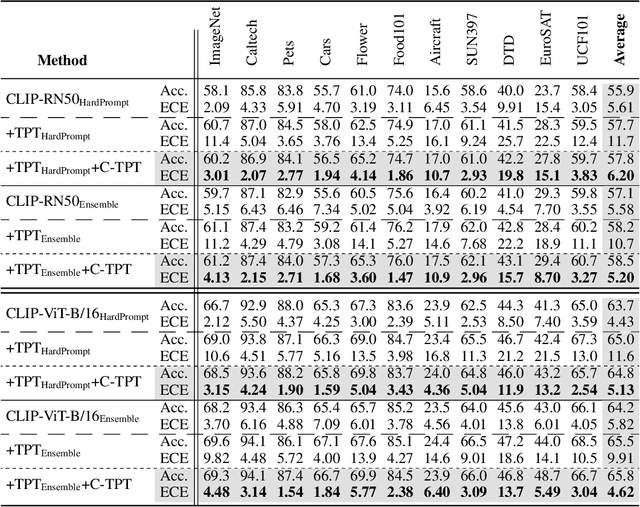
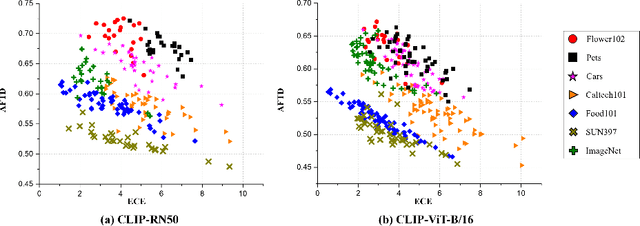
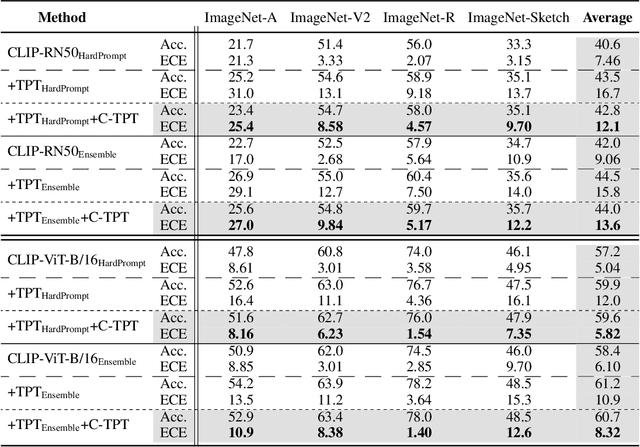
In deep learning, test-time adaptation has gained attention as a method for model fine-tuning without the need for labeled data. A prime exemplification is the recently proposed test-time prompt tuning for large-scale vision-language models such as CLIP. Unfortunately, these prompts have been mainly developed to improve accuracy, overlooking the importance of calibration, which is a crucial aspect for quantifying prediction uncertainty. However, traditional calibration methods rely on substantial amounts of labeled data, making them impractical for test-time scenarios. To this end, this paper explores calibration during test-time prompt tuning by leveraging the inherent properties of CLIP. Through a series of observations, we find that the prompt choice significantly affects the calibration in CLIP, where the prompts leading to higher text feature dispersion result in better-calibrated predictions. Introducing the Average Text Feature Dispersion (ATFD), we establish its relationship with calibration error and present a novel method, Calibrated Test-time Prompt Tuning (C-TPT), for optimizing prompts during test-time with enhanced calibration. Through extensive experiments on different CLIP architectures and datasets, we show that C-TPT can effectively improve the calibration of test-time prompt tuning without needing labeled data. The code is publicly accessible at https://github.com/hee-suk-yoon/C-TPT.
