 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaramarz Fekri
Learning Cyclic Causal Models from Incomplete Data
Feb 23, 2024
Causal learning is a fundamental problem in statistics and science, offering insights into predicting the effects of unseen treatments on a system. Despite recent advances in this topic, most existing causal discovery algorithms operate under two key assumptions: (i) the underlying graph is acyclic, and (ii) the available data is complete. These assumptions can be problematic as many real-world systems contain feedback loops (e.g., biological systems), and practical scenarios frequently involve missing data. In this work, we propose a novel framework, named MissNODAGS, for learning cyclic causal graphs from partially missing data. Under the additive noise model, MissNODAGS learns the causal graph by alternating between imputing the missing data and maximizing the expected log-likelihood of the visible part of the data in each training step, following the principles of the expectation-maximization (EM) framework. Through synthetic experiments and real-world single-cell perturbation data, we demonstrate improved performance when compared to using state-of-the-art imputation techniques followed by causal learning on partially missing interventional data.
TILP: Differentiable Learning of Temporal Logical Rules on Knowledge Graphs
Feb 19, 2024Compared with static knowledge graphs, temporal knowledge graphs (tKG), which can capture the evolution and change of information over time, are more realistic and general. However, due to the complexity that the notion of time introduces to the learning of the rules, an accurate graph reasoning, e.g., predicting new links between entities, is still a difficult problem. In this paper, we propose TILP, a differentiable framework for temporal logical rules learning. By designing a constrained random walk mechanism and the introduction of temporal operators, we ensure the efficiency of our model. We present temporal features modeling in tKG, e.g., recurrence, temporal order, interval between pair of relations, and duration, and incorporate it into our learning process. We compare TILP with state-of-the-art methods on two benchmark datasets. We show that our proposed framework can improve upon the performance of baseline methods while providing interpretable results. In particular, we consider various scenarios in which training samples are limited, data is biased, and the time range between training and inference are different. In all these cases, TILP works much better than the state-of-the-art methods.
Large Language Models Can Learn Temporal Reasoning
Jan 12, 2024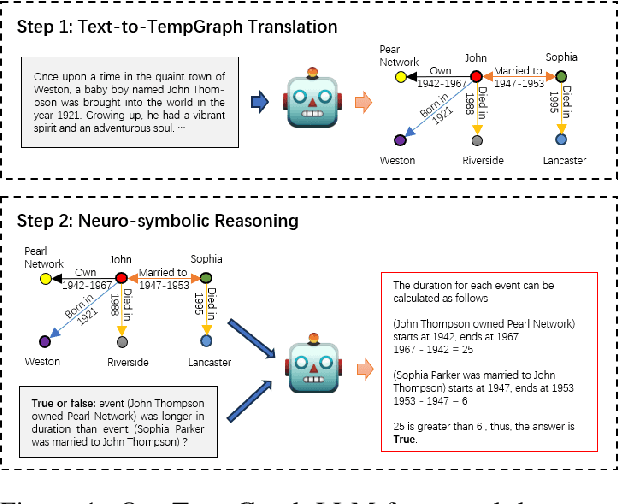



Large language models (LLMs) learn temporal concepts from the co-occurrence of related tokens in a sequence. Compared with conventional text generation, temporal reasoning, which reaches a conclusion based on mathematical, logical and commonsense knowledge, is more challenging. In this paper, we propose TempGraph-LLM, a new paradigm towards text-based temporal reasoning. To be specific, we first teach LLMs to translate the context into a temporal graph. A synthetic dataset, which is fully controllable and requires minimal supervision, is constructed for pre-training on this task. We prove in experiments that LLMs benefit from the pre-training on other tasks. On top of that, we guide LLMs to perform symbolic reasoning with the strategies of Chain of Thoughts (CoTs) bootstrapping and special data augmentation. We observe that CoTs with symbolic reasoning bring more consistent and reliable results than those using free text.
