 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFangzhen Lin
Adjustable Robust Reinforcement Learning for Online 3D Bin Packing
Oct 06, 2023
Designing effective policies for the online 3D bin packing problem (3D-BPP) has been a long-standing challenge, primarily due to the unpredictable nature of incoming box sequences and stringent physical constraints. While current deep reinforcement learning (DRL) methods for online 3D-BPP have shown promising results in optimizing average performance over an underlying box sequence distribution, they often fail in real-world settings where some worst-case scenarios can materialize. Standard robust DRL algorithms tend to overly prioritize optimizing the worst-case performance at the expense of performance under normal problem instance distribution. To address these issues, we first introduce a permutation-based attacker to investigate the practical robustness of both DRL-based and heuristic methods proposed for solving online 3D-BPP. Then, we propose an adjustable robust reinforcement learning (AR2L) framework that allows efficient adjustment of robustness weights to achieve the desired balance of the policy's performance in average and worst-case environments. Specifically, we formulate the objective function as a weighted sum of expected and worst-case returns, and derive the lower performance bound by relating to the return under a mixture dynamics. To realize this lower bound, we adopt an iterative procedure that searches for the associated mixture dynamics and improves the corresponding policy. We integrate this procedure into two popular robust adversarial algorithms to develop the exact and approximate AR2L algorithms. Experiments demonstrate that AR2L is versatile in the sense that it improves policy robustness while maintaining an acceptable level of performance for the nominal case.
On Computing Universal Plans for Partially Observable Multi-Agent Path Finding
May 25, 2023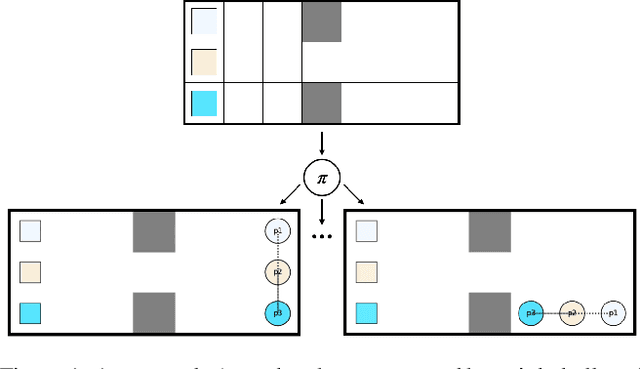
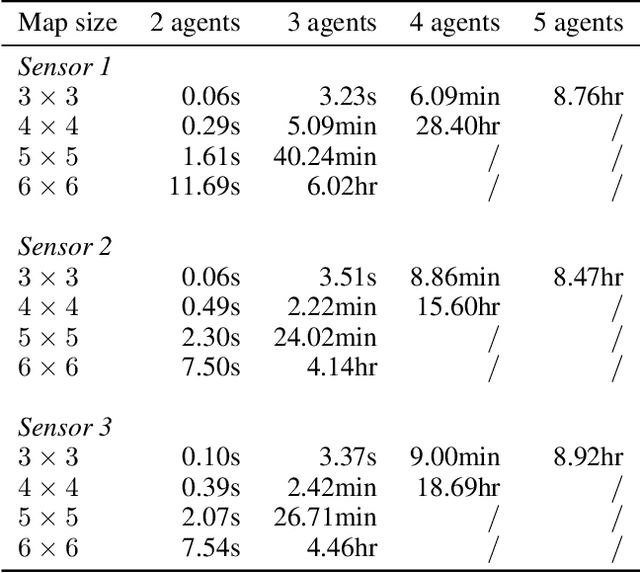
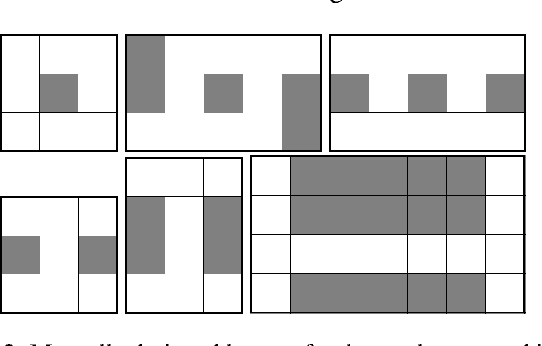
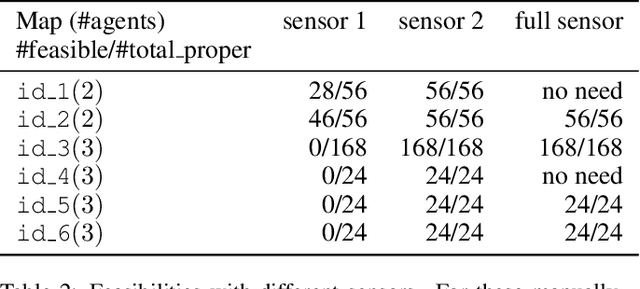
Multi-agent routing problems have drawn significant attention nowadays due to their broad industrial applications in, e.g., warehouse robots, logistics automation, and traffic control. Conventionally, they are modelled as classical planning problems. In this paper, we argue that it is beneficial to formulate them as universal planning problems. We therefore propose universal plans, also known as policies, as the solution concepts, and implement a system called ASP-MAUPF (Answer Set Programming for Multi-Agent Universal Plan Finding) for computing them. Given an arbitrary two-dimensional map and a profile of goals for the agents, the system finds a feasible universal plan for each agent that ensures no collision with others. We use the system to conduct some experiments, and make some observations on the types of goal profiles and environments that will have feasible policies, and how they may depend on agents' sensors. We also demonstrate how users can customize action preferences to compute more efficient policies, even (near-)optimal ones.
