 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrédéric Precioso
Kernel KMeans clustering splits for end-to-end unsupervised decision trees
Feb 19, 2024
Trees are convenient models for obtaining explainable predictions on relatively small datasets. Although there are many proposals for the end-to-end construction of such trees in supervised learning, learning a tree end-to-end for clustering without labels remains an open challenge. As most works focus on interpreting with trees the result of another clustering algorithm, we present here a novel end-to-end trained unsupervised binary tree for clustering: Kauri. This method performs a greedy maximisation of the kernel KMeans objective without requiring the definition of centroids. We compare this model on multiple datasets with recent unsupervised trees and show that Kauri performs identically when using a linear kernel. For other kernels, Kauri often outperforms the concatenation of kernel KMeans and a CART decision tree.
Mind the map! Accounting for existing map information when estimating online HDMaps from sensor data
Nov 17, 2023
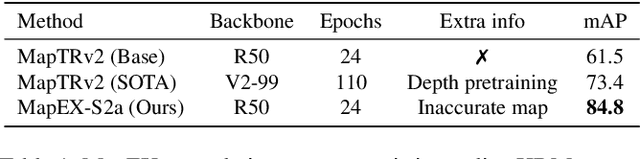
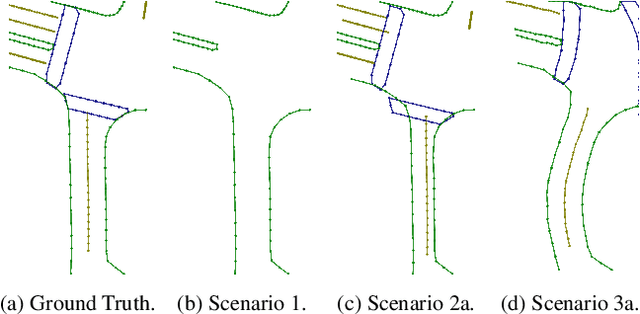
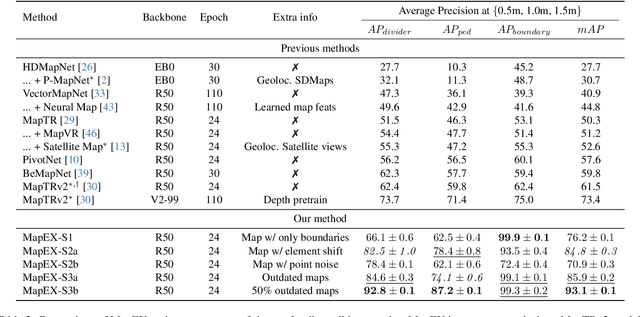
Online High Definition Map (HDMap) estimation from sensors offers a low-cost alternative to manually acquired HDMaps. As such, it promises to lighten costs for already HDMap-reliant Autonomous Driving systems, and potentially even spread their use to new systems. In this paper, we propose to improve online HDMap estimation by accounting for already existing maps. We identify 3 reasonable types of useful existing maps (minimalist, noisy, and outdated). We also introduce MapEX, a novel online HDMap estimation framework that accounts for existing maps. MapEX achieves this by encoding map elements into query tokens and by refining the matching algorithm used to train classic query based map estimation models. We demonstrate that MapEX brings significant improvements on the nuScenes dataset. For instance, MapEX - given noisy maps - improves by 38% over the MapTRv2 detector it is based on and by 16% over the current SOTA.