TEILP: Time Prediction over Knowledge Graphs via Logical Reasoning
Dec 25, 2023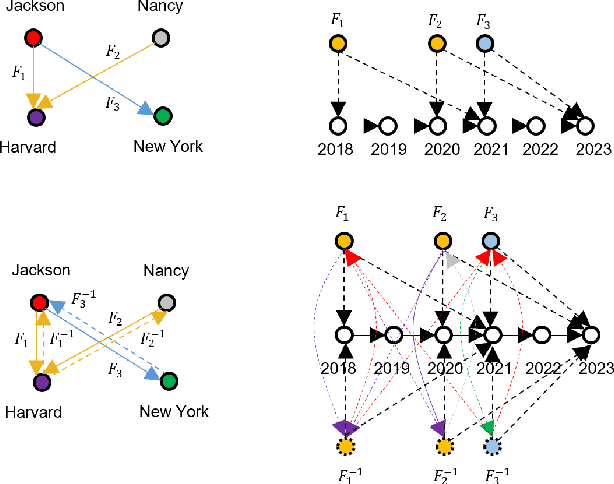
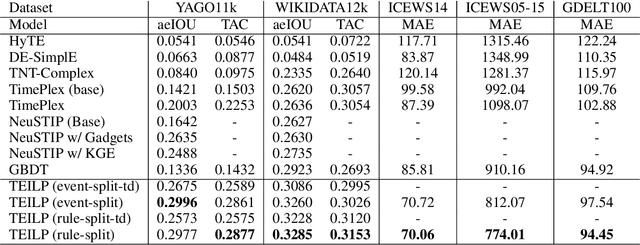
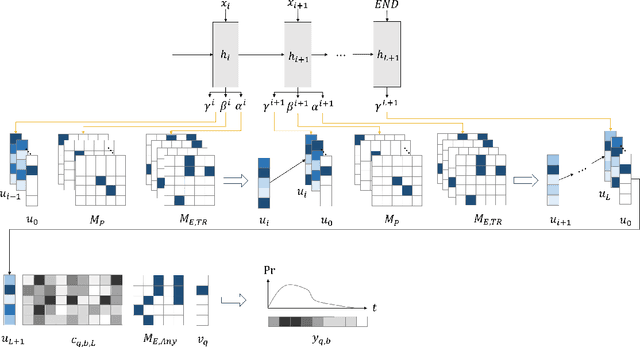
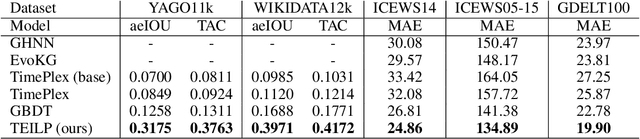
Conventional embedding-based models approach event time prediction in temporal knowledge graphs (TKGs) as a ranking problem. However, they often fall short in capturing essential temporal relationships such as order and distance. In this paper, we propose TEILP, a logical reasoning framework that naturaly integrates such temporal elements into knowledge graph predictions. We first convert TKGs into a temporal event knowledge graph (TEKG) which has a more explicit representation of time in term of nodes of the graph. The TEKG equips us to develop a differentiable random walk approach to time prediction. Finally, we introduce conditional probability density functions, associated with the logical rules involving the query interval, using which we arrive at the time prediction. We compare TEILP with state-of-the-art methods on five benchmark datasets. We show that our model achieves a significant improvement over baselines while providing interpretable explanations. In particular, we consider several scenarios where training samples are limited, event types are imbalanced, and forecasting the time of future events based on only past events is desired. In all these cases, TEILP outperforms state-of-the-art methods in terms of robustness.
Harnessing the Power of Large Language Models for Natural Language to First-Order Logic Translation
May 24, 2023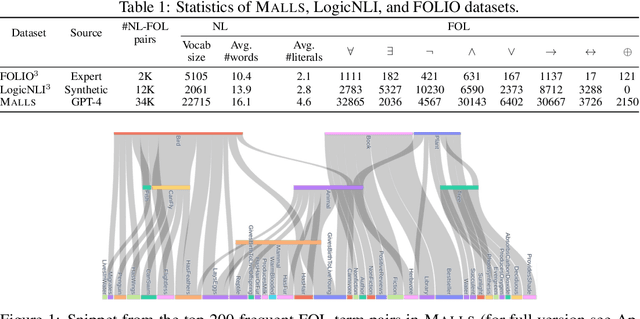

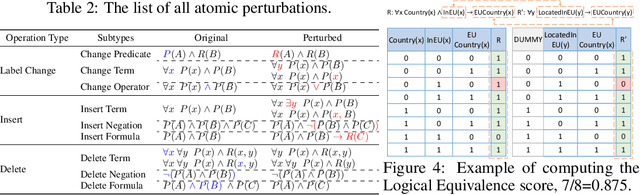
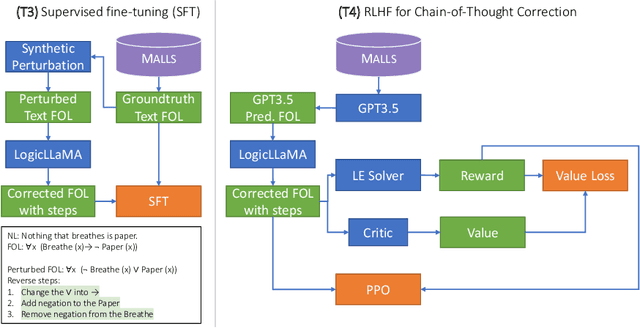
Translating natural language sentences to first-order logic (NL-FOL translation) is a longstanding challenge in the NLP and formal logic literature. This paper introduces LogicLLaMA, a LLaMA-7B model fine-tuned for NL-FOL translation using LoRA on a single GPU. LogicLLaMA is capable of directly translating natural language into FOL rules, which outperforms GPT-3.5. LogicLLaMA is also equipped to correct FOL rules predicted by GPT-3.5, and can achieve similar performance as GPT-4 with a fraction of the cost. This correction ability was achieved by a novel supervised fine-tuning (SFT) + reinforcement