 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGabriele Berton
EarthMatch: Iterative Coregistration for Fine-grained Localization of Astronaut Photography
May 08, 2024
Precise, pixel-wise geolocalization of astronaut photography is critical to unlocking the potential of this unique type of remotely sensed Earth data, particularly for its use in disaster management and climate change research. Recent works have established the Astronaut Photography Localization task, but have either proved too costly for mass deployment or generated too coarse a localization. Thus, we present EarthMatch, an iterative homography estimation method that produces fine-grained localization of astronaut photographs while maintaining an emphasis on speed. We refocus the astronaut photography benchmark, AIMS, on the geolocalization task itself, and prove our method's efficacy on this dataset. In addition, we offer a new, fair method for image matcher comparison, and an extensive evaluation of different matching models within our localization pipeline. Our method will enable fast and accurate localization of the 4.5 million and growing collection of astronaut photography of Earth. Webpage with code and data at https://earthloc-and-earthmatch.github.io
JIST: Joint Image and Sequence Training for Sequential Visual Place Recognition
Mar 28, 2024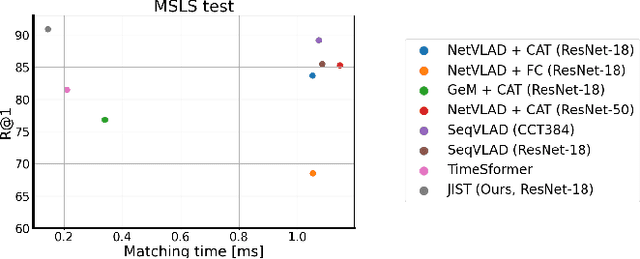
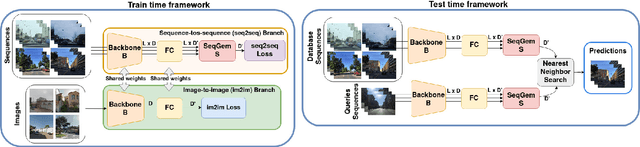
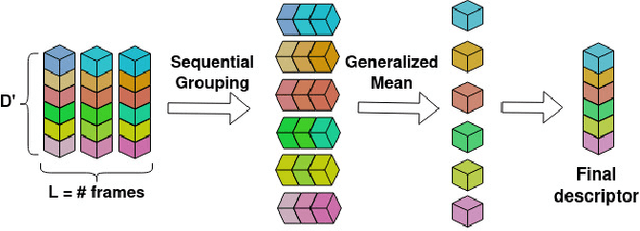
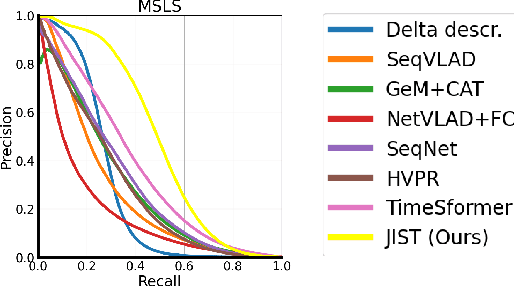
Visual Place Recognition aims at recognizing previously visited places by relying on visual clues, and it is used in robotics applications for SLAM and localization. Since typically a mobile robot has access to a continuous stream of frames, this task is naturally cast as a sequence-to-sequence localization problem. Nevertheless, obtaining sequences of labelled data is much more expensive than collecting isolated images, which can be done in an automated way with little supervision. As a mitigation to this problem, we propose a novel Joint Image and Sequence Training protocol (JIST) that leverages large uncurated sets of images through a multi-task learning framework. With JIST we also introduce SeqGeM, an aggregation layer that revisits the popular GeM pooling to produce a single robust and compact embedding from a sequence of single-frame embeddings. We show that our model is able to outperform previous state of the art while being faster, using 8 times smaller descriptors, having a lighter architecture and allowing to process sequences of various lengths. Code is available at https://github.com/ga1i13o/JIST
EarthLoc: Astronaut Photography Localization by Indexing Earth from Space
Mar 11, 2024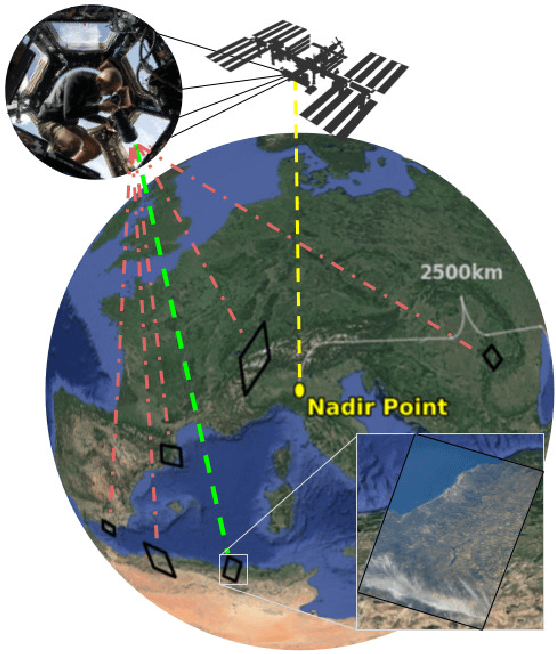
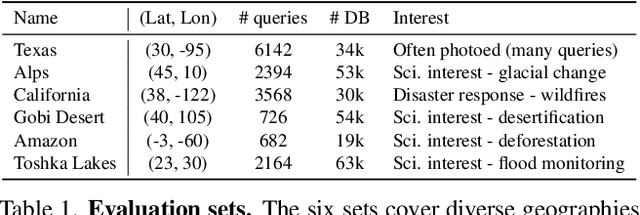

