 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeng Ji
Online Signed Sampling of Bandlimited Graph Signals
Feb 19, 2024
The theory of sampling and recovery of bandlimited graph signals has been extensively studied. However, in many cases, the observation of a signal is quite coarse. For example, users only provide simple comments such as "like" or "dislike" for a product on an e-commerce platform. This is a particular scenario where only the sign information of a graph signal can be measured. In this paper, we are interested in how to sample based on sign information in an online manner, by which the direction of the original graph signal can be estimated. The online signed sampling problem of a graph signal can be formulated as a Markov decision process in a finite horizon. Unfortunately, it is intractable for large size graphs. We propose a low-complexity greedy signed sampling algorithm (GSS) as well as a stopping criterion. Meanwhile, we prove that the objective function is adaptive monotonic and adaptive submodular, so that the performance is close enough to the global optimum with a lower bound. Finally, we demonstrate the effectiveness of the GSS algorithm by both synthesis and realworld data.
Lossless digraph signal processing via polar decomposition
Dec 30, 2023In this paper, we present a signal processing framework for directed graphs. Unlike undirected graphs, a graph shift operator such as the adjacency matrix associated with a directed graph usually does not admit an orthogonal eigenbasis. This makes it challenging to define the Fourier transform. Our methodology leverages the polar decomposition to define two distinct eigendecompositions, each associated with different matrices derived from this decomposition. We propose to extend the frequency domain and introduce a Fourier transform that jointly encodes the spectral response of a signal for the two eigenbases from the polar decomposition. This allows us to define convolution following a standard routine. Our approach has two features: it is lossless as the shift operator can be fully recovered from factors of the polar decomposition. Moreover, it subsumes the traditional graph signal processing if the graph is directed. We present numerical results to show how the framework can be applied.
Sparse graph sequences, generalized graphons and signal processing
Dec 21, 2023Graphons are limit objects of sequences of graphs, used to analyze the behavior of large graphs. Recently, graphon signal processing has been developed to study large graphs from the signal processing perspective. However, it has the shortcoming that any sparse sequence of graphs always converges to the zero graphon, and the resulting signal processing theory is trivial. In this paper, we propose a signal processing framework based on the generalized graphon theory. The main ingredient is to use the stretched cut distance to compare these graphons. We focus on sampling graph sequences from generalized graphons, and discuss convergence results of associated operators, spectrum as well as signals. Though the paper is theoretical, we also discuss what the theory implies for real large networks.
Graph Neural Networks with a Distribution of Parametrized Graphs
Oct 28, 2023Traditionally, graph neural networks have been trained using a single observed graph. However, the observed graph represents only one possible realization. In many applications, the graph may encounter uncertainties, such as having erroneous or missing edges, as well as edge weights that provide little informative value. To address these challenges and capture additional information previously absent in the observed graph, we introduce latent variables to parameterize and generate multiple graphs. We obtain the maximum likelihood estimate of the network parameters in an Expectation-Maximization (EM) framework based on the multiple graphs. Specifically, we iteratively determine the distribution of the graphs using a Markov Chain Monte Carlo (MCMC) method, incorporating the principles of PAC-Bayesian theory. Numerical experiments demonstrate improvements in performance against baseline models on node classification for heterogeneous graphs and graph regression on chemistry datasets.
Comments on "Graphon Signal Processing''
Oct 23, 2023This correspondence points out a technical error in Proposition 4 of the paper [1]. Because of this error, the proofs of Lemma 3, Theorem 1, Theorem 3, Proposition 2, and Theorem 4 in that paper are no longer valid. We provide counterexamples to Proposition 4 and discuss where the flaw in its proof lies. We also provide numerical evidence indicating that Lemma 3, Theorem 1, and Proposition 2 are likely to be false. Since the proof of Theorem 4 depends on the validity of Proposition 4, we propose an amendment to the statement of Theorem 4 of the paper using convergence in operator norm and prove this rigorously. In addition, we also provide a construction that guarantees convergence in the sense of Proposition 4.
