 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFabio De Sousa Ribeiro
Counterfactual contrastive learning: robust representations via causal image synthesis
Mar 14, 2024
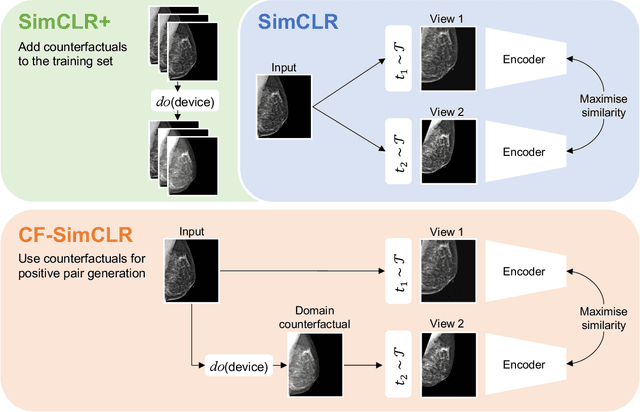
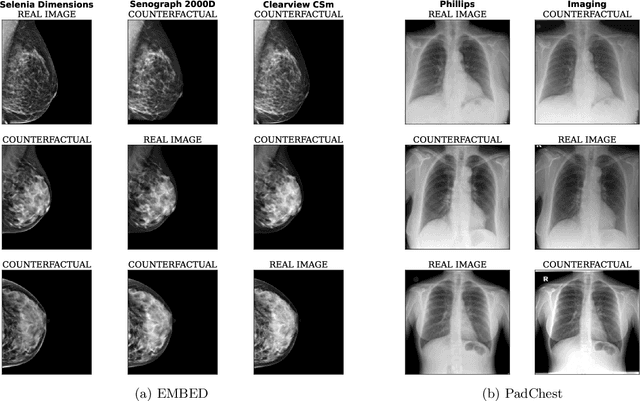
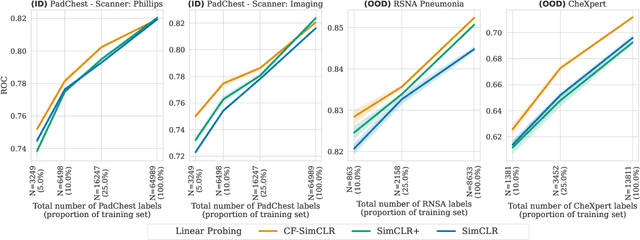
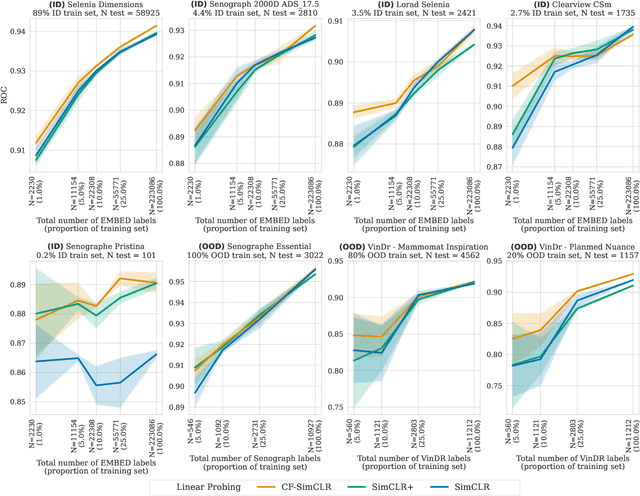
Contrastive pretraining is well-known to improve downstream task performance and model generalisation, especially in limited label settings. However, it is sensitive to the choice of augmentation pipeline. Positive pairs should preserve semantic information while destroying domain-specific information. Standard augmentation pipelines emulate domain-specific changes with pre-defined photometric transformations, but what if we could simulate realistic domain changes instead? In this work, we show how to utilise recent progress in counterfactual image generation to this effect. We propose CF-SimCLR, a counterfactual contrastive learning approach which leverages approximate counterfactual inference for positive pair creation. Comprehensive evaluation across five datasets, on chest radiography and mammography, demonstrates that CF-SimCLR substantially improves robustness to acquisition shift with higher downstream performance on both in- and out-of-distribution data, particularly for domains which are under-represented during training.
