 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFelix Wichmann
Estimation of perceptual scales using ordinal embedding
Aug 21, 2019
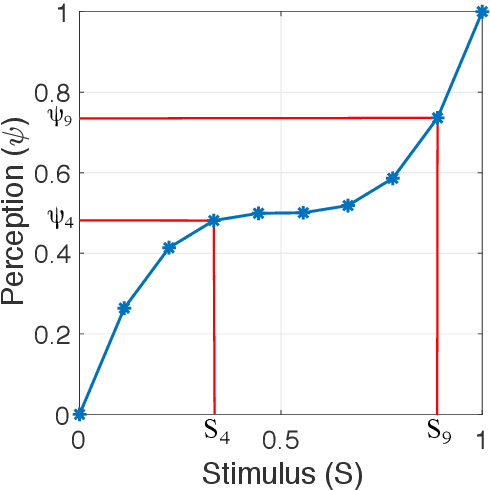

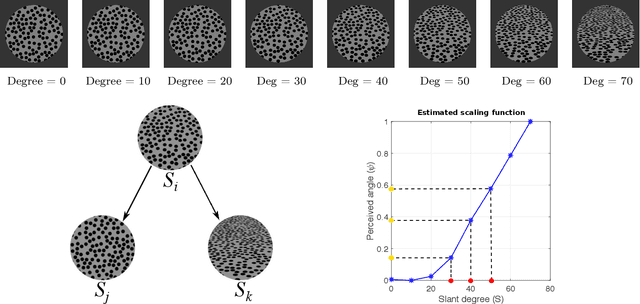

In this paper, we address the problem of measuring and analysing sensation, the subjective magnitude of one's experience. We do this in the context of the method of triads: the sensation of the stimulus is evaluated via relative judgments of the form: "Is stimulus S_i more similar to stimulus S_j or to stimulus S_k?". We propose to use ordinal embedding methods from machine learning to estimate the scaling function from the relative judgments. We review two relevant and well-known methods in psychophysics which are partially applicable in our setting: non-metric multi-dimensional scaling (NMDS) and the method of maximum likelihood difference scaling (MLDS). We perform an extensive set of simulations, considering various scaling functions, to demonstrate the performance of the ordinal embedding methods. We show that in contrast to existing approaches our ordinal embedding approach allows, first, to obtain reasonable scaling function from comparatively few relative judgments, second, the estimation of non-monotonous scaling functions, and, third, multi-dimensional perceptual scales. In addition to the simulations, we analyse data from two real psychophysics experiments using ordinal embedding methods. Our results show that in the one-dimensional, monotonically increasing perceptual scale our ordinal embedding approach works as well as MLDS, while in higher dimensions, only our ordinal embedding methods can produce a desirable scaling function. To make our methods widely accessible, we provide an R-implementation and general rules of thumb on how to use ordinal embedding in the context of psychophysics.
Comparison-Based Framework for Psychophysics: Lab versus Crowdsourcing
May 17, 2019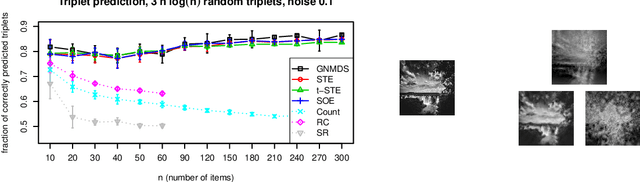
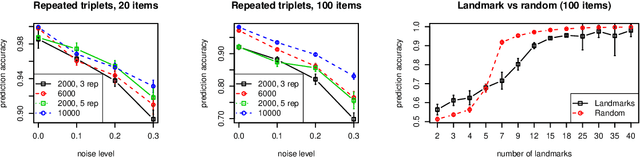
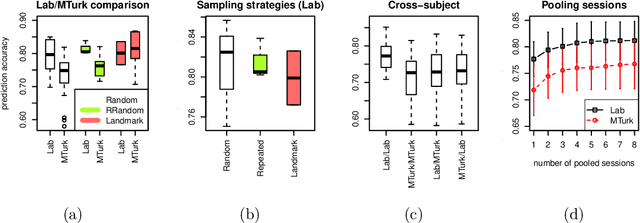
Traditionally, psychophysical experiments are conducted by repeated measurements on a few well-trained participants under well-controlled conditions, often resulting in, if done properly, high quality data. In recent years, however, crowdsourcing platforms are becoming increasingly popular means of data collection, measuring many participants at the potential cost of obtaining data of worse quality. In this paper we study whether the use of comparison-based (ordinal) data, combined with machine learning algorithms, can boost the reliability of crowdsourcing studies for psychophysics, such that they can achieve performance close to a lab experiment. To this end, we compare three setups: simulations, a psychophysics lab experiment, and the same experiment on Amazon Mechanical Turk. All these experiments are conducted in a comparison-based setting where participants have to answer triplet questions of the form "is object x closer to y or to z?". We then use machine learning to solve the triplet prediction problem: given a subset of triplet questions with corresponding answers, we predict the answer to the remaining questions. Considering the limitations and noise on MTurk, we find that the accuracy of triplet prediction is surprisingly close---but not equal---to our lab study.