 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGörkay Aydemir
Self-supervised Object-Centric Learning for Videos
Oct 10, 2023
Unsupervised multi-object segmentation has shown impressive results on images by utilizing powerful semantics learned from self-supervised pretraining. An additional modality such as depth or motion is often used to facilitate the segmentation in video sequences. However, the performance improvements observed in synthetic sequences, which rely on the robustness of an additional cue, do not translate to more challenging real-world scenarios. In this paper, we propose the first fully unsupervised method for segmenting multiple objects in real-world sequences. Our object-centric learning framework spatially binds objects to slots on each frame and then relates these slots across frames. From these temporally-aware slots, the training objective is to reconstruct the middle frame in a high-level semantic feature space. We propose a masking strategy by dropping a significant portion of tokens in the feature space for efficiency and regularization. Additionally, we address over-clustering by merging slots based on similarity. Our method can successfully segment multiple instances of complex and high-variety classes in YouTube videos.
ADAPT: Efficient Multi-Agent Trajectory Prediction with Adaptation
Jul 26, 2023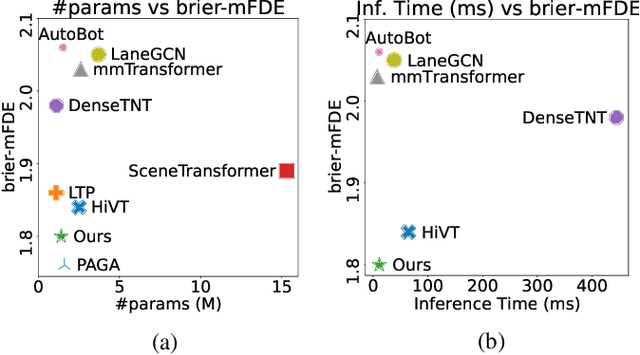
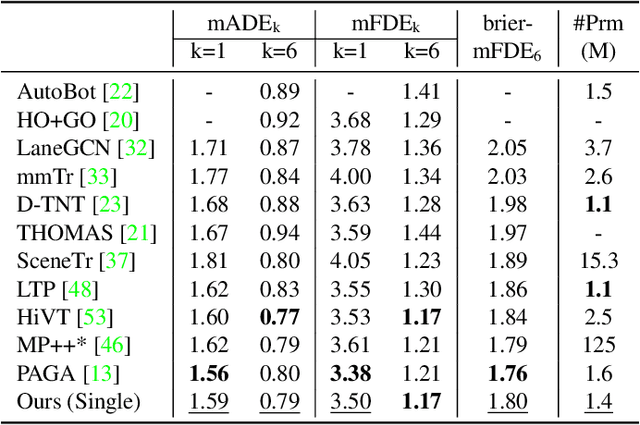

Forecasting future trajectories of agents in complex traffic scenes requires reliable and efficient predictions for all agents in the scene. However, existing methods for trajectory prediction are either inefficient or sacrifice accuracy. To address this challenge, we propose ADAPT, a novel approach for jointly predicting the trajectories of all agents in the scene with dynamic