Frequency Convergence of Complexon Shift Operators (Extended Version)
Sep 15, 2023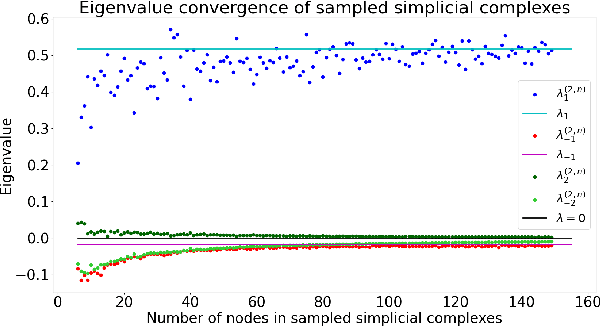
Topological Signal Processing (TSP) utilizes simplicial complexes to model structures with higher order than vertices and edges. In this paper, we study the transferability of TSP via a generalized higher-order version of graphon, known as complexon. We recall the notion of a complexon as the limit of a simplicial complex sequence. Inspired by the integral operator form of graphon shift operators, we construct a marginal complexon and complexon shift operator (CSO) according to components of all possible dimensions from the complexon. We investigate the CSO's eigenvalues and eigenvectors, and relate them to a new family of weighted adjacency matrices. We prove that when a simplicial complex sequence converges to a complexon, the eigenvalues of the corresponding CSOs converge to that of the limit complexon. This conclusion is further verified by a numerical experiment. These results hint at learning transferability on large simplicial complexes or simplicial complex sequences, which generalize the graphon signal processing framework.
Generalized Graphon Process: Convergence of Graph Frequencies in Stretched Cut Distance
Sep 11, 2023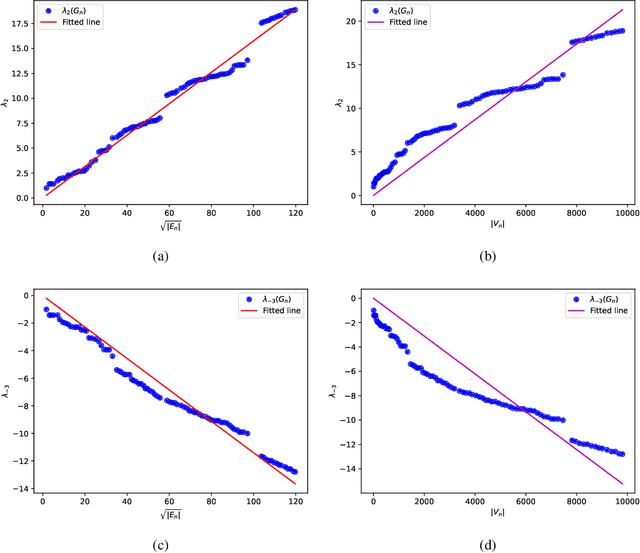
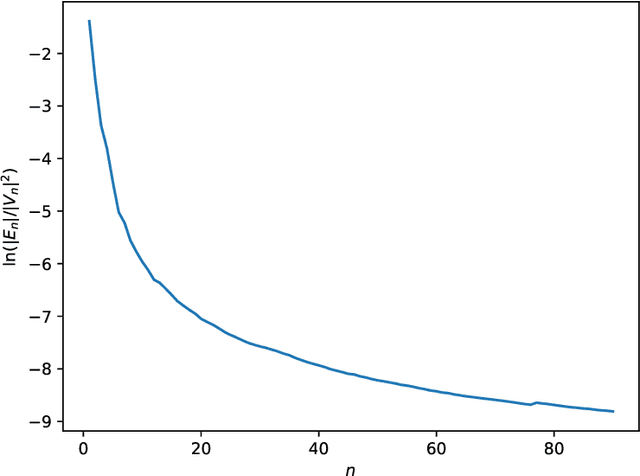
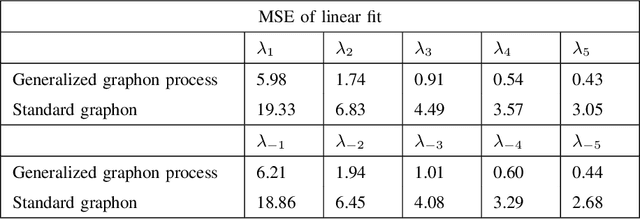
Graphons have traditionally served as limit objects for dense graph sequences, with the cut distance serving as the metric for convergence. However, sparse graph sequences converge to the trivial graphon under the conventional definition of cut distance, which make this framework inadequate for many practical applications. In this paper, we utilize the concepts of generalized graphons and stretched cut distance to describe the convergence of sparse graph sequences. Specifically, we consider a random graph process generated from a generalized graphon. This random graph process converges to the generalized graphon in stretched cut distance. We use this random graph process to model the growing sparse graph, and prove the convergence of the adjacency matrices' eigenvalues. We supplement our findings with experimental validation. Our results indicate the possibility of transfer learning between sparse graphs.