Using Language Models For Knowledge Acquisition in Natural Language Reasoning Problems
Apr 04, 2023For a natural language problem that requires some non-trivial reasoning to solve, there are at least two ways to do it using a large language model (LLM). One is to ask it to solve it directly. The other is to use it to extract the facts from the problem text and then use a theorem prover to solve it. In this note, we compare the two methods using ChatGPT and GPT4 on a series of logic word puzzles, and conclude that the latter is the right approach.
Backward Imitation and Forward Reinforcement Learning via Bi-directional Model Rollouts
Aug 04, 2022



Traditional model-based reinforcement learning (RL) methods generate forward rollout traces using the learnt dynamics model to reduce interactions with the real environment. The recent model-based RL method considers the way to learn a backward model that specifies the conditional probability of the previous state given the previous action and the current state to additionally generate backward rollout trajectories. However, in this type of model-based method, the samples derived from backward rollouts and those from forward rollouts are simply aggregated together to optimize the policy via the model-free RL algorithm, which may decrease both the sample efficiency and the convergence rate. This is because such an approach ignores the fact that backward rollout traces are often generated starting from some high-value states and are certainly more instructive for the agent to improve the behavior. In this paper, we propose the backward imitation and forward reinforcement learning (BIFRL) framework where the agent treats backward rollout traces as expert demonstrations for the imitation of excellent behaviors, and then collects forward rollout transitions for policy reinforcement. Consequently, BIFRL empowers the agent to both reach to and explore from high-value states in a more efficient manner, and further reduces the real interactions, making it potentially more suitable for real-robot learning. Moreover, a value-regularized generative adversarial network is introduced to augment the valuable states which are infrequently received by the agent. Theoretically, we provide the condition where BIFRL is superior to the baseline methods. Experimentally, we demonstrate that BIFRL acquires the better sample efficiency and produces the competitive asymptotic performance on various MuJoCo locomotion tasks compared against state-of-the-art model-based methods.