learning with human feedback (RLHF) framework, which initially trains on synthetically perturbed NL-FOL pairs to encourage chain-of-thought reasoning and then fine-tunes with RLHF on GPT-3.5 outputs using a FOL verifier as the reward model. To train LogicLLaMA, we present MALLS (large language $\textbf{M}$odel gener$\textbf{A}$ted N$\textbf{L}$-FO$\textbf{L}$ pair$\textbf{S}$), a dataset of 34K high-quality and diverse sentence-level NL-FOL pairs collected from GPT-4. The dataset was created by implementing a pipeline that prompts GPT-4 for pairs, and dynamically adjusts the prompts to ensure the collection of pairs with rich and diverse contexts at different levels of complexity, and verifies the validity of the generated FOL rules. Codes, weights, and data are available at $\href{https://github.com/gblackout/LogicLLaMA}{{\small \text{https://github.com/gblackout/LogicLLaMA}}}$.
NODAGS-Flow: Nonlinear Cyclic Causal Structure Learning
Jan 04, 2023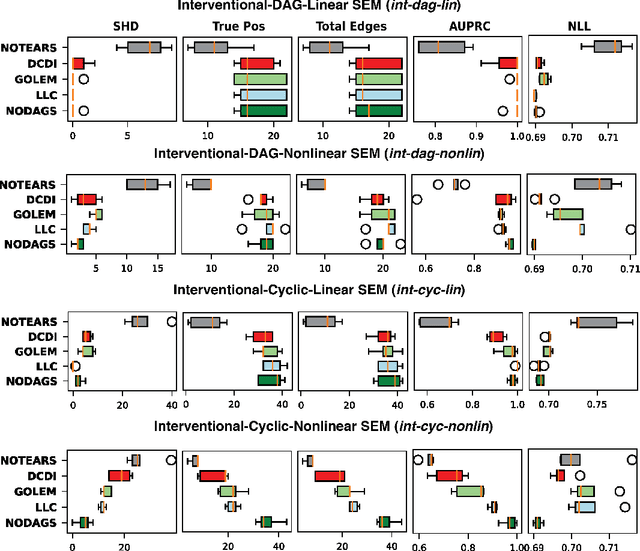
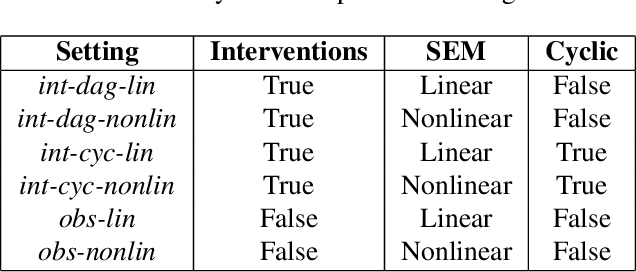
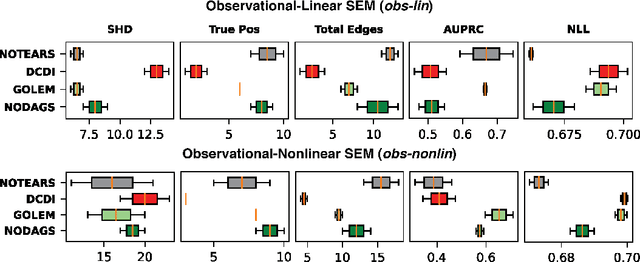

Learning causal relationships between variables is a well-studied problem in statistics, with many important applications in science. However, modeling real-world systems remain challenging, as most existing algorithms assume that the underlying causal graph is acyclic. While this is a convenient framework for developing theoretical developments about causal reasoning and inference, the underlying modeling assumption is likely to be violated in real systems, because feedback loops are common (e.g., in biological systems). Although a few methods search for cyclic causal models, they usually rely on some form of linearity, which is also limiting, or lack a clear underlying probabilistic model. In this work, we propose a novel framework for learning nonlinear cyclic causal graphical models from interventional data, called NODAGS-Flow. We perform inference via direct likelihood optimization, employing techniques from residual normalizing flows for likelihood estimation. Through synthetic experiments and an application to single-cell high-content perturbation screening data, we show significant performance improvements with our approach compared to state-of-the-art methods with respect to structure recovery and predictive performance.