AdaMER-CTC: Connectionist Temporal Classification with Adaptive Maximum Entropy Regularization for Automatic Speech Recognition
Mar 18, 2024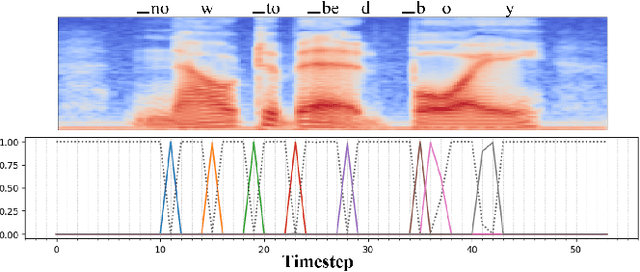
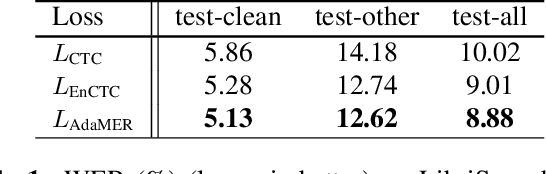
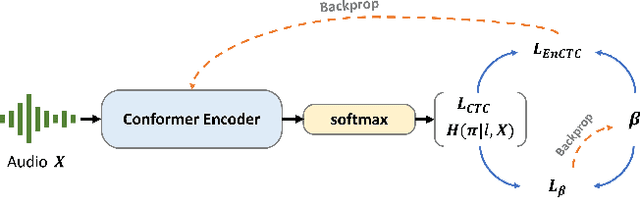
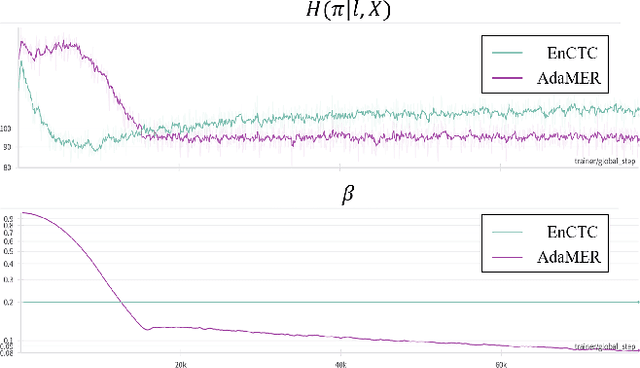
In Automatic Speech Recognition (ASR) systems, a recurring obstacle is the generation of narrowly focused output distributions. This phenomenon emerges as a side effect of Connectionist Temporal Classification (CTC), a robust sequence learning tool that utilizes dynamic programming for sequence mapping. While earlier efforts have tried to combine the CTC loss with an entropy maximization regularization term to mitigate this issue, they employed a constant weighting term on the regularization during the training, which we find may not be optimal. In this work, we introduce Adaptive Maximum Entropy Regularization (AdaMER), a technique that can modulate the impact of entropy regularization throughout the training process. This approach not only refines ASR model training but ensures that as training proceeds, predictions display the desired model confidence.
HEAR: Hearing Enhanced Audio Response for Video-grounded Dialogue
Dec 15, 2023Video-grounded Dialogue (VGD) aims to answer questions regarding a given multi-modal input comprising video, audio, and dialogue history. Although there have been numerous efforts in developing VGD systems to improve the quality of their responses, existing systems are competent only to incorporate the information in the video and text and tend to struggle in extracting the necessary information from the audio when generating appropriate responses to the question. The VGD system seems to be deaf, and thus, we coin this symptom of current systems' ignoring audio data as a deaf response. To overcome the deaf response problem, Hearing Enhanced Audio Response (HEAR) framework is proposed to perform sensible listening by selectively attending to audio whenever the question requires it. The HEAR framework enhances the accuracy and audibility of VGD systems in a model-agnostic manner. HEAR is validated on VGD datasets (i.e., AVSD@DSTC7 and AVSD@DSTC8) and shows effectiveness with various VGD systems.
SimPSI: A Simple Strategy to Preserve Spectral Information in Time Series Data Augmentation
Dec 10, 2023Data augmentation is a crucial component in training neural networks to overcome the limitation imposed by data size, and several techniques have been studied for time series. Although these techniques are effective in certain tasks, they have yet to be generalized to time series benchmarks. We find that current data augmentation techniques ruin the core information contained within the frequency domain. To address this issue, we propose a simple strategy to preserve spectral information (SimPSI) in time series data augmentation. SimPSI preserves the spectral information by mixing the original and augmented input spectrum weighted by a preservation map, which indicates the importance score of each frequency. Specifically, our experimental contributions are to build three distinct preservation maps: magnitude spectrum, saliency map, and spectrum-preservative map. We apply SimPSI to various time series data augmentations and evaluate its effectiveness across a wide range of time series benchmarks. Our experimental results support that SimPSI considerably enhances the performance of time series data augmentations by preserving core spectral information. The source code used in the paper is available at https://github.com/Hyun-Ryu/simpsi.
