 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEwout van den Berg
The Ocean Tensor Package
Oct 20, 2018
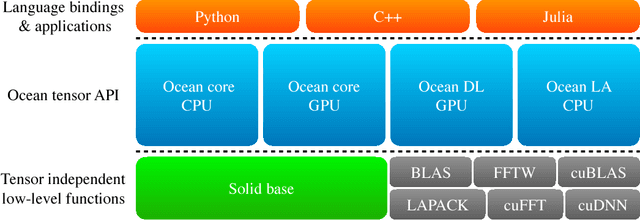


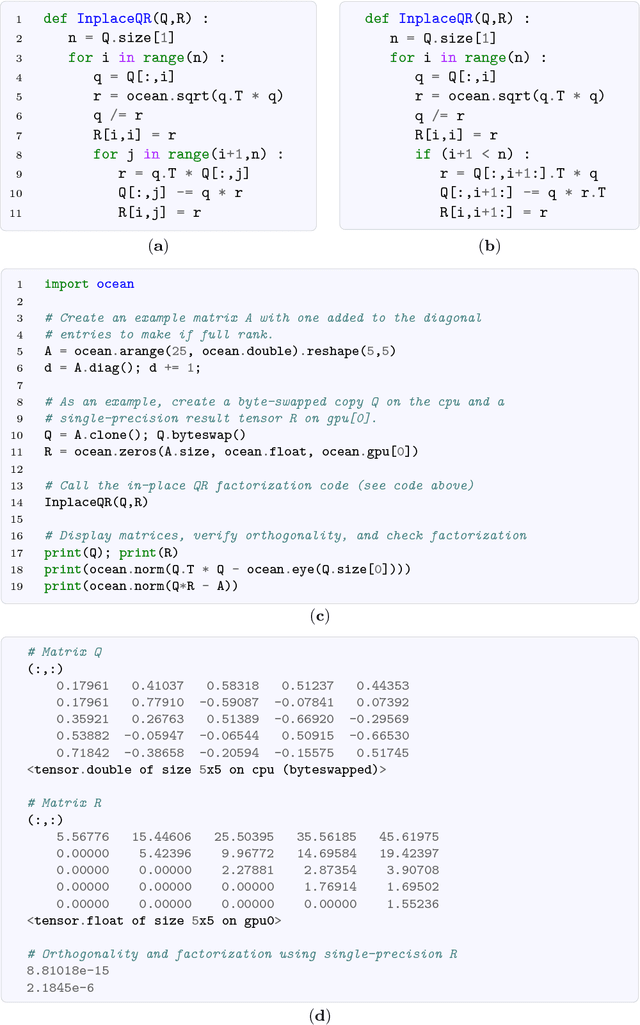
Matrix and tensor operations form the basis of a wide range of fields and applications, and in many cases constitute a substantial part of the overall computational complexity. The ability of general-purpose GPUs to speed up many of these operations and enable others has resulted in a widespread adaptation of these devices. In order for tensor operations to take full advantage of the computational power, specialized software is required, and currently there exist several packages (predominantly in the area of deep learning) that incorporate tensor operations on both CPU and GPU. Nevertheless, a stand-alone framework that supports general tensor operations is still missing. In this paper we fill this gap and propose the Ocean Tensor Library: a modular tensor-support package that is designed to serve as a foundational layer for applications that require dense tensor operations on a variety of device types. The API is carefully designed to be powerful, extensible, and at the same time easy to use. The package is available as open source.