Generalizing LTL Instructions via Future Dependent Options
Dec 15, 2022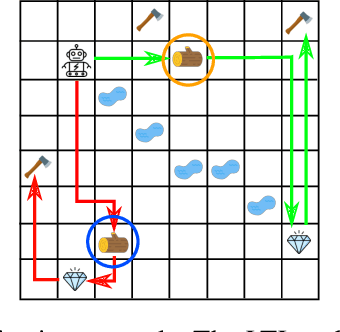
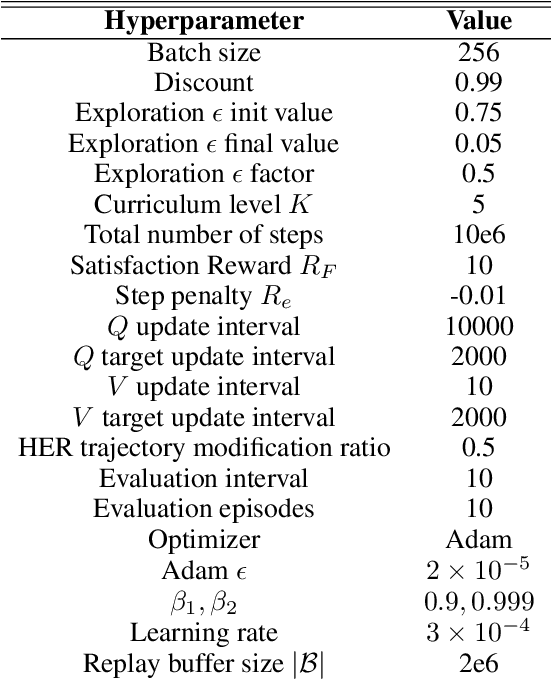

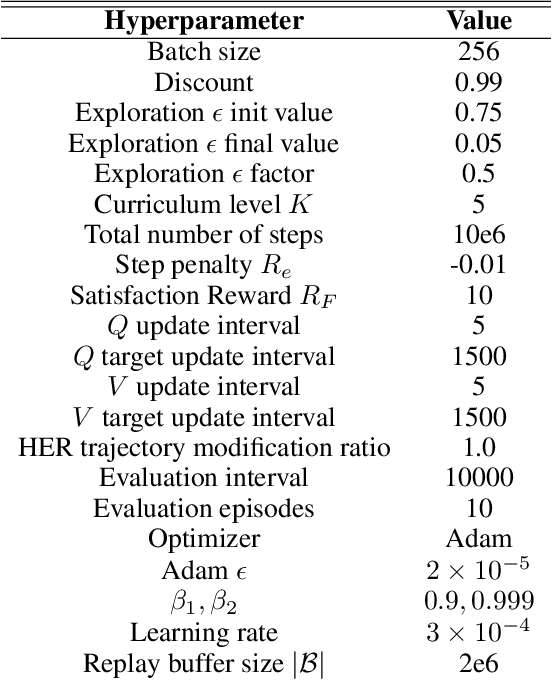
In many real-world applications of control system and robotics, linear temporal logic (LTL) is a widely-used task specification language which has a compositional grammar that naturally induces temporally extended behaviours across tasks, including conditionals and alternative realizations. An important problem in RL with LTL tasks is to learn task-conditioned policies which can zero-shot generalize to new LTL instructions not observed in the training. However, because symbolic observation is often lossy and LTL tasks can have long time horizon, previous works can suffer from issues such as training sampling inefficiency and infeasibility or sub-optimality of the found solutions. In order to tackle these issues, this paper proposes a novel multi-task RL algorithm with improved learning efficiency and optimality. To achieve the global optimality of task completion, we propose to learn options dependent on the future subgoals via a novel off-policy approach. In order to propagate the rewards of satisfying future subgoals back more efficiently, we propose to train a multi-step value function conditioned on the subgoal sequence which is updated with Monte Carlo estimates of multi-step discounted returns. In experiments on three different domains, we evaluate the LTL generalization capability of the agent trained by the proposed method, showing its advantage over previous representative methods.
