 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlavian Vasile
Exploring 3D-aware Latent Spaces for Efficiently Learning Numerous Scenes
Mar 18, 2024
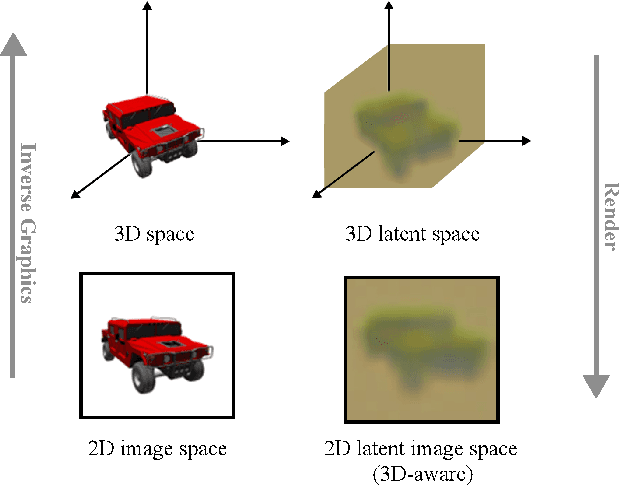
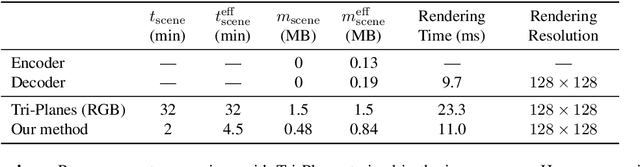
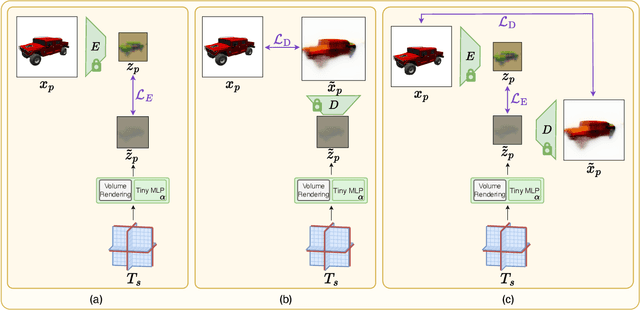

We present a method enabling the scaling of NeRFs to learn a large number of semantically-similar scenes. We combine two techniques to improve the required training time and memory cost per scene. First, we learn a 3D-aware latent space in which we train Tri-Plane scene representations, hence reducing the resolution at which scenes are learned. Moreover, we present a way to share common information across scenes, hence allowing for a reduction of model complexity to learn a particular scene. Our method reduces effective per-scene memory costs by 44% and per-scene time costs by 86% when training 1000 scenes. Our project page can be found at https://3da-ae.github.io .
3DGEN: A GAN-based approach for generating novel 3D models from image data
Dec 13, 2023The recent advances in text and image synthesis show a great promise for the future of generative models in creative fields. However, a less explored area is the one of 3D model generation, with a lot of potential applications to game design, video production, and physical product design. In our paper, we present 3DGEN, a model that leverages the recent work on both Neural Radiance Fields for object reconstruction and GAN-based image generation. We show that the proposed architecture can generate plausible meshes for objects of the same category as the training images and compare the resulting meshes with the state-of-the-art baselines, leading to visible uplifts in generation quality.