Estimating Information Flow in Neural Networks
Oct 16, 2018
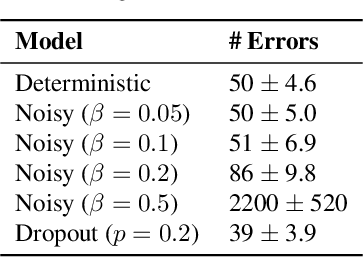
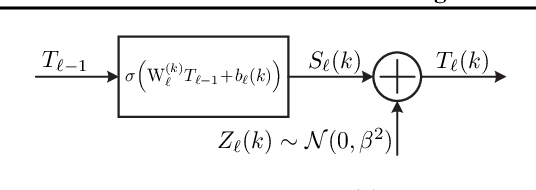
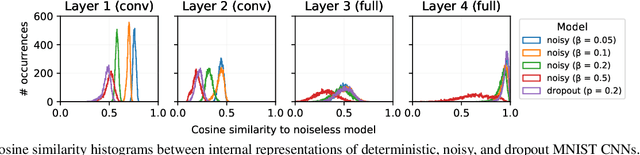
We study the flow of information and the evolution of internal representations during deep neural network (DNN) training, aiming to demystify the compression aspect of the information bottleneck theory. The theory suggests that DNN training comprises a rapid fitting phase followed by a slower compression phase, in which the mutual information $I(X;T)$ between the input $X$ and internal representations $T$ decreases. Several papers observe compression of estimated mutual information on different DNN models, but the true $I(X;T)$ over these networks is provably either constant (discrete $X$) or infinite (continuous $X$). This work explains the discrepancy between theory and experiments, and clarifies what was actually measured by these past works. To this end, we introduce an auxiliary (noisy) DNN framework for which $I(X;T)$ is a meaningful quantity that depends on the network's parameters. This noisy framework is shown to be a good proxy for the original (deterministic) DNN both in terms of performance and the learned representations. We then develop a rigorous estimator for $I(X;T)$ in noisy DNNs and observe compression in various models. By relating $I(X;T)$ in the noisy DNN to an information-theoretic communication problem, we show that compression is driven by the progressive clustering of hidden representations of inputs from the same class. Several methods to directly monitor clustering of hidden representations, both in noisy and deterministic DNNs, are used to show that meaningful clusters form in the $T$ space. Finally, we return to the estimator of $I(X;T)$ employed in past works, and demonstrate that while it fails to capture the true (vacuous) mutual information, it does serve as a measure for clustering. This clarifies the past observations of compression and isolates the geometric clustering of hidden representations as the true phenomenon of interest.
Training variance and performance evaluation of neural networks in speech
Jun 14, 2016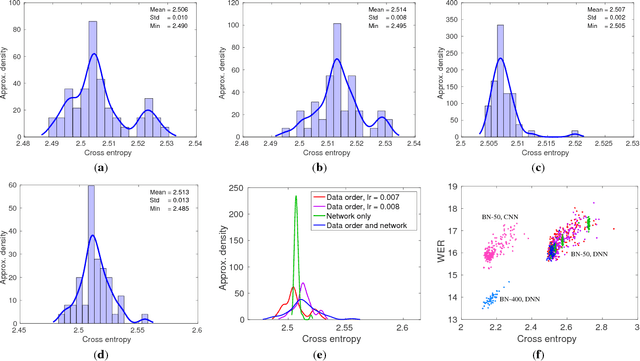
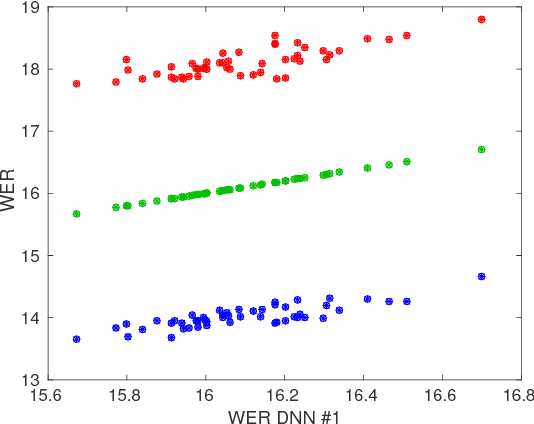
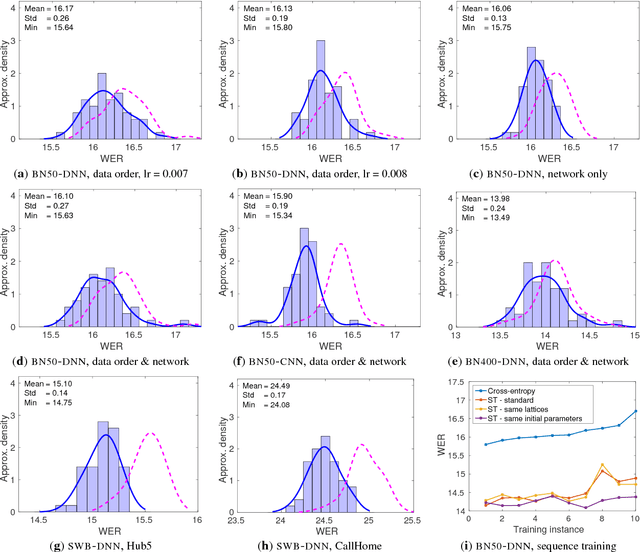
In this work we study variance in the results of neural network training on a wide variety of configurations in automatic speech recognition. Although this variance itself is well known, this is, to the best of our knowledge, the first paper that performs an extensive empirical study on its effects in speech recognition. We view training as sampling from a distribution and show that these distributions can have a substantial variance. These results show the urgent need to rethink the way in which results in the literature are reported and interpreted.
