 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakhraddin Alwajih
Peacock: A Family of Arabic Multimodal Large Language Models and Benchmarks
Mar 01, 2024
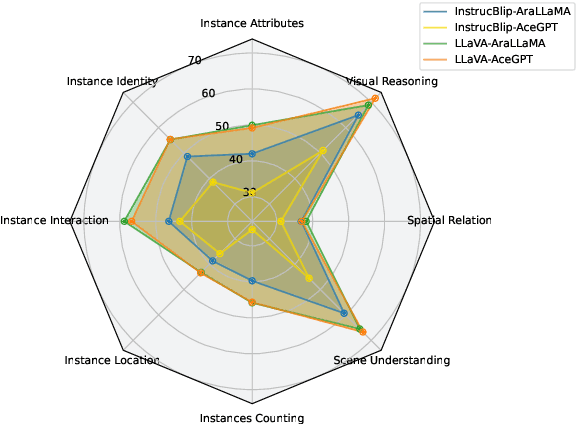
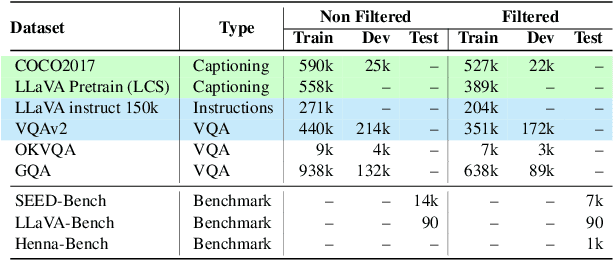
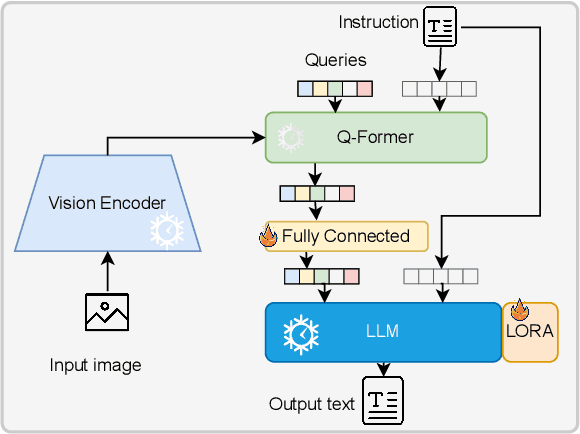
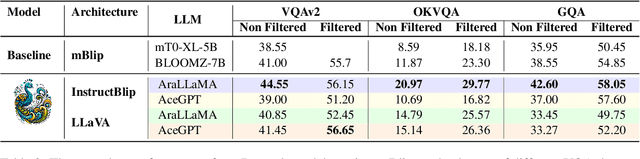
Multimodal large language models (MLLMs) have proven effective in a wide range of tasks requiring complex reasoning and linguistic comprehension. However, due to a lack of high-quality multimodal resources in languages other than English, success of MLLMs remains relatively limited to English-based settings. This poses significant challenges in developing comparable models for other languages, including even those with large speaker populations such as Arabic. To alleviate this challenge, we introduce a comprehensive family of Arabic MLLMs, dubbed \textit{Peacock}, with strong vision and language capabilities. Through comprehensive qualitative and quantitative analysis, we demonstrate the solid performance of our models on various visual reasoning tasks and further show their emerging dialectal potential. Additionally, we introduce ~\textit{Henna}, a new benchmark specifically designed for assessing MLLMs on aspects related to Arabic culture, setting the first stone for culturally-aware Arabic MLLMs.The GitHub repository for the \textit{Peacock} project is available at \url{https://github.com/UBC-NLP/peacock}.
Violet: A Vision-Language Model for Arabic Image Captioning with Gemini Decoder
Nov 15, 2023Although image captioning has a vast array of applications, it has not reached its full potential in languages other than English. Arabic, for instance, although the native language of more than 400 million people, remains largely underrepresented in this area. This is due to the lack of labeled data and powerful Arabic generative models. We alleviate this issue by presenting a novel vision-language model dedicated to Arabic, dubbed \textit{Violet}. Our model is based on a vision encoder and a Gemini text decoder that maintains generation fluency while allowing fusion between the vision and language components. To train our model, we introduce a new method for automatically acquiring data from available English datasets. We also manually prepare a new dataset for evaluation. \textit{Violet} performs sizeably better than our baselines on all of our evaluation datasets. For example, it reaches a CIDEr score of $61.2$ on our manually annotated dataset and achieves an improvement of $13$ points on Flickr8k.