Distribution shift mitigation at test time with performance guarantees
Aug 18, 2023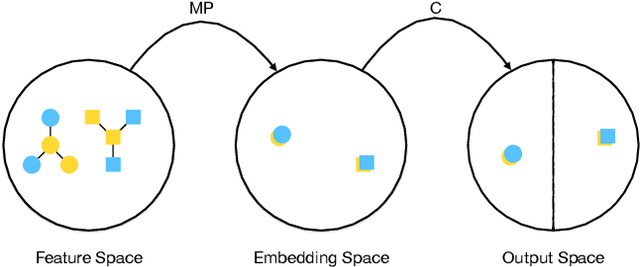
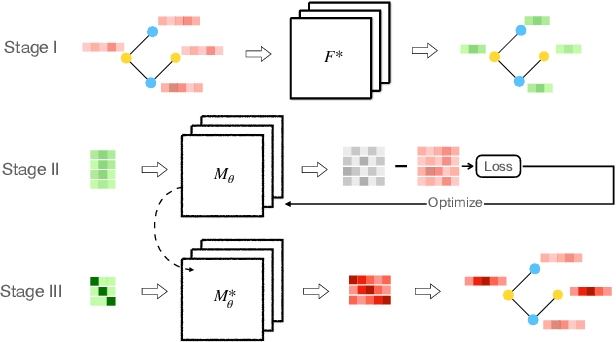

Due to inappropriate sample selection and limited training data, a distribution shift often exists between the training and test sets. This shift can adversely affect the test performance of Graph Neural Networks (GNNs). Existing approaches mitigate this issue by either enhancing the robustness of GNNs to distribution shift or reducing the shift itself. However, both approaches necessitate retraining the model, which becomes unfeasible when the model structure and parameters are inaccessible. To address this challenge, we propose FR-GNN, a general framework for GNNs to conduct feature reconstruction. FRGNN constructs a mapping relationship between the output and input of a well-trained GNN to obtain class representative embeddings and then uses these embeddings to reconstruct the features of labeled nodes. These reconstructed features are then incorporated into the message passing mechanism of GNNs to influence the predictions of unlabeled nodes at test time. Notably, the reconstructed node features can be directly utilized for testing the well-trained model, effectively reducing the distribution shift and leading to improved test performance. This remarkable achievement is attained without any modifications to the model structure or parameters. We provide theoretical guarantees for the effectiveness of our framework. Furthermore, we conduct comprehensive experiments on various public datasets. The experimental results demonstrate the superior performance of FRGNN in comparison to mainstream methods.
