 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFengbo Lan
DexCatch: Learning to Catch Arbitrary Objects with Dexterous Hands
Oct 13, 2023
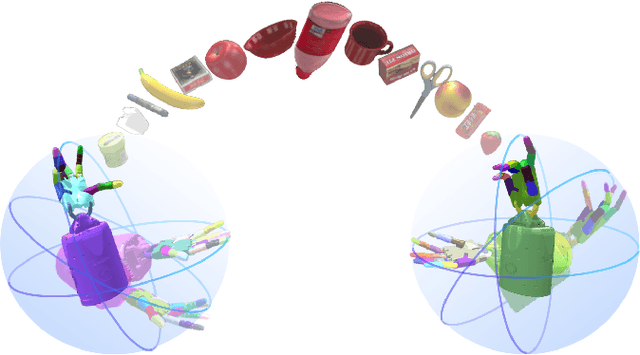
Achieving human-like dexterous manipulation remains a crucial area of research in robotics. Current research focuses on improving the success rate of pick-and-place tasks. Compared with pick-and-place, throw-catching behavior has the potential to increase picking speed without transporting objects to their destination. However, dynamic dexterous manipulation poses a major challenge for stable control due to a large number of dynamic contacts. In this paper, we propose a Stability-Constrained Reinforcement Learning (SCRL) algorithm to learn to catch diverse objects with dexterous hands. The SCRL algorithm outperforms baselines by a large margin, and the learned policies show strong zero-shot transfer performance on unseen objects. Remarkably, even though the object in a hand facing sideward is extremely unstable due to the lack of support from the palm, our method can still achieve a high level of success in the most challenging task. Video demonstrations of learned behaviors and the code can be found on the supplementary website.
Mixed Graph Signal Analysis of Joint Image Denoising / Interpolation
Sep 18, 2023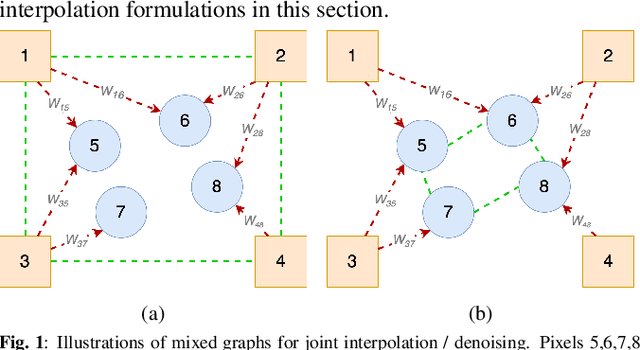
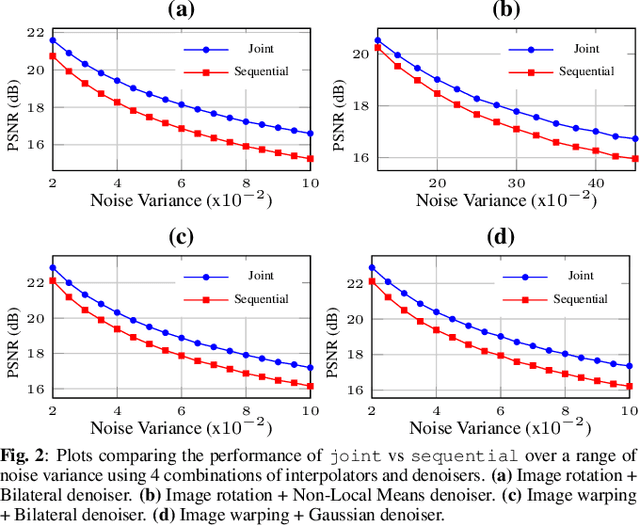
A noise-corrupted image often requires interpolation. Given a linear denoiser and a linear interpolator, when should the operations be independently executed in separate steps, and when should they be combined and jointly optimized? We study joint denoising / interpolation of images from a mixed graph filtering perspective: we model denoising using an undirected graph, and interpolation using a directed graph. We first prove that, under mild conditions, a linear denoiser is a solution graph filter to a maximum a posteriori (MAP) problem regularized using an undirected graph smoothness prior, while a linear interpolator is a solution to a MAP problem regularized using a directed graph smoothness prior. Next, we study two variants of the joint interpolation / denoising problem: a graph-based denoiser followed by an interpolator has an optimal separable solution, while an interpolator followed by a denoiser has an optimal non-separable solution. Experiments show that our joint denoising / interpolation method outperformed separate approaches noticeably.