Mitigating the Exposure Bias in Sentence-Level Grapheme-to-Phoneme (G2P) Transduction
Aug 16, 2023Text-to-Text Transfer Transformer (T5) has recently been considered for the Grapheme-to-Phoneme (G2P) transduction. As a follow-up, a tokenizer-free byte-level model based on T5 referred to as ByT5, recently gave promising results on word-level G2P conversion by representing each input character with its corresponding UTF-8 encoding. Although it is generally understood that sentence-level or paragraph-level G2P can improve usability in real-world applications as it is better suited to perform on heteronyms and linking sounds between words, we find that using ByT5 for these scenarios is nontrivial. Since ByT5 operates on the character level, it requires longer decoding steps, which deteriorates the performance due to the exposure bias commonly observed in auto-regressive generation models. This paper shows that the performance of sentence-level and paragraph-level G2P can be improved by mitigating such exposure bias using our proposed loss-based sampling method.
INTapt: Information-Theoretic Adversarial Prompt Tuning for Enhanced Non-Native Speech Recognition
May 25, 2023
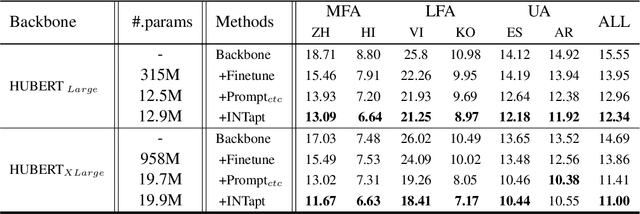
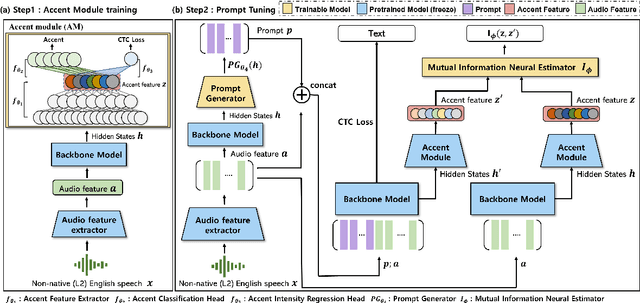
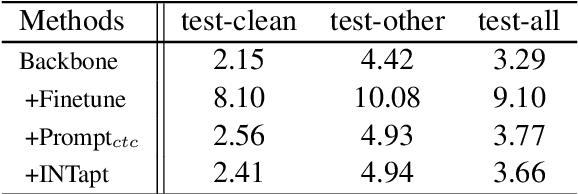
Automatic Speech Recognition (ASR) systems have attained unprecedented performance with large speech models pre-trained based on self-supervised speech representation learning. However, these pre-trained speech models suffer from representational bias as they tend to better represent those prominent accents (i.e., native (L1) English accent) in the pre-training speech corpus than less represented accents, resulting in a deteriorated performance for non-native (L2) English accents. Although there have been some approaches to mitigate this issue, all of these methods require updating the pre-trained model weights. In this paper, we propose Information Theoretic Adversarial Prompt Tuning (INTapt), which introduces prompts concatenated to the original input that can re-modulate the attention of the pre-trained model such that the corresponding input resembles a native (L1) English speech without updating the backbone weights. INTapt is trained simultaneously in the following two manners: (1) adversarial training to reduce accent feature dependence between the original input and the prompt-concatenated input and (2) training to minimize CTC loss for improving ASR performance to a prompt-concatenated input. Experimental results show that INTapt improves the performance of L2 English and increases feature similarity between L2 and L1 accents.