The faces of Convolution: from the Fourier theory to algebraic signal processing
Jul 16, 2023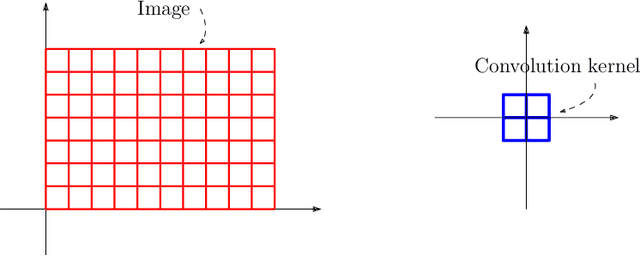
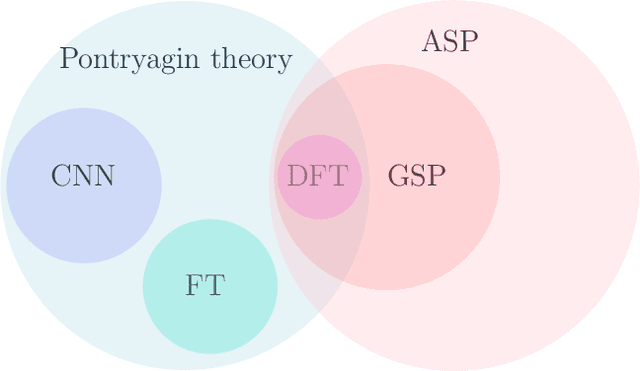
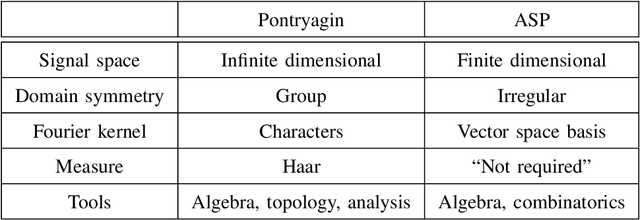
In this expository article, we provide a self-contained overview of the notion of convolution embedded in different theories: from the classical Fourier theory to the theory of algebraic signal processing. We discuss their relations and differences. Toward the end, we provide an opinion on whether there is a consistent approach to convolution that unifies seemingly different approaches by different theories.
AMTSS: An Adaptive Multi-Teacher Single-Student Knowledge Distillation Framework For Multilingual Language Inference
May 13, 2023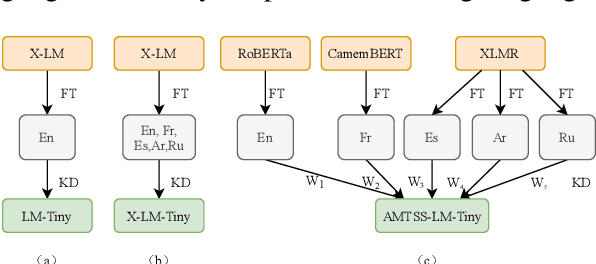


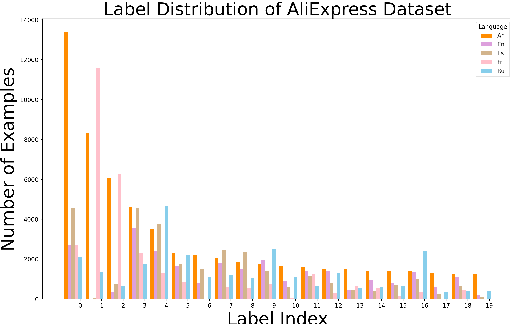
Knowledge distillation is of key importance to launching multilingual pre-trained language models for real applications. To support cost-effective language inference in multilingual settings, we propose AMTSS, an adaptive multi-teacher single-student distillation framework, which allows distilling knowledge from multiple teachers to a single student. We first introduce an adaptive learning strategy and teacher importance weight, which enables a student to effectively learn from max-margin teachers and easily adapt to new languages. Moreover, we present a shared student encoder with different projection layers in support of multiple languages, which contributes to largely reducing development and machine cost. Experimental results show that AMTSS gains competitive results on the public XNLI dataset and the realistic industrial dataset AliExpress (AE) in the E-commerce scenario.