 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFengyuan Yu
Rethinking the Representation in Federated Unsupervised Learning with Non-IID Data
Mar 25, 2024
Federated learning achieves effective performance in modeling decentralized data. In practice, client data are not well-labeled, which makes it potential for federated unsupervised learning (FUSL) with non-IID data. However, the performance of existing FUSL methods suffers from insufficient representations, i.e., (1) representation collapse entanglement among local and global models, and (2) inconsistent representation spaces among local models. The former indicates that representation collapse in local model will subsequently impact the global model and other local models. The latter means that clients model data representation with inconsistent parameters due to the deficiency of supervision signals. In this work, we propose FedU2 which enhances generating uniform and unified representation in FUSL with non-IID data. Specifically, FedU2 consists of flexible uniform regularizer (FUR) and efficient unified aggregator (EUA). FUR in each client avoids representation collapse via dispersing samples uniformly, and EUA in server promotes unified representation by constraining consistent client model updating. To extensively validate the performance of FedU2, we conduct both cross-device and cross-silo evaluation experiments on two benchmark datasets, i.e., CIFAR10 and CIFAR100.
DRAM Failure Prediction in AIOps: Empirical Evaluation, Challenges and Opportunities
May 04, 2021
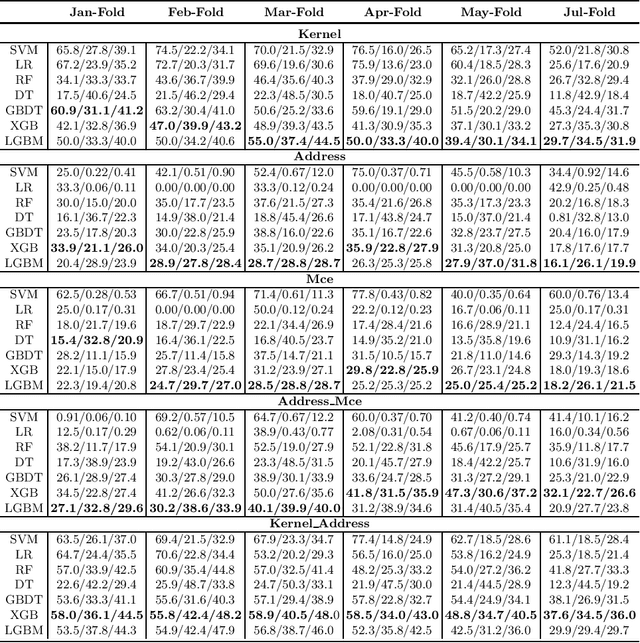
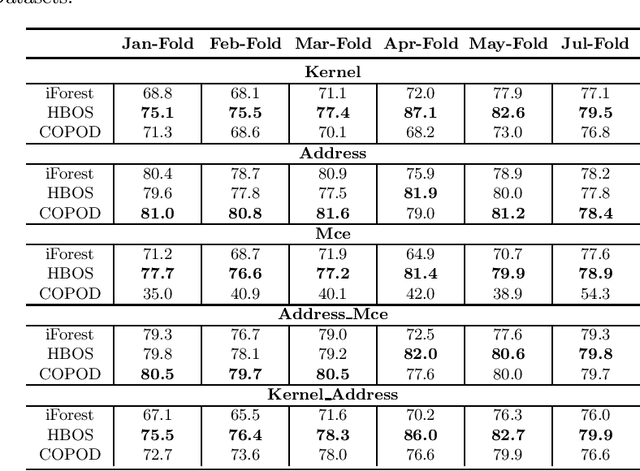
DRAM failure prediction is a vital task in AIOps, which is crucial to maintain the reliability and sustainable service of large-scale data centers. However, limited work has been done on DRAM failure prediction mainly due to the lack of public available datasets. This paper presents a comprehensive empirical evaluation of diverse machine learning techniques for DRAM failure prediction using a large-scale multi-source dataset, including more than three millions of records of kernel, address, and mcelog data, provided by Alibaba Cloud through PAKDD 2021 competition. Particularly, we first formulate the problem as a multi-class classification task and exhaustively evaluate seven popular/state-of-the-art classifiers on both the individual and multiple data sources. We then formulate the problem as an unsupervised anomaly detection task and evaluate three state-of-the-art anomaly detectors. Further, based on the empirical results and our experience of attending this competition, we discuss major challenges and present future research opportunities in this task.