PocketNN: Integer-only Training and Inference of Neural Networks via Direct Feedback Alignment and Pocket Activations in Pure C++
Jan 08, 2022
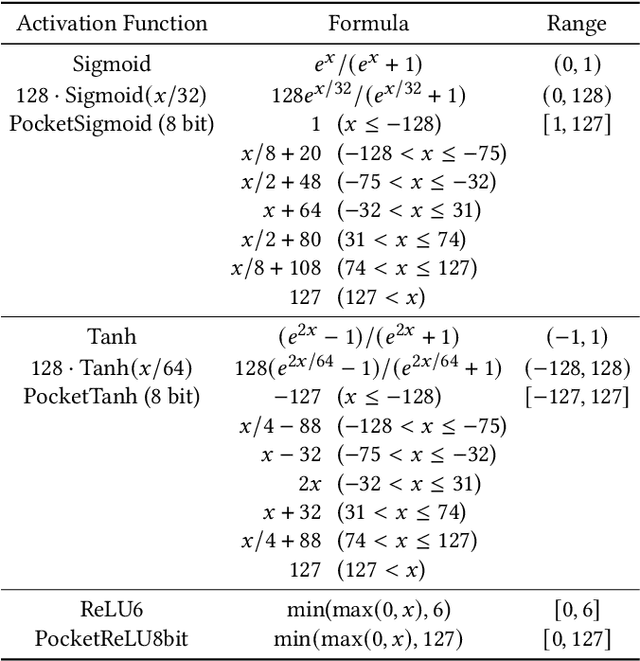
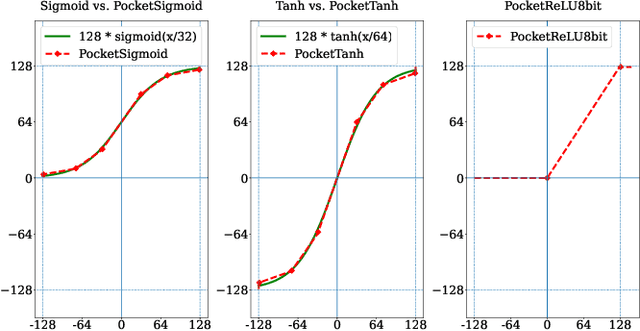

Standard deep learning algorithms are implemented using floating-point real numbers. This presents an obstacle for implementing them on low-end devices which may not have dedicated floating-point units (FPUs). As a result, researchers in TinyML have considered machine learning algorithms that can train and run a deep neural network (DNN) on a low-end device using integer operations only. In this paper we propose PocketNN, a light and self-contained proof-of-concept framework in pure C++ for the training and inference of DNNs using only integers. Unlike other approaches, PocketNN directly operates on integers without requiring any explicit quantization algorithms or customized fixed-point formats. This was made possible by pocket activations, which are a family of activation functions devised for integer-only DNNs, and an emerging DNN training algorithm called direct feedback alignment (DFA). Unlike the standard backpropagation (BP), DFA trains each layer independently, thus avoiding integer overflow which is a key problem when using BP with integer-only operations. We used PocketNN to train some DNNs on two well-known datasets, MNIST and Fashion-MNIST. Our experiments show that the DNNs trained with our PocketNN achieved 96.98% and 87.7% accuracies on MNIST and Fashion-MNIST datasets, respectively. The accuracies are very close to the equivalent DNNs trained using BP with floating-point real number operations, such that accuracy degradations were just 1.02%p and 2.09%p, respectively. Finally, our PocketNN has high compatibility and portability for low-end devices as it is open source and implemented in pure C++ without any dependencies.
Computing Class Hierarchies from Classifiers
Dec 02, 2021
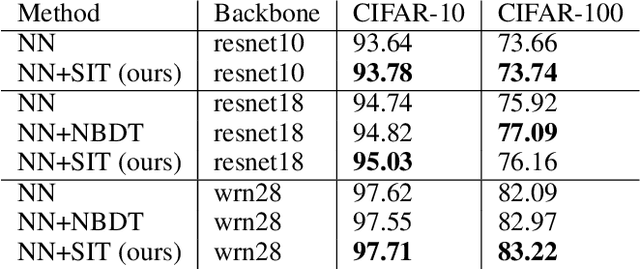
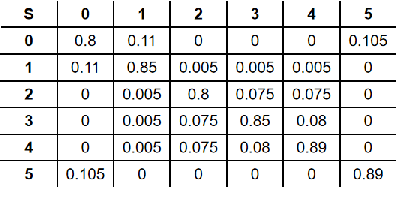

A class or taxonomic hierarchy is often manually constructed, and part of our knowledge about the world. In this paper, we propose a novel algorithm for automatically acquiring a class hierarchy from a classifier which is often a large neural network these days. The information that we need from a classifier is its confusion matrix which contains, for each pair of base classes, the number of errors the classifier makes by mistaking one for another. Our algorithm produces surprisingly good hierarchies for some well-known deep neural network models trained on the CIFAR-10 dataset, a neural network model for predicting the native language of a non-native English speaker, a neural network model for detecting the language of a written text, and a classifier for identifying music genre. In the literature, such class hierarchies have been used to provide interpretability to the neural networks. We also discuss some other potential uses of the acquired hierarchies.