ESD: Expected Squared Difference as a Tuning-Free Trainable Calibration Measure
Mar 04, 2023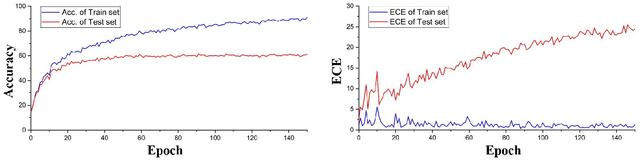
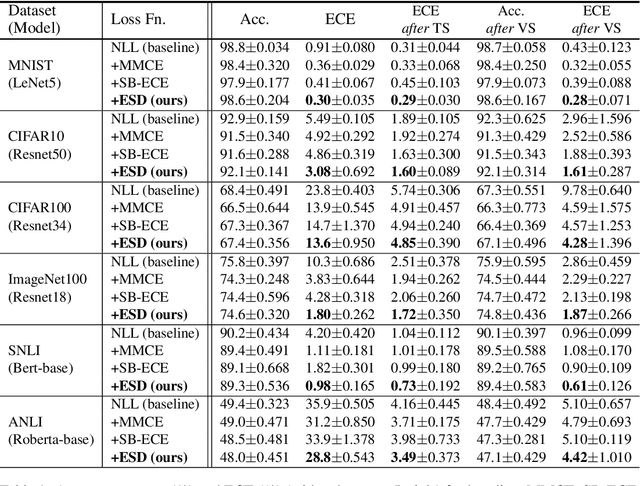
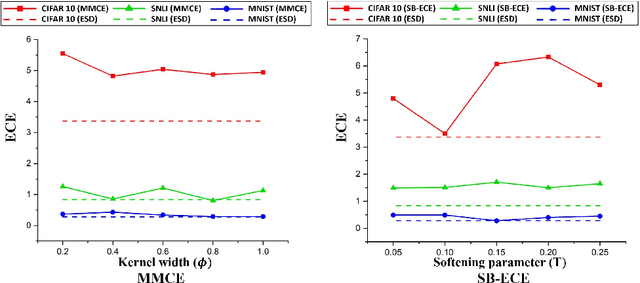
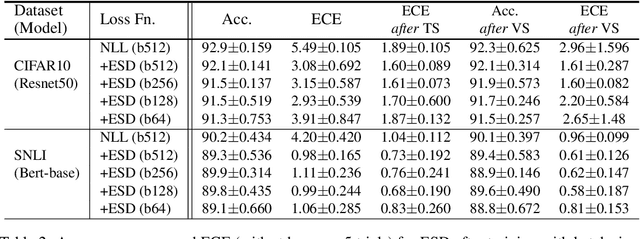
Studies have shown that modern neural networks tend to be poorly calibrated due to over-confident predictions. Traditionally, post-processing methods have been used to calibrate the model after training. In recent years, various trainable calibration measures have been proposed to incorporate them directly into the training process. However, these methods all incorporate internal hyperparameters, and the performance of these calibration objectives relies on tuning these hyperparameters, incurring more computational costs as the size of neural networks and datasets become larger. As such, we present Expected Squared Difference (ESD), a tuning-free (i.e., hyperparameter-free) trainable calibration objective loss, where we view the calibration error from the perspective of the squared difference between the two expectations. With extensive experiments on several architectures (CNNs, Transformers) and datasets, we demonstrate that (1) incorporating ESD into the training improves model calibration in various batch size settings without the need for internal hyperparameter tuning, (2) ESD yields the best-calibrated results compared with previous approaches, and (3) ESD drastically improves the computational costs required for calibration during training due to the absence of internal hyperparameter. The code is publicly accessible at https://github.com/hee-suk-yoon/ESD.