Generalised Mutual Information: a Framework for Discriminative Clustering
Sep 06, 2023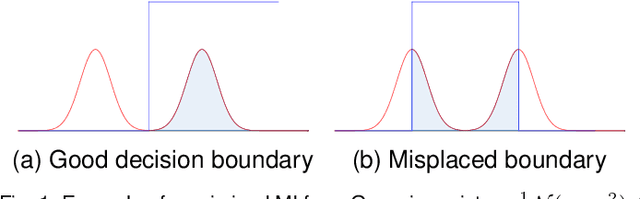

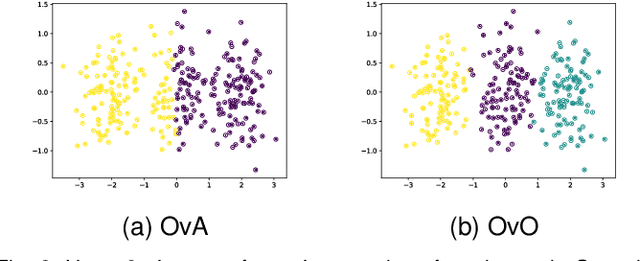
In the last decade, recent successes in deep clustering majorly involved the Mutual Information (MI) as an unsupervised objective for training neural networks with increasing regularisations. While the quality of the regularisations have been largely discussed for improvements, little attention has been dedicated to the relevance of MI as a clustering objective. In this paper, we first highlight how the maximisation of MI does not lead to satisfying clusters. We identified the Kullback-Leibler divergence as the main reason of this behaviour. Hence, we generalise the mutual information by changing its core distance, introducing the Generalised Mutual Information (GEMINI): a set of metrics for unsupervised neural network training. Unlike MI, some GEMINIs do not require regularisations when training as they are geometry-aware thanks to distances or kernels in the data space. Finally, we highlight that GEMINIs can automatically select a relevant number of clusters, a property that has been little studied in deep discriminative clustering context where the number of clusters is a priori unknown.
Sparse GEMINI for Joint Discriminative Clustering and Feature Selection
Feb 07, 2023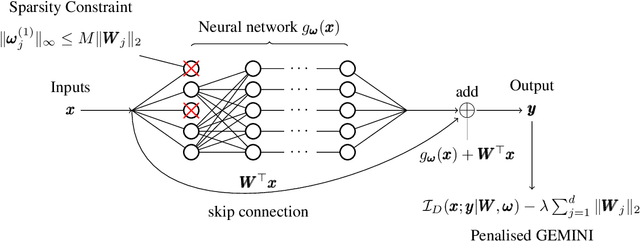
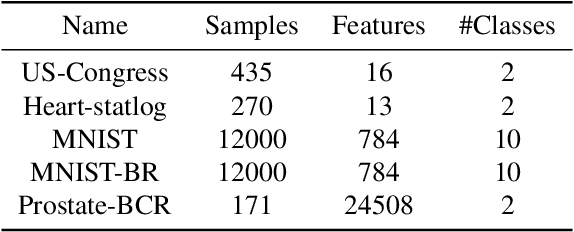
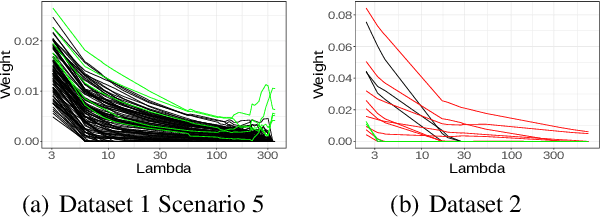
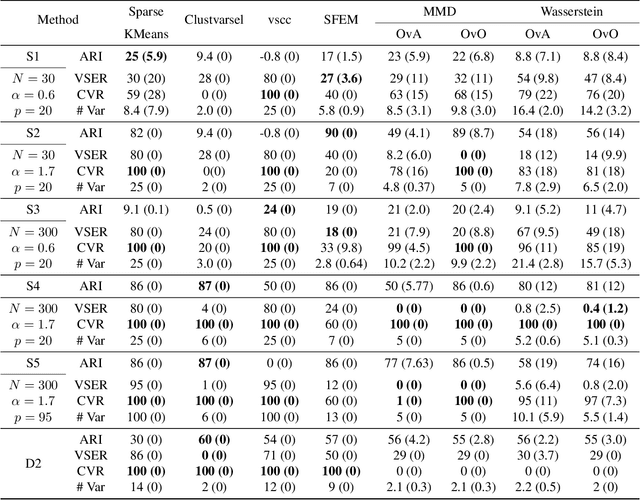
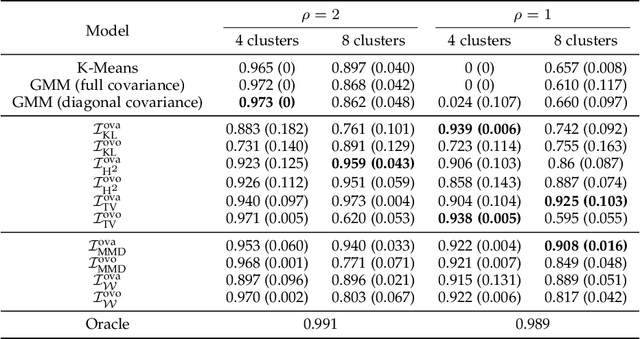
Feature selection in clustering is a hard task which involves simultaneously the discovery of relevant clusters as well as relevant variables with respect to these clusters. While feature selection algorithms are often model-based through optimised model selection or strong assumptions on $p(\pmb{x})$, we introduce a discriminative clustering model trying to maximise a geometry-aware generalisation