XRJL-HKUST at SemEval-2021 Task 4: WordNet-Enhanced Dual Multi-head Co-Attention for Reading Comprehension of Abstract Meaning
Mar 30, 2021
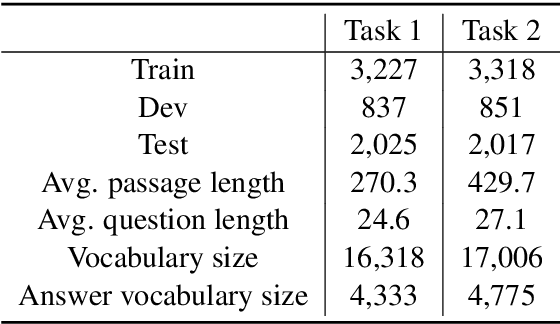

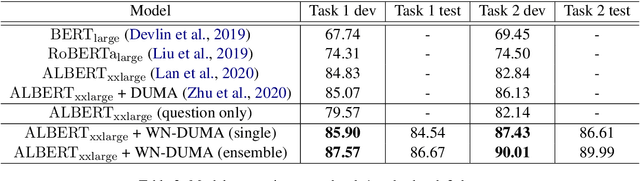
This paper presents our submitted system to SemEval 2021 Task 4: Reading Comprehension of Abstract Meaning. Our system uses a large pre-trained language model as the encoder and an additional dual multi-head co-attention layer to strengthen the relationship between passages and question-answer pairs, following the current state-of-the-art model DUMA. The main difference is that we stack the passage-question and question-passage attention modules instead of calculating parallelly to simulate re-considering process. We also add a layer normalization module to improve the performance of our model. Furthermore, to incorporate our known knowledge about abstract concepts, we retrieve the definitions of candidate answers from WordNet and feed them to the model as extra inputs. Our system, called WordNet-enhanced DUal Multi-head Co-Attention (WN-DUMA), achieves 86.67% and 89.99% accuracy on the official blind test set of subtask 1 and subtask 2 respectively.
Faster and Safer Training by Embedding High-Level Knowledge into Deep Reinforcement Learning
Oct 22, 2019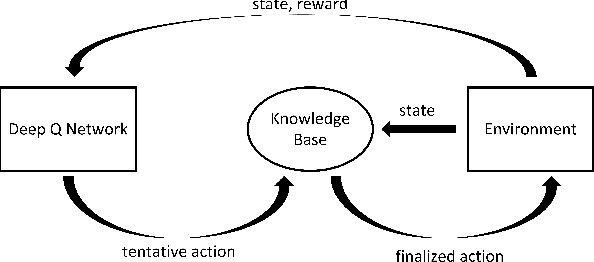
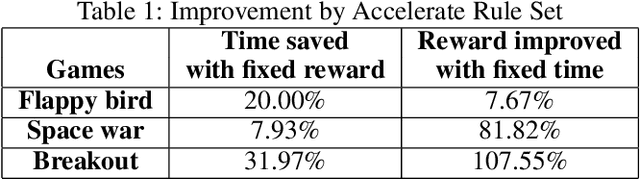

Deep reinforcement learning has been successfully used in many dynamic decision making domains, especially those with very large state spaces. However, it is also well-known that deep reinforcement learning can be very slow and resource intensive. The resulting system is often brittle and difficult to explain. In this paper, we attempt to address some of these problems by proposing a framework of Rule-interposing Learning (RIL) that embeds high level rules into the deep reinforcement learning. With some good rules, this framework not only can accelerate the learning process, but also keep it away from catastrophic explorations, thus making the system relatively stable even during the very early stage of training. Moreover, given the rules are high level and easy to interpret, they can be easily maintained, updated and shared with other similar tasks.
Recycling Computed Answers in Rewrite Systems for Abduction
Feb 16, 2004



In rule-based systems, goal-oriented computations correspond naturally to the possible ways that an observation may be explained. In some applications, we need to compute explanations for a series of observations with the same domain. The question whether previously computed answers can be recycled arises. A yes answer could result in substantial savings of repeated computations. For systems based on classic logic, the answer is YES. For nonmonotonic systems however, one tends to believe that the answer should be NO, since recycling is a form of adding information. In this paper, we show that computed answers can always be recycled, in a nontrivial way, for the class of rewrite procedures that we proposed earlier for logic programs with negation. We present some experimental results on an encoding of the logistics domain.