SMSMix: Sense-Maintained Sentence Mixup for Word Sense Disambiguation
Dec 21, 2022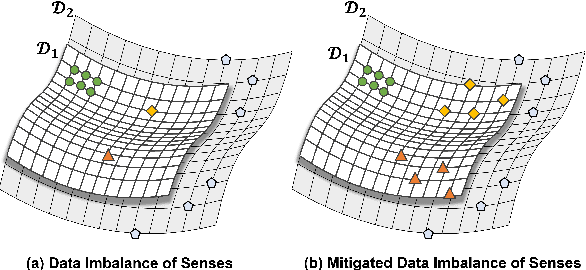
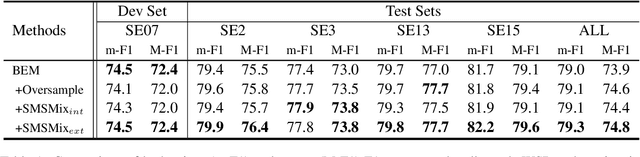

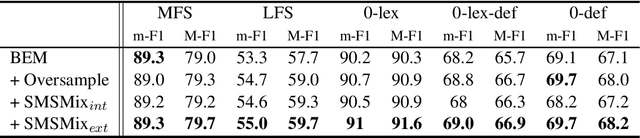
Word Sense Disambiguation (WSD) is an NLP task aimed at determining the correct sense of a word in a sentence from discrete sense choices. Although current systems have attained unprecedented performances for such tasks, the nonuniform distribution of word senses during training generally results in systems performing poorly on rare senses. To this end, we consider data augmentation to increase the frequency of these least frequent senses (LFS) to reduce the distributional bias of senses during training. We propose Sense-Maintained Sentence Mixup (SMSMix), a novel word-level mixup method that maintains the sense of a target word. SMSMix smoothly blends two sentences using mask prediction while preserving the relevant span determined by saliency scores to maintain a specific word's sense. To the best of our knowledge, this is the first attempt to apply mixup in NLP while preserving the meaning of a specific word. With extensive experiments, we validate that our augmentation method can effectively give more information about rare senses during training with maintained target sense label.
Information-Theoretic Text Hallucination Reduction for Video-grounded Dialogue
Dec 12, 2022
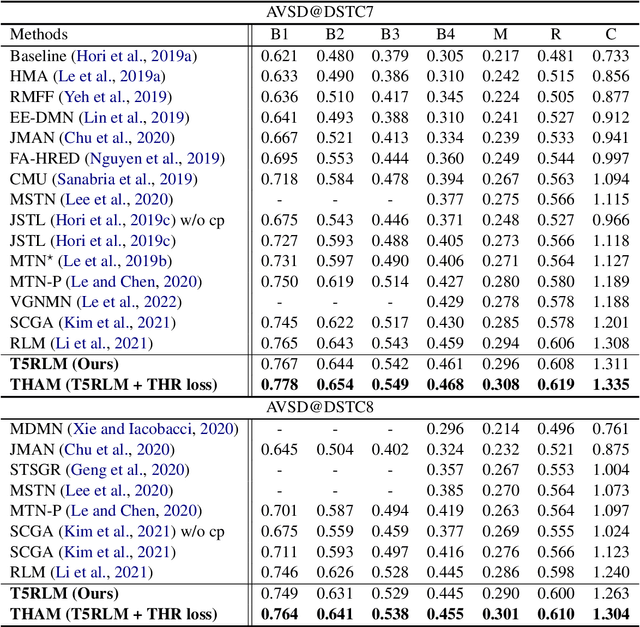
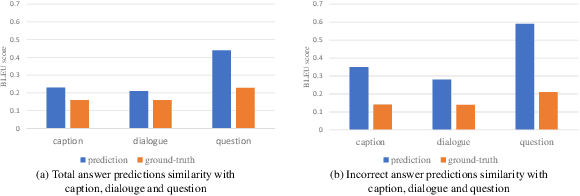
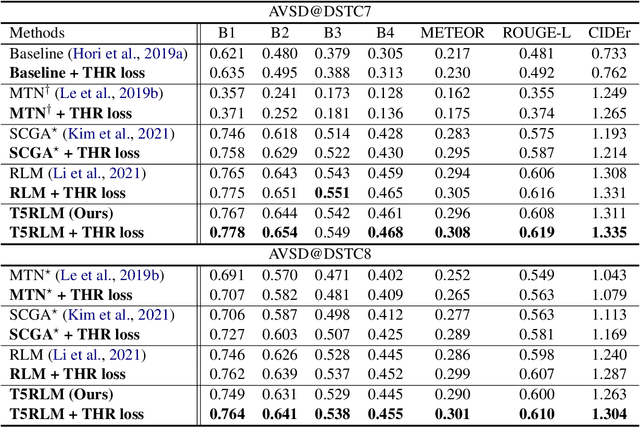
Video-grounded Dialogue (VGD) aims to decode an answer sentence to a question regarding a given video and dialogue context. Despite the recent success of multi-modal reasoning to generate answer sentences, existing dialogue systems still suffer from a text hallucination problem, which denotes indiscriminate text-copying from input texts without an understanding of the question. This is due to learning spurious correlations from the fact that answer sentences in the dataset usually include the words of input texts, thus the VGD system excessively relies on copying words from input texts by hoping those words to overlap with ground-truth texts. Hence, we design Text Hallucination Mitigating (THAM) framework, which incorporates Text Hallucination Regularization (THR) loss derived from the proposed information-theoretic text hallucination measurement approach. Applying THAM with current dialogue systems validates the effectiveness on VGD benchmarks (i.e., AVSD@DSTC7 and AVSD@DSTC8) and shows enhanced interpretability.