Temporal Inductive Logic Reasoning
Jun 09, 2022
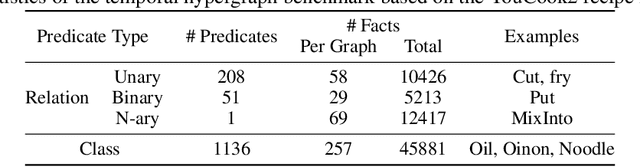
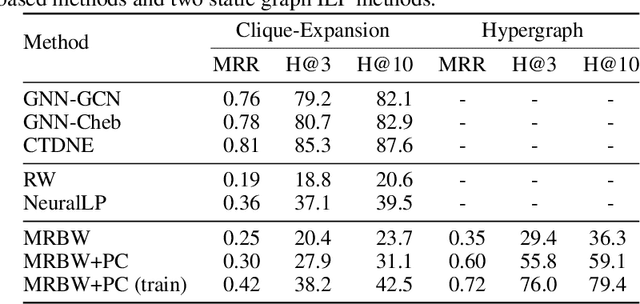
Inductive logic reasoning is one of the fundamental tasks on graphs, which seeks to generalize patterns from the data. This task has been studied extensively for traditional graph datasets such as knowledge graphs (KGs), with representative techniques such as inductive logic programming (ILP). Existing ILP methods typically assume learning from KGs with static facts and binary relations. Beyond KGs, graph structures are widely present in other applications such as video instructions, scene graphs and program executions. While inductive logic reasoning is also beneficial for these applications, applying ILP to the corresponding graphs is nontrivial: they are more complex than KGs, which usually involve timestamps and n-ary relations, effectively a type of hypergraph with temporal events. In this work, we study two of such applications and propose to represent them as hypergraphs with time intervals. To reason on this graph, we propose the multi-start random B-walk that traverses this hypergraph. Combining it with a path-consistency algorithm, we propose an efficient backward-chaining ILP method that learns logic rules by generalizing from both the temporal and the relational data.
Structure Learning in Graphical Models from Indirect Observations
May 06, 2022
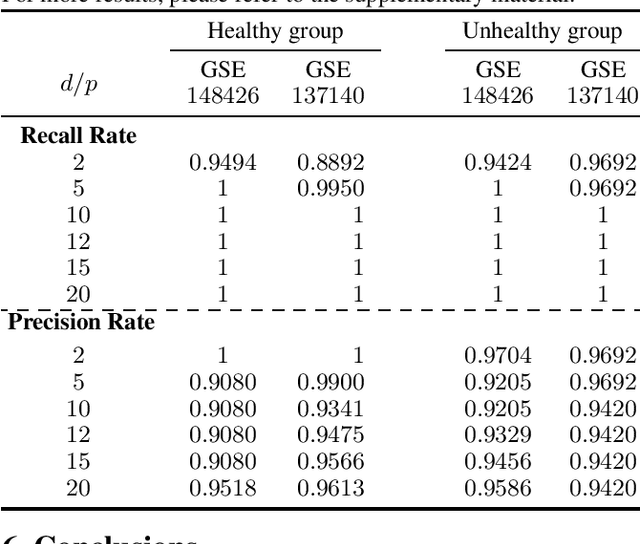
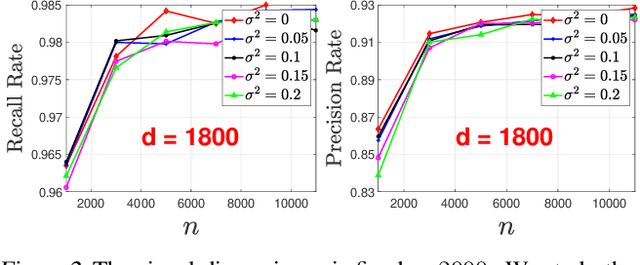

This paper considers learning of the graphical structure of a $p$-dimensional random vector $X \in R^p$ using both parametric and non-parametric methods. Unlike the previous works which observe $x$ directly, we consider the indirect observation scenario in which samples $y$ are collected via a sensing matrix $A \in R^{d\times p}$, and corrupted with some additive noise $w$, i.e, $Y = AX + W$. For the parametric method, we assume $X$ to be Gaussian, i.e., $x\in R^p\sim N(\mu, \Sigma)$ and $\Sigma \in R^{p\times p}$. For the first time, we show that the correct graphical structure can be correctly recovered under the indefinite sensing system ($d < p$) using insufficient samples ($n < p$). In particular, we show that for the exact recovery, we require dimension $d = \Omega(p^{0.8})$ and sample number $n = \Omega(p^{0.8}\log^3 p)$. For the nonparametric method, we assume a nonparanormal distribution for $X$ rather than Gaussian. Under mild conditions, we show that our graph-structure estimator can obtain the correct structure. We derive the minimum sample number $n$ and dimension $d$ as $n\gtrsim (deg)^4 \log^4 n$ and $d \gtrsim p + (deg\cdot\log(d-p))^{\beta/4}$, respectively, where deg is the maximum Markov blanket in the graphical model and $\beta > 0$ is some fixed positive constant. Additionally, we obtain a non-asymptotic uniform bound on the estimation error of the CDF of $X$ from indirect observations with inexact knowledge of the noise distribution. To the best of our knowledge, this bound is derived for the first time and may serve as an independent interest. Numerical experiments on both real-world and synthetic data are provided confirm the theoretical results.