AdBooster: Personalized Ad Creative Generation using Stable Diffusion Outpainting
Sep 08, 2023

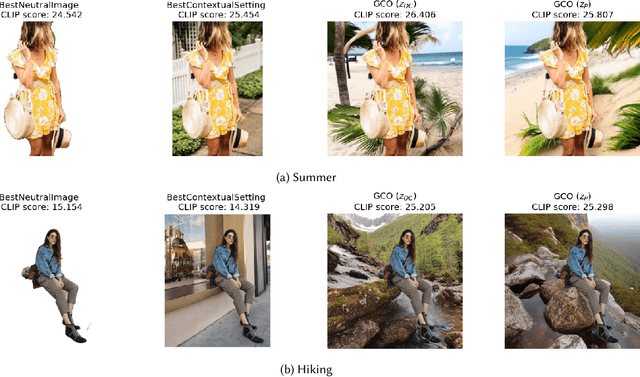
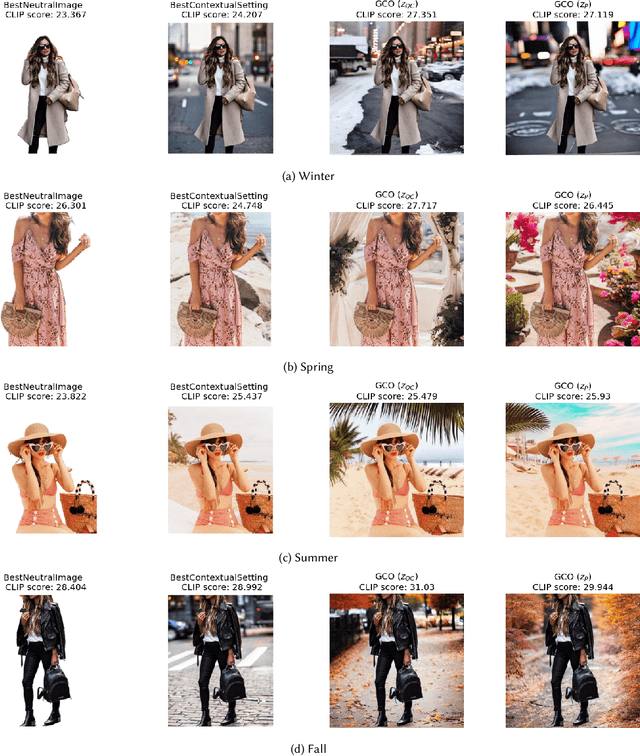
In digital advertising, the selection of the optimal item (recommendation) and its best creative presentation (creative optimization) have traditionally been considered separate disciplines. However, both contribute significantly to user satisfaction, underpinning our assumption that it relies on both an item's relevance and its presentation, particularly in the case of visual creatives. In response, we introduce the task of {\itshape Generative Creative Optimization (GCO)}, which proposes the use of generative models for creative generation that incorporate user interests, and {\itshape AdBooster}, a model for personalized ad creatives based on the Stable Diffusion outpainting architecture. This model uniquely incorporates user interests both during fine-tuning and at generation time. To further improve AdBooster's performance, we also introduce an automated data augmentation pipeline. Through our experiments on simulated data, we validate AdBooster's effectiveness in generating more relevant creatives than default product images, showing its potential of enhancing user engagement.
Offline Evaluation of Reward-Optimizing Recommender Systems: The Case of Simulation
Sep 18, 2022Both in academic and industry-based research, online evaluation methods are seen as the golden standard for interactive applications like recommendation systems. Naturally, the reason for this is that we can directly measure utility metrics that rely on interventions, being the recommendations that are being shown to users. Nevertheless, online evaluation methods are costly for a number of reasons, and a clear need remains for reliable offline evaluation procedures. In industry, offline metrics are often used as a first-line evaluation to generate promising candidate models to evaluate online. In academic work, limited access to online systems makes offline metrics the de facto approach to validating novel methods. Two classes of offline metrics exist: proxy-based methods, and counterfactual methods. The first class is often poorly correlated with the online metrics we care about, and the latter class only provides theoretical guarantees under assumptions that cannot be fulfilled in real-world environments. Here, we make the case that simulation-based comparisons provide ways forward beyond offline metrics, and argue that they are a preferable means of evaluation.