Some Insights into the Geometry and Training of Neural Networks
May 02, 2016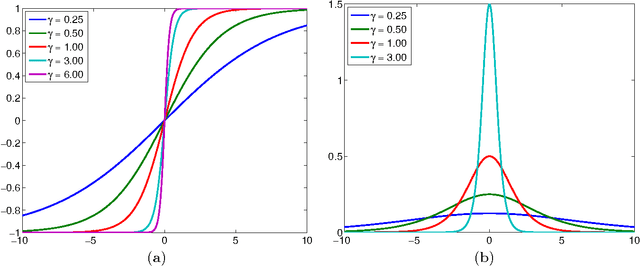
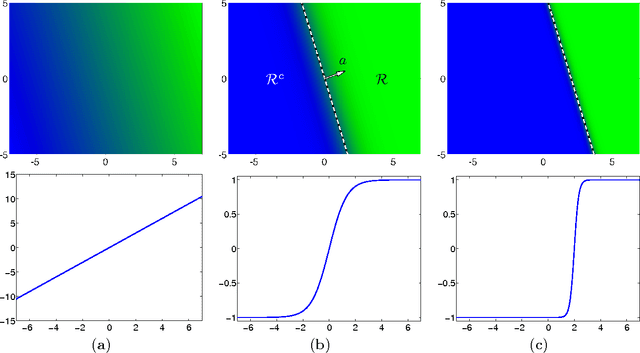
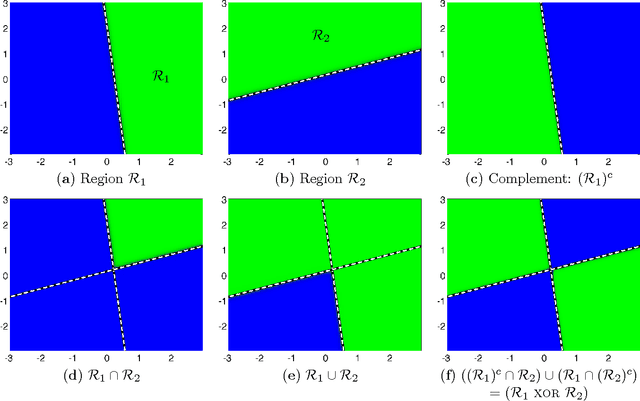
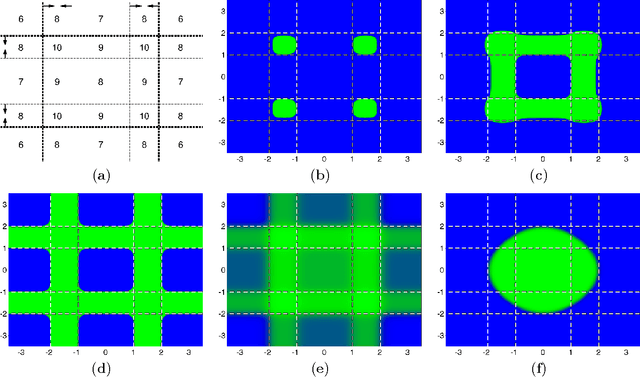
Neural networks have been successfully used for classification tasks in a rapidly growing number of practical applications. Despite their popularity and widespread use, there are still many aspects of training and classification that are not well understood. In this paper we aim to provide some new insights into training and classification by analyzing neural networks from a feature-space perspective. We review and explain the formation of decision regions and study some of their combinatorial aspects. We place a particular emphasis on the connections between the neural network weight and bias terms and properties of decision boundaries and other regions that exhibit varying levels of classification confidence. We show how the error backpropagates in these regions and emphasize the important role they have in the formation of gradients. These findings expose the connections between scaling of the weight parameters and the density of the training samples. This sheds more light on the vanishing gradient problem, explains the need for regularization, and suggests an approach for subsampling training data to improve performance.