weight learning. Our approach outperforms state-of-the-art methods in both single-agent and multi-agent settings on the Argoverse and Interaction datasets, with a fraction of their computational overhead. We attribute the improvement in our performance: first, to the adaptive head augmenting the model capacity without increasing the model size; second, to our design choices in the endpoint-conditioned prediction, reinforced by gradient stopping. Our analyses show that ADAPT can focus on each agent with adaptive prediction, allowing for accurate predictions efficiently. https://KUIS-AI.github.io/adapt
Trajectory Forecasting on Temporal Graphs
Jul 01, 2022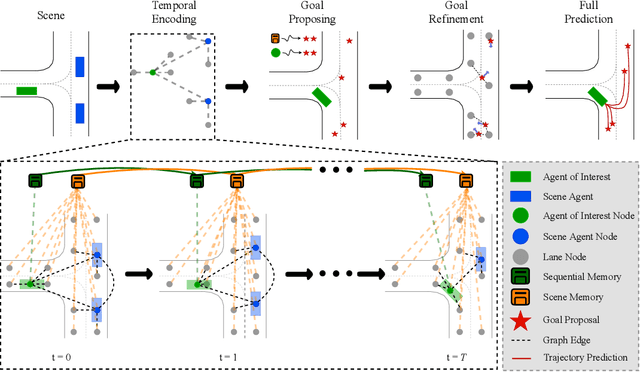
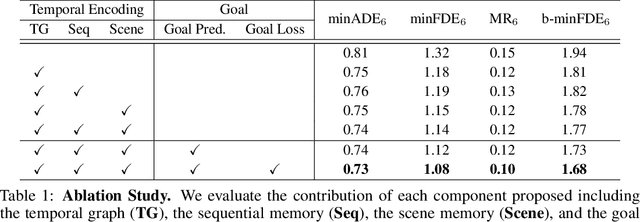
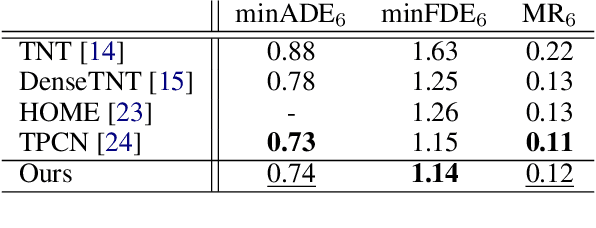
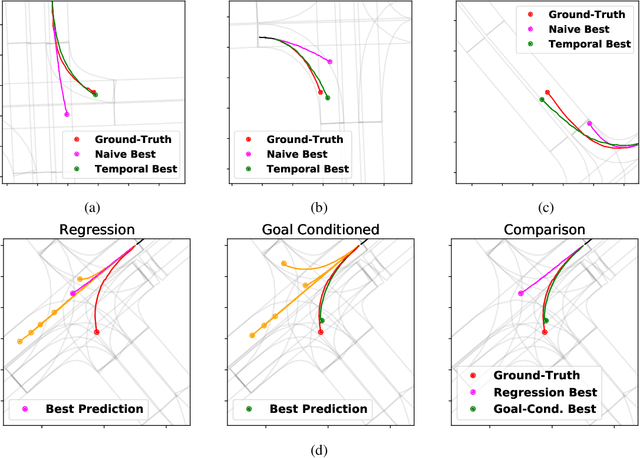
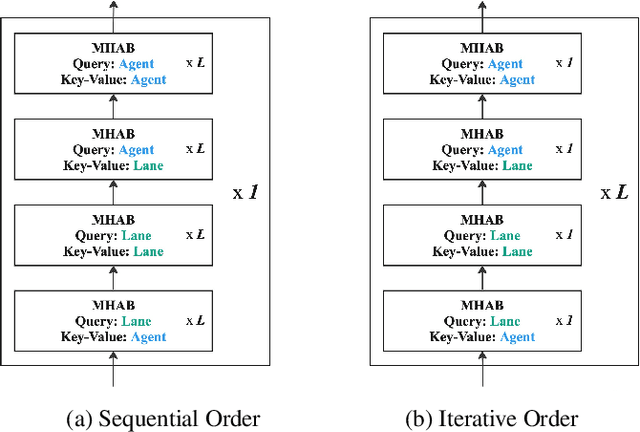
Predicting future locations of agents in the scene is an important problem in self-driving. In recent years, there has been a significant progress in representing the scene and the agents in it. The interactions of agents with the scene and with each other are typically modeled with a Graph Neural Network. However, the graph structure is mostly static and fails to represent the temporal changes in highly dynamic scenes. In this work, we propose a temporal graph representation to better capture the dynamics in traffic scenes. We complement our representation with two types of memory modules; one focusing on the agent of interest and the other on the entire scene. This allows us to learn temporally-aware representations that can achieve good results even with simple regression of multiple futures. When combined with goal-conditioned prediction, we show better results that can reach the state-of-the-art performance on the Argoverse benchmark.