A Scalable Probabilistic Model for Reward Optimizing Slate Recommendation
Aug 10, 2022
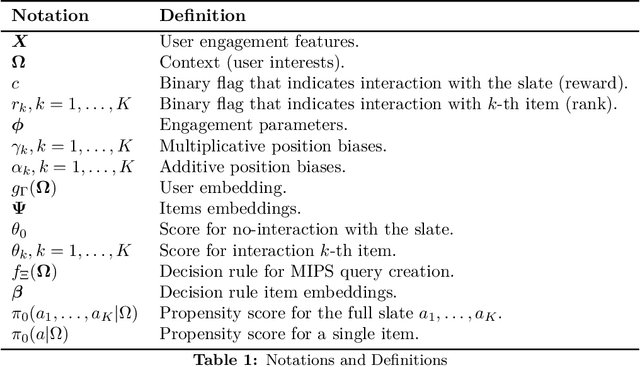
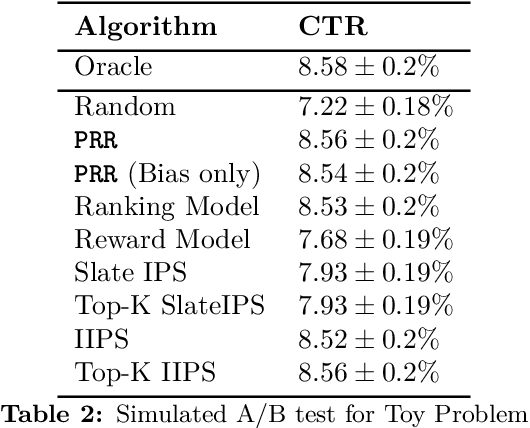
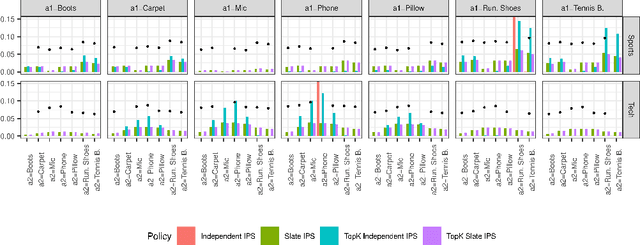
We introduce Probabilistic Rank and Reward model (PRR), a scalable probabilistic model for personalized slate recommendation. Our model allows state-of-the-art estimation of user interests in the following ubiquitous recommender system scenario: A user is shown a slate of K recommendations and the user chooses at most one of these K items. It is the goal of the recommender system to find the K items of most interest to a user in order to maximize the probability that the user interacts with the slate. Our contribution is to show that we can learn more effectively the probability of the recommendations being successful by combining the reward - whether the slate was clicked or not - and the rank - the item on the slate that was selected. Our method learns more efficiently than bandit methods that use only the reward, and user preference methods that use only the rank. It also provides similar or better estimation performance to independent inverse-propensity-score methods and is far more scalable. Our method is state of the art in terms of both speed and accuracy on massive datasets with up to 1 million items. Finally, our method allows fast delivery of recommendations powered by maximum inner product search (MIPS), making it suitable in extremely low latency domains such as computational advertising.
What Users Want? WARHOL: A Generative Model for Recommendation
Sep 02, 2021

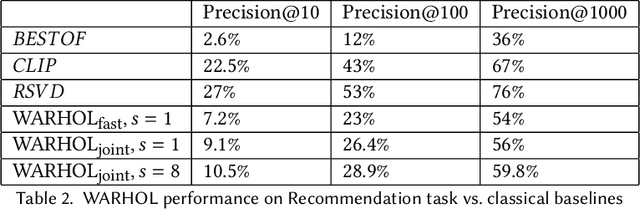
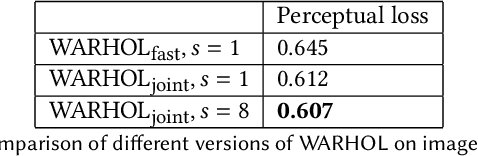
Current recommendation approaches help online merchants predict, for each visiting user, which subset of their existing products is the most relevant. However, besides being interested in matching users with existing products, merchants are also interested in understanding their users' underlying preferences. This could indeed help them produce or acquire better matching products in the future. We argue that existing recommendation models cannot directly be used to predict the optimal combination of features that will make new products serve better the needs of the target audience. To tackle this, we turn to generative models, which allow us to learn explicitly distributions over product feature combinations both in text and visual space. We develop WARHOL, a product generation and recommendation architecture that takes as input past user shopping activity and generates relevant textual and visual descriptions of novel products. We show that WARHOL can approach the performance of state-of-the-art recommendation models, while being able to generate entirely new products that are relevant to the given user profiles.
