 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeiyang Jia
GraphBEV: Towards Robust BEV Feature Alignment for Multi-Modal 3D Object Detection
Mar 18, 2024
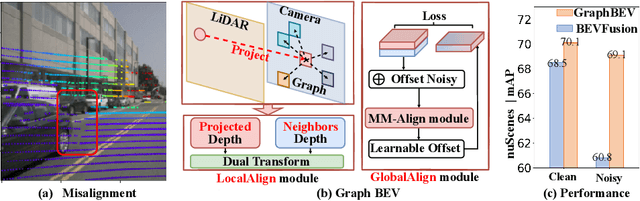
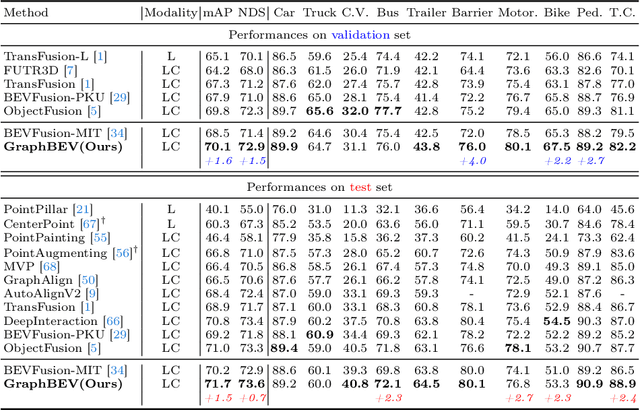
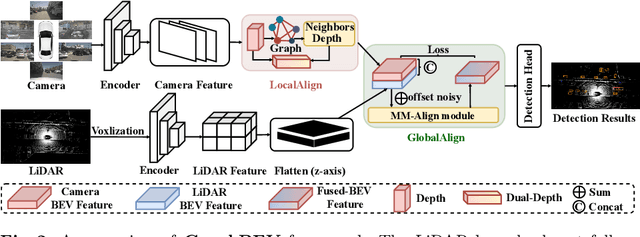
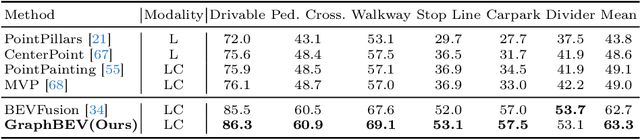
Integrating LiDAR and camera information into Bird's-Eye-View (BEV) representation has emerged as a crucial aspect of 3D object detection in autonomous driving. However, existing methods are susceptible to the inaccurate calibration relationship between LiDAR and the camera sensor. Such inaccuracies result in errors in depth estimation for the camera branch, ultimately causing misalignment between LiDAR and camera BEV features. In this work, we propose a robust fusion framework called Graph BEV. Addressing errors caused by inaccurate point cloud projection, we introduce a Local Align module that employs neighbor-aware depth features via Graph matching. Additionally, we propose a Global Align module to rectify the misalignment between LiDAR and camera BEV features. Our Graph BEV framework achieves state-of-the-art performance, with an mAP of 70.1\%, surpassing BEV Fusion by 1.6\% on the nuscenes validation set. Importantly, our Graph BEV outperforms BEV Fusion by 8.3\% under conditions with misalignment noise.
Robustness-Aware 3D Object Detection in Autonomous Driving: A Review and Outlook
Jan 12, 2024In the realm of modern autonomous driving, the perception system is indispensable for accurately assessing the state of the surrounding environment, thereby enabling informed prediction and planning. Key to this system is 3D object detection methods, that utilize vehicle-mounted sensors such as LiDAR and cameras to identify the size, category, and location of nearby objects. Despite the surge in 3D object detection methods aimed at enhancing detection precision and efficiency, there is a gap in the literature that systematically examines their resilience against environmental variations, noise, and weather changes. This study emphasizes the importance of robustness, alongside accuracy and latency, in evaluating perception systems under practical scenarios. Our work presents an extensive survey of camera-based, LiDAR-based, and multimodal 3D object detection algorithms, thoroughly evaluating their trade-off between accuracy, latency, and robustness, particularly on datasets like KITTI-C and nuScenes-C to ensure fair comparisons. Among these,multimodal 3D detection approaches exhibit superior robustness and a novel taxonomy is introduced to reorganize its literature for enhanced clarity. This survey aims to offer a more practical perspective on the current capabilities and constraints of 3D object detection algorithms in real-world applications, thus steering future research towards robustness-centric advancements
RoboFusion: Towards Robust Multi-Modal 3D obiect Detection via SAM
Jan 08, 2024Multi-modal 3D object detectors are dedicated to exploring secure and reliable perception systems for autonomous driving (AD). However, while achieving state-of-the-art (SOTA) performance on clean benchmark datasets, they tend to overlook the complexity and harsh conditions of real-world environments. Meanwhile, with the emergence of visual foundation models (VFMs), opportunities and challenges are presented for improving the robustness and generalization of multi-modal 3D object detection in autonomous driving. Therefore, we propose RoboFusion, a robust framework that leverages VFMs like SAM to tackle out-of-distribution (OOD) noise scenarios. We first adapt the original SAM for autonomous driving scenarios named SAM-AD. To align SAM or SAM-AD with multi-modal methods, we then introduce AD-FPN for upsampling the image features extracted by SAM. We employ wavelet decomposition to denoise the depth-guided images for further noise reduction and weather interference. Lastly, we employ self-attention mechanisms to adaptively reweight the fused features, enhancing informative features while suppressing excess noise. In summary, our RoboFusion gradually reduces noise by leveraging the generalization and robustness of VFMs, thereby enhancing the resilience of multi-modal 3D object detection. Consequently, our RoboFusion achieves state-of-the-art performance in noisy scenarios, as demonstrated by the KITTI-C and nuScenes-C benchmarks.