Mitigating attribute amplification in counterfactual image generation
Mar 14, 2024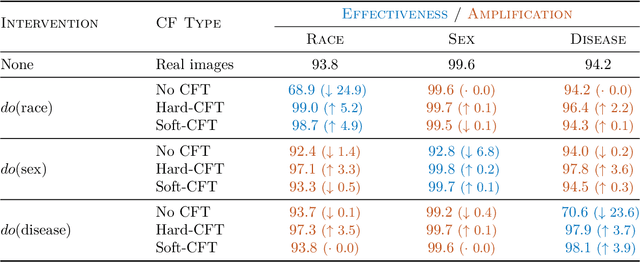
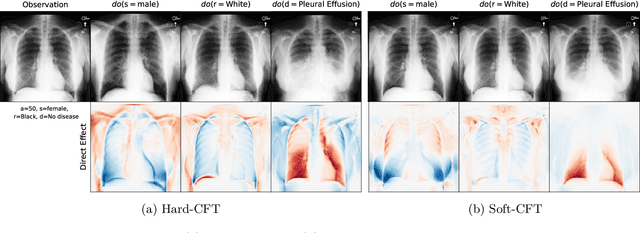
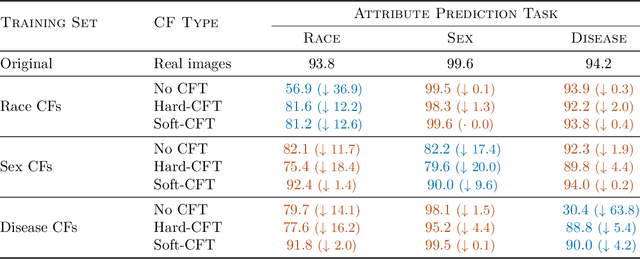
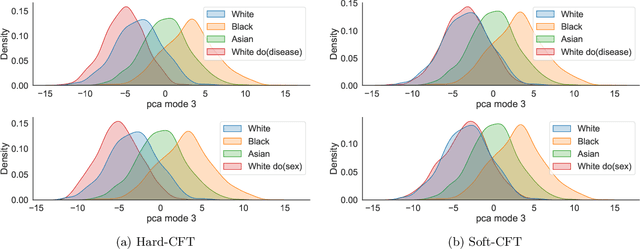
Causal generative modelling is gaining interest in medical imaging due to its ability to answer interventional and counterfactual queries. Most work focuses on generating counterfactual images that look plausible, using auxiliary classifiers to enforce effectiveness of simulated interventions. We investigate pitfalls in this approach, discovering the issue of attribute amplification, where unrelated attributes are spuriously affected during interventions, leading to biases across protected characteristics and disease status. We show that attribute amplification is caused by the use of hard labels in the counterfactual training process and propose soft counterfactual fine-tuning to mitigate this issue. Our method substantially reduces the amplification effect while maintaining effectiveness of generated images, demonstrated on a large chest X-ray dataset. Our work makes an important advancement towards more faithful and unbiased causal modelling in medical imaging.
Demystifying Variational Diffusion Models
Jan 11, 2024Despite the growing popularity of diffusion models, gaining a deep understanding of the model class remains somewhat elusive for the uninitiated in non-equilibrium statistical physics. With that in mind, we present what we believe is a more straightforward introduction to diffusion models using directed graphical modelling and variational Bayesian principles, which imposes relatively fewer prerequisites on the average reader. Our exposition constitutes a comprehensive technical review spanning from foundational concepts like deep latent variable models to recent advances in continuous-time diffusion-based modelling, highlighting theoretical connections between model classes along the way. We provide additional mathematical insights that were omitted in the seminal works whenever possible to aid in understanding, while avoiding the introduction of new notation. We envision this article serving as a useful educational supplement for both researchers and practitioners in the area, and we welcome feedback and contributions from the community at https://github.com/biomedia-mira/demystifying-diffusion.