Tackling Scattering and Reflective Flare in Mobile Camera Systems: A Raw Image Dataset for Enhanced Flare Removal
Jul 26, 2023



The increasing prevalence of mobile devices has led to significant advancements in mobile camera systems and improved image quality. Nonetheless, mobile photography still grapples with challenging issues such as scattering and reflective flare. The absence of a comprehensive real image dataset tailored for mobile phones hinders the development of effective flare mitigation techniques. To address this issue, we present a novel raw image dataset specifically designed for mobile camera systems, focusing on flare removal. Capitalizing on the distinct properties of raw images, this dataset serves as a solid foundation for developing advanced flare removal algorithms. It encompasses a wide variety of real-world scenarios captured with diverse mobile devices and camera settings. The dataset comprises over 2,000 high-quality full-resolution raw image pairs for scattering flare and 1,100 for reflective flare, which can be further segmented into up to 30,000 and 2,200 paired patches, respectively, ensuring broad adaptability across various imaging conditions. Experimental results demonstrate that networks trained with synthesized data struggle to cope with complex lighting settings present in this real image dataset. We also show that processing data through a mobile phone's internal ISP compromises image quality while using raw image data presents significant advantages for addressing the flare removal problem. Our dataset is expected to enable an array of new research in flare removal and contribute to substantial improvements in mobile image quality, benefiting mobile photographers and end-users alike.
A RL-based Policy Optimization Method Guided by Adaptive Stability Certification
Jan 02, 2023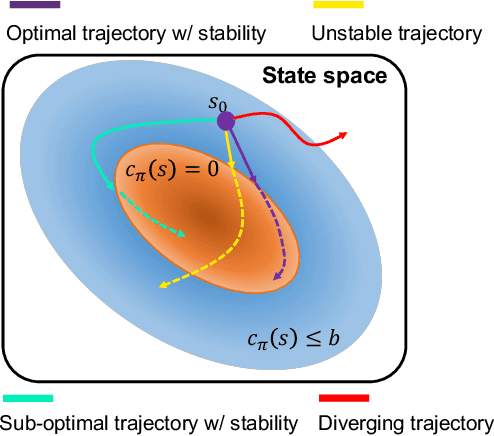
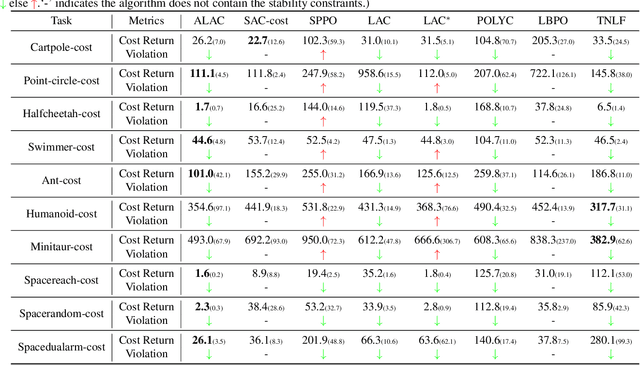

In contrast to the control-theoretic methods, the lack of stability guarantee remains a significant problem for model-free reinforcement learning (RL) methods. Jointly learning a policy and a Lyapunov function has recently become a promising approach to ensuring the whole system with a stability guarantee. However, the classical Lyapunov constraints researchers introduced cannot stabilize the system during the sampling-based optimization. Therefore, we propose the Adaptive Stability Certification (ASC), making the system reach sampling-based stability. Because the ASC condition can search for the optimal policy heuristically, we design the Adaptive Lyapunov-based Actor-Critic (ALAC) algorithm based on the ASC condition. Meanwhile, our algorithm avoids the optimization problem that a variety of constraints are coupled into the objective in current approaches. When evaluated on ten robotic tasks, our method achieves lower accumulated cost and fewer stability constraint violations than previous studies.