Combining Reward and Rank Signals for Slate Recommendation
Jul 29, 2021


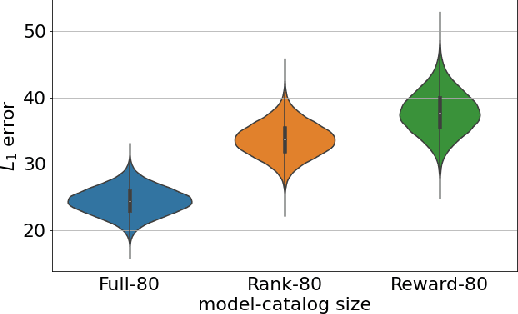
We consider the problem of slate recommendation, where the recommender system presents a user with a collection or slate composed of K recommended items at once. If the user finds the recommended items appealing then the user may click and the recommender system receives some feedback. Two pieces of information are available to the recommender system: was the slate clicked? (the reward), and if the slate was clicked, which item was clicked? (rank). In this paper, we formulate several Bayesian models that incorporate the reward signal (Reward model), the rank signal (Rank model), or both (Full model), for non-personalized slate recommendation. In our experiments, we analyze performance gains of the Full model and show that it achieves significantly lower error as the number of products in the catalog grows or as the slate size increases.
Improving Offline Contextual Bandits with Distributional Robustness
Nov 13, 2020
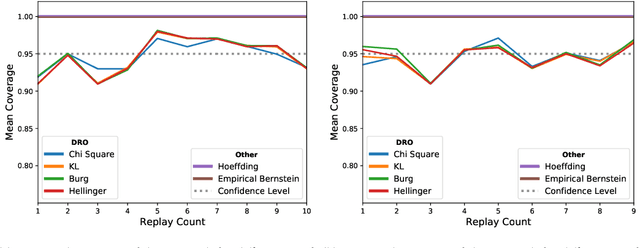
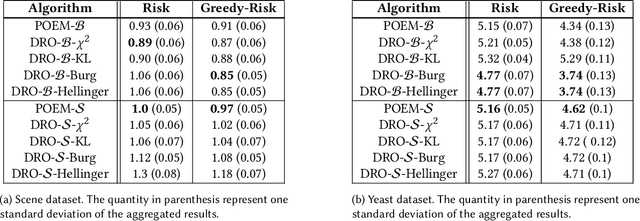
This paper extends the Distributionally Robust Optimization (DRO) approach for offline contextual bandits. Specifically, we leverage this framework to introduce a convex reformulation of the Counterfactual Risk Minimization principle. Besides relying on convex programs, our approach is compatible with stochastic optimization, and can therefore be readily adapted tothe large data regime. Our approach relies on the construction of asymptotic confidence intervals for offline contextual bandits through the DRO framework. By leveraging known asymptotic results of robust estimators, we also show how to automatically calibrate such confidence intervals, which in turn removes the burden of hyper-parameter selection for policy optimization. We present preliminary empirical results supporting the effectiveness of our approach.
From Clicks to Conversions: Recommendation for long-term reward
Sep 01, 2020Recommender systems are often optimised for short-term reward: a recommendation is considered successful if a reward (e.g. a click) can be observed immediately after the recommendation. The advantage of this framework is that with some reasonable (although questionable) assumptions, it allows familiar supervised learning tools to be used for the recommendation task. However, it means that long-term business metrics, e.g. sales or retention are ignored. In this paper we introduce a framework for modeling long-term rewards in the RecoGym simulation environment. We use this newly introduced functionality to showcase problems introduced by the last-click attribution scheme in the case of conversion-optimized recommendations and propose a simple extension that leads to state-of-the-art results.