No Fair Lunch: A Causal Perspective on Dataset Bias in Machine Learning for Medical Imaging
Jul 31, 2023As machine learning methods gain prominence within clinical decision-making, addressing fairness concerns becomes increasingly urgent. Despite considerable work dedicated to detecting and ameliorating algorithmic bias, today's methods are deficient with potentially harmful consequences. Our causal perspective sheds new light on algorithmic bias, highlighting how different sources of dataset bias may appear indistinguishable yet require substantially different mitigation strategies. We introduce three families of causal bias mechanisms stemming from disparities in prevalence, presentation, and annotation. Our causal analysis underscores how current mitigation methods tackle only a narrow and often unrealistic subset of scenarios. We provide a practical three-step framework for reasoning about fairness in medical imaging, supporting the development of safe and equitable AI prediction models.
High Fidelity Image Counterfactuals with Probabilistic Causal Models
Jul 18, 2023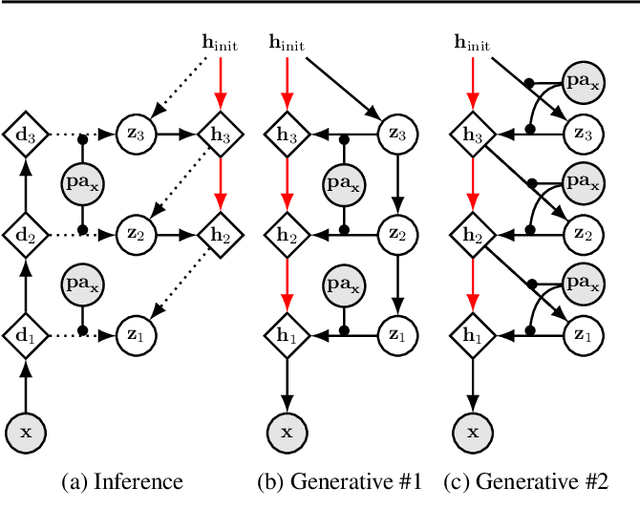
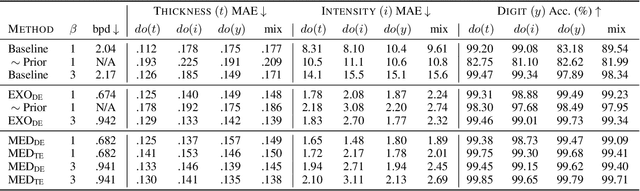
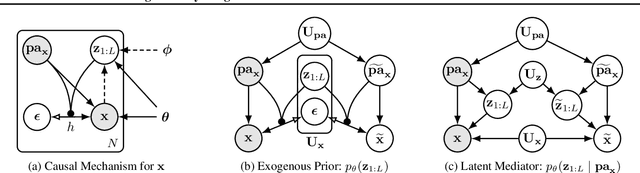
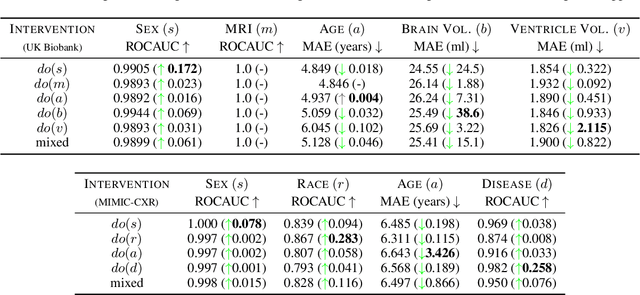
We present a general causal generative modelling framework for accurate estimation of high fidelity image counterfactuals with deep structural causal models. Estimation of interventional and counterfactual queries for high-dimensional structured variables, such as images, remains a challenging task. We leverage ideas from causal mediation analysis and advances in generative modelling to design new deep causal mechanisms for structured variables in causal models. Our experiments demonstrate that our proposed mechanisms are capable of accurate abduction and estimation of direct, indirect and total effects as measured by axiomatic soundness of counterfactuals.