of the mutual information called GEMINI with a simple $\ell_1$ penalty: the Sparse GEMINI. This algorithm avoids the burden of combinatorial feature subset exploration and is easily scalable to high-dimensional data and large amounts of samples while only designing a clustering model $p_\theta(y|\pmb{x})$. We demonstrate the performances of Sparse GEMINI on synthetic datasets as well as large-scale datasets. Our results show that Sparse GEMINI is a competitive algorithm and has the ability to select relevant subsets of variables with respect to the clustering without using relevance criteria or prior hypotheses.
A Multi-stage deep architecture for summary generation of soccer videos
May 02, 2022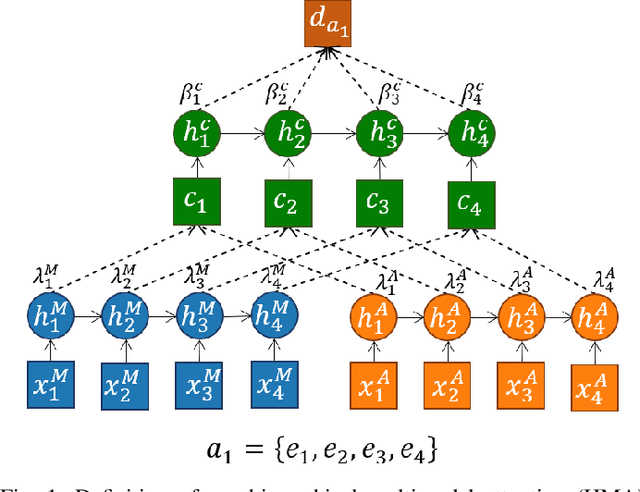
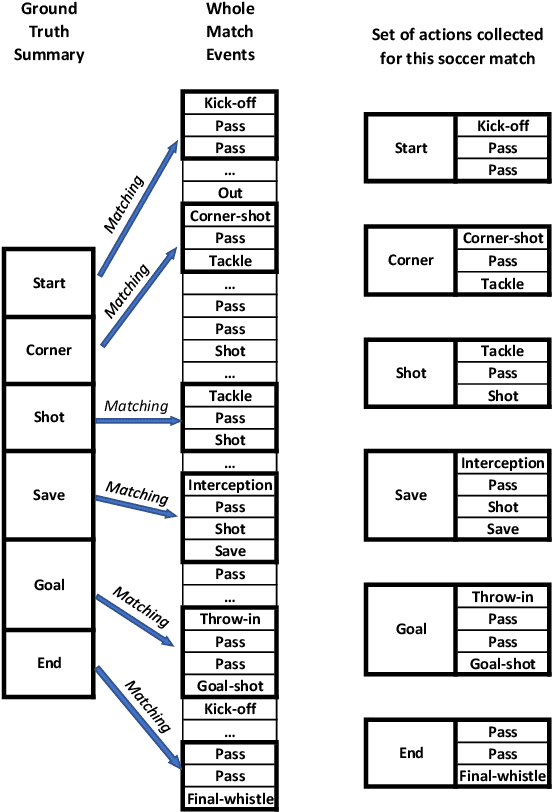
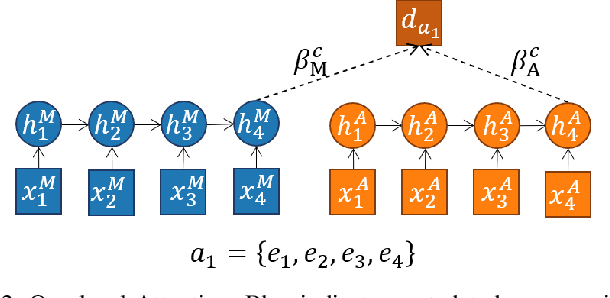
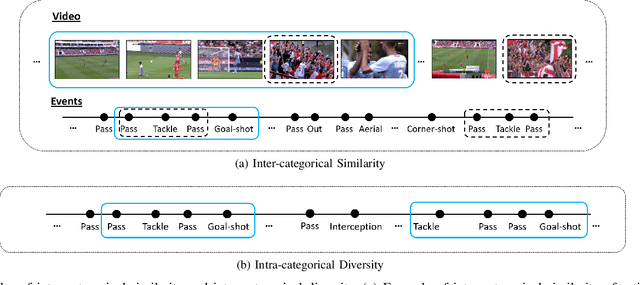
Video content is present in an ever-increasing number of fields, both scientific and commercial. Sports, particularly soccer, is one of the industries that has invested the most in the field of video analytics, due to the massive popularity of the game and the emergence of new markets. Previous state-of-the-art methods on soccer matches video summarization rely on handcrafted heuristics to generate summaries which are poorly generalizable, but these works have yet proven that multiple modalities help detect the best actions of the game. On the other hand, machine learning models with higher generalization potential have entered the field of summarization of general-purpose videos, offering several deep learning approaches. However, most of them exploit content specificities that are not appropriate for sport whole-match videos. Although video content has been for many years the main source for automatizing knowledge extraction in soccer, the data that records all the events happening on the field has become lately very important in sports analytics, since this event data provides