BLOB : A Probabilistic Model for Recommendation that Combines Organic and Bandit Signals
Aug 28, 2020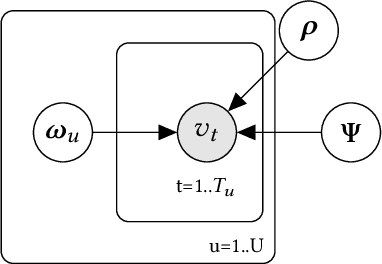
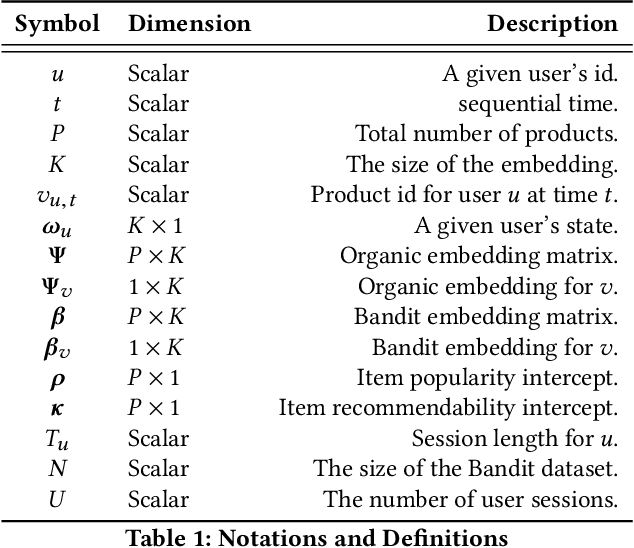
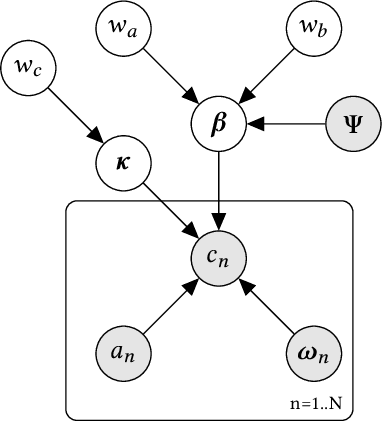
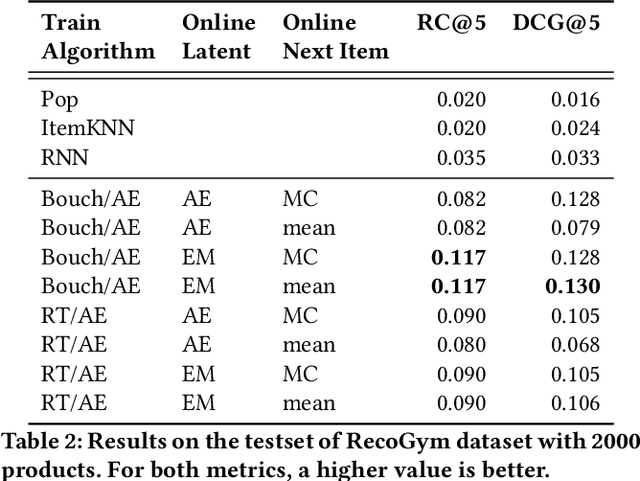
A common task for recommender systems is to build a pro le of the interests of a user from items in their browsing history and later to recommend items to the user from the same catalog. The users' behavior consists of two parts: the sequence of items that they viewed without intervention (the organic part) and the sequences of items recommended to them and their outcome (the bandit part). In this paper, we propose Bayesian Latent Organic Bandit model (BLOB), a probabilistic approach to combine the 'or-ganic' and 'bandit' signals in order to improve the estimation of recommendation quality. The bandit signal is valuable as it gives direct feedback of recommendation performance, but the signal quality is very uneven, as it is highly concentrated on the recommendations deemed optimal by the past version of the recom-mender system. In contrast, the organic signal is typically strong and covers most items, but is not always relevant to the recommendation task. In order to leverage the organic signal to e ciently learn the bandit signal in a Bayesian model we identify three fundamental types of distances, namely action-history, action-action and history-history distances. We implement a scalable approximation of the full model using variational auto-encoders and the local re-paramerization trick. We show using extensive simulation studies that our method out-performs or matches the value of both state-of-the-art organic-based recommendation algorithms, and of bandit-based methods (both value and policy-based) both in organic and bandit-rich environments.