Measuring axiomatic soundness of counterfactual image models
Mar 02, 2023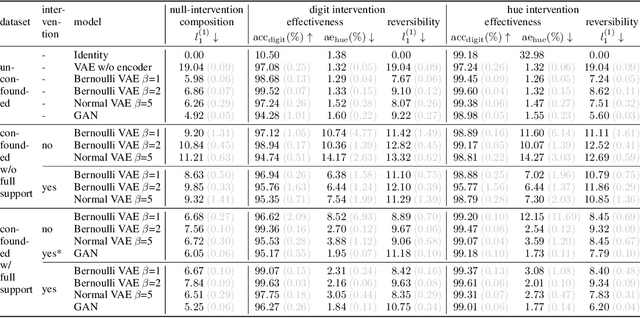

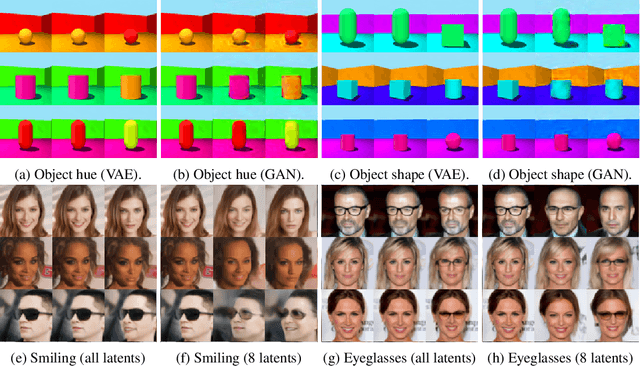
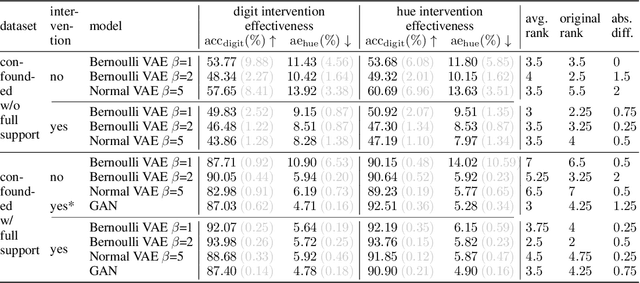
We present a general framework for evaluating image counterfactuals. The power and flexibility of deep generative models make them valuable tools for learning mechanisms in structural causal models. However, their flexibility makes counterfactual identifiability impossible in the general case. Motivated by these issues, we revisit Pearl's axiomatic definition of counterfactuals to determine the necessary constraints of any counterfactual inference model: composition, reversibility, and effectiveness. We frame counterfactuals as functions of an input variable, its parents, and counterfactual parents and use the axiomatic constraints to restrict the set of functions that could represent the counterfactual, thus deriving distance metrics between the approximate and ideal functions. We demonstrate how these metrics can be used to compare and choose between different approximate counterfactual inference models and to provide insight into a model's shortcomings and trade-offs.
* Counterfactual inference, Generative Models, Computer Vision, Published in ICLR 2023
Analysing the effectiveness of a generative model for semi-supervised medical image segmentation
Nov 03, 2022

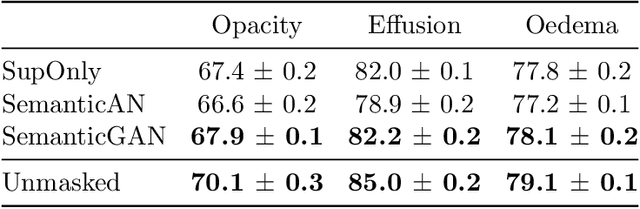

Image segmentation is important in medical imaging, providing valuable, quantitative information for clinical decision-making in diagnosis, therapy, and intervention. The state-of-the-art in automated segmentation remains supervised learning, employing discriminative models such as U-Net. However, training these models requires access to large amounts of manually labelled data which is often difficult to obtain in real medical applications. In such settings, semi-supervised learning (SSL) attempts to leverage the abundance of unlabelled data to obtain more robust and reliable models. Recently, generative models have been proposed for semantic segmentation, as they make an attractive choice for SSL. Their ability to capture the joint distribution over input images and output label maps provides a natural way to incorporate information from unlabelled images. This paper analyses whether deep generative models such as the SemanticGAN are truly viable alternatives to tackle challenging medical image segmentation problems. To that end, we thoroughly evaluate the segmentation performance, robustness, and potential subgroup disparities of discriminative and generative segmentation methods when applied to large-scale, publicly available chest X-ray datasets.