A General Compressive Sensing Construct using Density Evolution
Apr 11, 2022

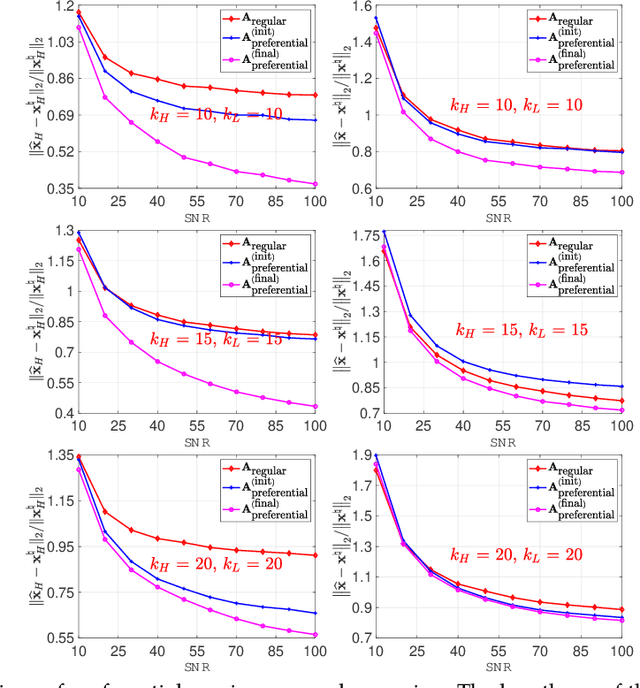
This paper proposes a general framework to design a sparse sensing matrix $\ensuremath{\mathbf{A}}\in \mathbb{R}^{m\times n}$, in a linear measurement system $\ensuremath{\mathbf{y}} = \ensuremath{\mathbf{Ax}}^{\natural} + \ensuremath{\mathbf{w}}$, where $\ensuremath{\mathbf{y}} \in \mathbb{R}^m$, $\ensuremath{\mathbf{x}}^{\natural}\in \RR^n$, and $\ensuremath{\mathbf{w}}$ denote the measurements, the signal with certain structures, and the measurement noise, respectively. By viewing the signal reconstruction from the measurements as a message passing algorithm over a graphical model, we leverage tools from coding theory in the design of low density parity check codes, namely the density evolution, and provide a framework for the design of matrix $\ensuremath{\mathbf{A}}$. Particularly, compared to the previous methods, our proposed framework enjoys the following desirable properties: ($i$) Universality: the design supports both regular sensing and preferential sensing, and incorporates them in a single framework; ($ii$) Flexibility: the framework can easily adapt the design of $\bA$ to a signal $\ensuremath{\mathbf{x}}^{\natural}$ with different underlying structures. As an illustration, we consider the $\ell_1$ regularizer, which correspond to Lasso, for both the regular sensing and preferential sensing scheme. Noteworthy, our framework can reproduce the classical result of Lasso, i.e., $m\geq c_0 k\log(n/k)$ (the regular sensing) with regular design after proper distribution approximation, where $c_0 > 0$ is some fixed constant. We also provide numerical experiments to confirm the analytical results and demonstrate the superiority of our framework whenever a preferential treatment of a sub-block of vector $\bx^{\natural}$ is required.