richer context information and requires less processing. We propose a method to generate the summary of a soccer match exploiting both the audio and the event metadata. The results show that our method can detect the actions of the match, identify which of these actions should belong to the summary and then propose multiple candidate summaries which are similar enough but with relevant variability to provide different options to the final editor. Furthermore, we show the generalization capability of our work since it can transfer knowledge between datasets from different broadcasting companies, different competitions, acquired in different conditions, and corresponding to summaries of different lengths
From text saliency to linguistic objects: learning linguistic interpretable markers with a multi-channels convolutional architecture
Apr 07, 2020



A lot of effort is currently made to provide methods to analyze and understand deep neural network impressive performances for tasks such as image or text classification. These methods are mainly based on visualizing the important input features taken into account by the network to build a decision. However these techniques, let us cite LIME, SHAP, Grad-CAM, or TDS, require extra effort to interpret the visualization with respect to expert knowledge. In this paper, we propose a novel approach to inspect the hidden layers of a fitted CNN in order to extract interpretable linguistic objects from texts exploiting classification process. In particular, we detail a weighted extension of the Text Deconvolution Saliency (wTDS) measure which can be used to highlight the relevant features used by the CNN to perform the classification task. We empirically demonstrate the efficiency of our approach on corpora from two different languages: English and French. On all datasets, wTDS automatically encodes complex linguistic objects based on co-occurrences and possibly on grammatical and syntax analysis.