Learning with Capsules: A Survey
Jun 06, 2022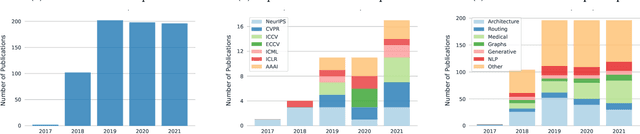
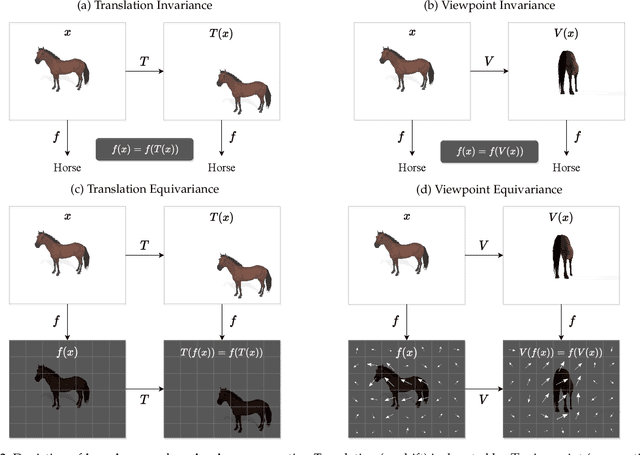
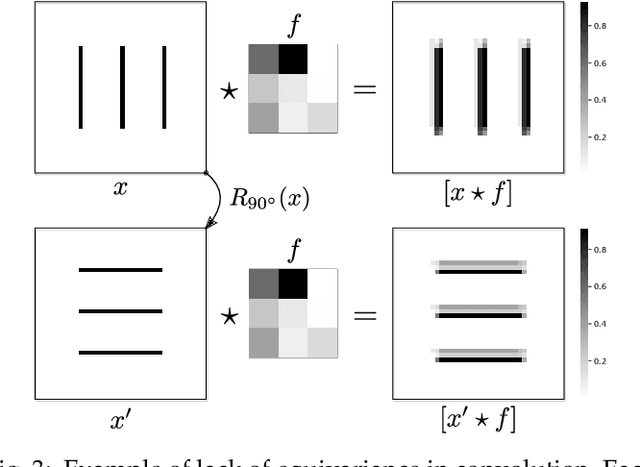
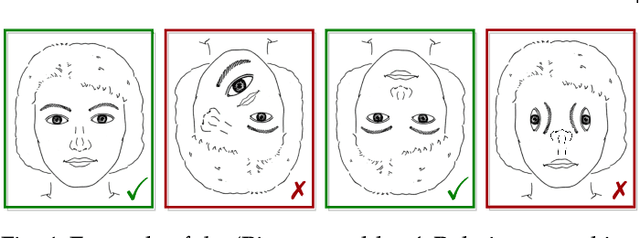
Capsule networks were proposed as an alternative approach to Convolutional Neural Networks (CNNs) for learning object-centric representations, which can be leveraged for improved generalization and sample complexity. Unlike CNNs, capsule networks are designed to explicitly model part-whole hierarchical relationships by using groups of neurons to encode visual entities, and learn the relationships between those entities. Promising early results achieved by capsule networks have motivated the deep learning community to continue trying to improve their performance and scalability across several application areas. However, a major hurdle for capsule network research has been the lack of a reliable point of reference for understanding their foundational ideas and motivations. The aim of this survey is to provide a comprehensive overview of the capsule network research landscape, which will serve as a valuable resource for the community going forward. To that end, we start with an introduction to the fundamental concepts and motivations behind capsule networks, such as equivariant inference in computer vision. We then cover the technical advances in the capsule routing mechanisms and the various formulations of capsule networks, e.g. generative and geometric. Additionally, we provide a detailed explanation of how capsule networks relate to the popular attention mechanism in Transformers, and highlight non-trivial conceptual similarities between them in the context of representation learning. Afterwards, we explore the extensive applications of capsule networks in computer vision, video and motion, graph representation learning, natural language processing, medical imaging and many others. To conclude, we provide an in-depth discussion regarding the main hurdles in capsule network research, and highlight promising research directions for future work.