Selective Query-guided Debiasing Network for Video Corpus Moment Retrieval
Oct 17, 2022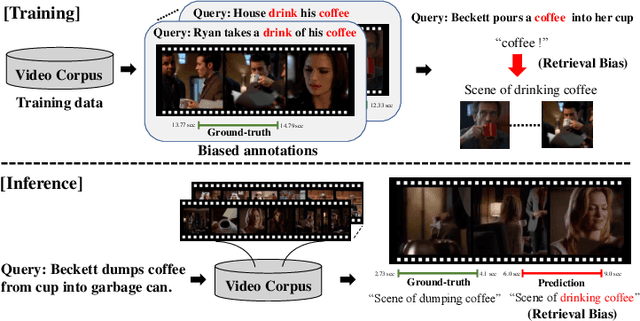
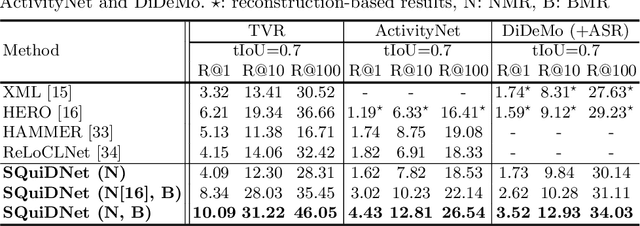
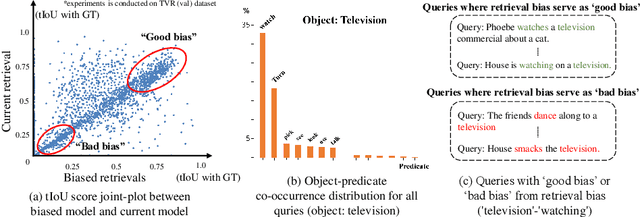

Video moment retrieval (VMR) aims to localize target moments in untrimmed videos pertinent to a given textual query. Existing retrieval systems tend to rely on retrieval bias as a shortcut and thus, fail to sufficiently learn multi-modal interactions between query and video. This retrieval bias stems from learning frequent co-occurrence patterns between query and moments, which spuriously correlate objects (e.g., a pencil) referred in the query with moments (e.g., scene of writing with a pencil) where the objects frequently appear in the video, such that they converge into biased moment predictions. Although recent debiasing methods have focused on removing this retrieval bias, we argue that these biased predictions sometimes should be preserved because there are many queries where biased predictions are rather helpful. To conjugate this retrieval bias, we propose a Selective Query-guided Debiasing network (SQuiDNet), which incorporates the following two main properties: (1) Biased Moment Retrieval that intentionally uncovers the biased moments inherent in objects of the query and (2) Selective Query-guided Debiasing that performs selective debiasing guided by the meaning of the query. Our experimental results on three moment retrieval benchmarks (i.e., TVR, ActivityNet, DiDeMo) show the effectiveness of SQuiDNet and qualitative analysis shows improved interpretability.