Failure Detection in Medical Image Classification: A Reality Check and Benchmarking Testbed
May 27, 2022
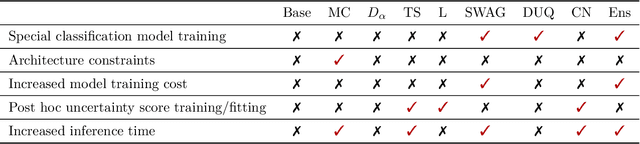

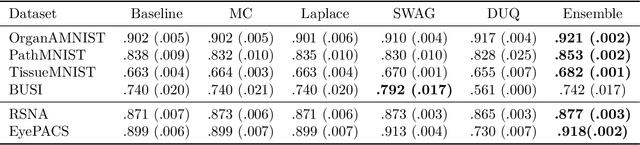
Failure detection in automated image classification is a critical safeguard for clinical deployment. Detected failure cases can be referred to human assessment, ensuring patient safety in computer-aided clinical decision making. Despite its paramount importance, there is insufficient evidence about the ability of state-of-the-art confidence scoring methods to detect test-time failures of classification models in the context of medical imaging. This paper provides a reality check, establishing the performance of in-domain misclassification detection methods, benchmarking 9 confidence scores on 6 medical imaging datasets with different imaging modalities, in multiclass and binary classification settings. Our experiments show that the problem of failure detection is far from being solved. We found that none of the benchmarked advanced methods proposed in the computer vision and machine learning literature can consistently outperform a simple softmax baseline. Our developed testbed facilitates future work in this important area.
Capsule Routing via Variational Bayes
May 27, 2019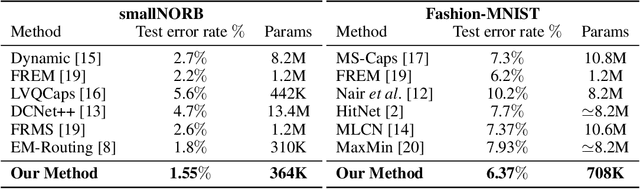
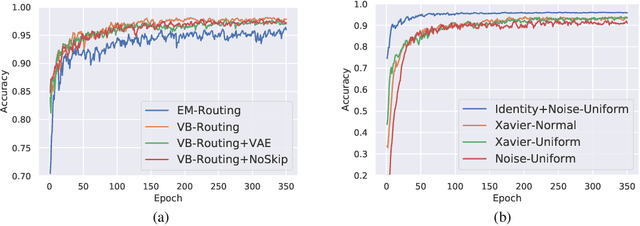
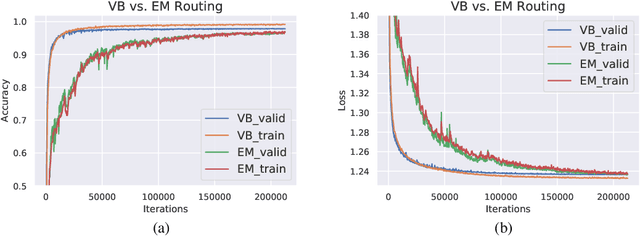
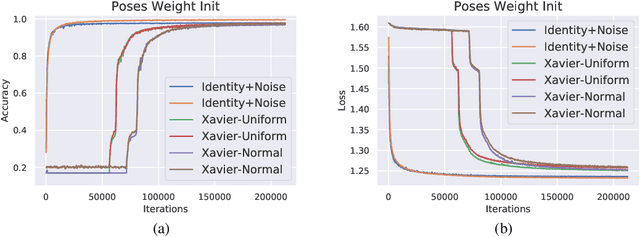
Capsule Networks are a recently proposed alternative for constructing Neural Networks, and early indications suggest that they can provide greater generalisation capacity using fewer parameters. In capsule networks scalar neurons are replaced with capsule vectors or matrices, whose entries represent different properties of objects. The relationships between objects and its parts are learned via trainable viewpoint-invariant transformation matrices, and the presence of a given object is decided by the level of agreement among votes from its parts. This interaction occurs between capsule layers and is a process called routing-by-agreement. Although promising, capsule networks remain underexplored by the community, and in this paper we present a new capsule routing algorithm based of Variational Bayes for a mixture of transforming gaussians. Our Bayesian approach addresses some of the inherent weaknesses of EM routing such as the 'variance collapse' by modelling uncertainty over the capsule parameters in addition to the routing assignment posterior probabilities. We test our method on public domain datasets and outperform the state-of-the-art performance on smallNORB using 50% less capsules.