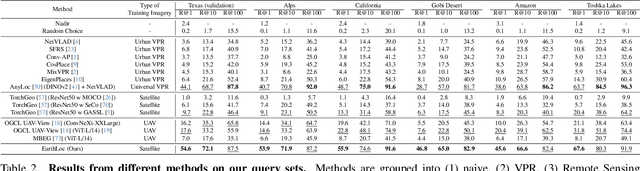
Astronaut photography, spanning six decades of human spaceflight, presents a unique Earth observations dataset with immense value for both scientific research and disaster response. Despite its significance, accurately localizing the geographical extent of these images, crucial for effective utilization, poses substantial challenges. Current manual localization efforts are time-consuming, motivating the need for automated solutions. We propose a novel approach - leveraging image retrieval - to address this challenge efficiently. We introduce innovative training techniques, including Year-Wise Data Augmentation and a Neutral-Aware Multi-Similarity Loss, which contribute to the development of a high-performance model, EarthLoc. We develop six evaluation datasets and perform a comprehensive benchmark comparing EarthLoc to existing methods, showcasing its superior efficiency and accuracy. Our approach marks a significant advancement in automating the localization of astronaut photography, which will help bridge a critical gap in Earth observations data. Code and datasets are available at https://github.com/gmberton/EarthLoc
EigenPlaces: Training Viewpoint Robust Models for Visual Place Recognition
Aug 21, 2023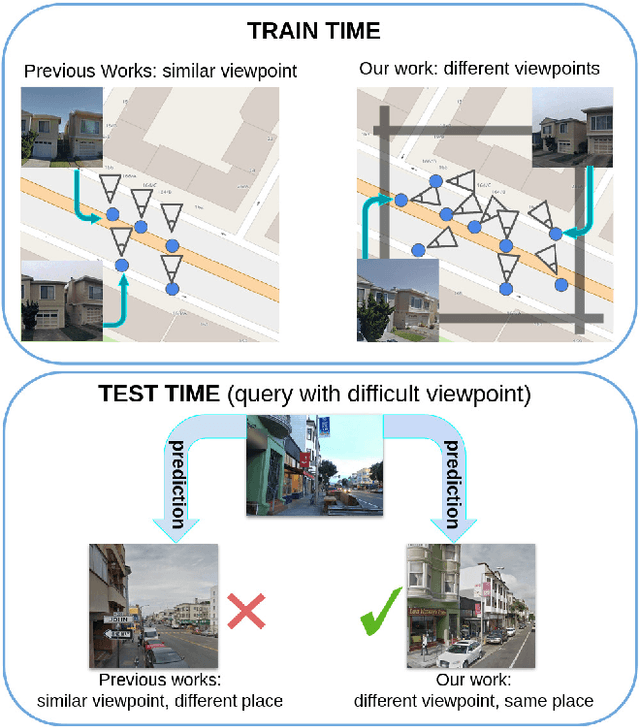



Visual Place Recognition is a task that aims to predict the place of an image (called query) based solely on its visual features. This is typically done through image retrieval, where the query is matched to the most similar images from a large database of geotagged photos, using learned global descriptors. A major challenge in this task is recognizing places seen from different viewpoints. To overcome this limitation, we propose a new method, called EigenPlaces, to train our neural network on images from different point of views, which embeds viewpoint robustness into the learned global descriptors. The underlying idea is to cluster the training data so as to explicitly present the model with different views of the same points of interest. The selection of this points of interest is done without the need for extra supervision. We then present experiments on the most comprehensive set of datasets in literature, finding that EigenPlaces is able to outperform previous state of the art on the majority of datasets, while requiring 60\% less GPU memory for training and using 50\% smaller descriptors. The code and trained models for EigenPlaces are available at {\small{\url{https://github.com/gmberton/EigenPlaces}}}, while results with any other baseline can be computed with the codebase at {\small{\url{https://github.com/gmberton/auto_VPR}}}.
Divide&Classify: Fine-Grained Classification for City-Wide Visual Place Recognition
Jul 17, 2023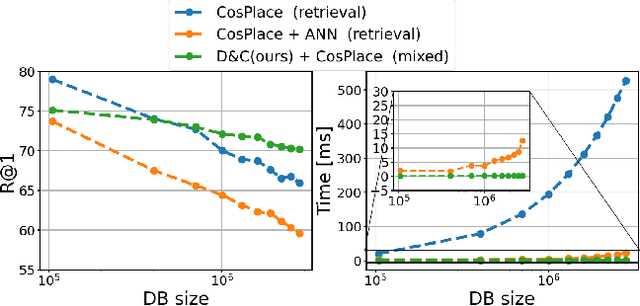
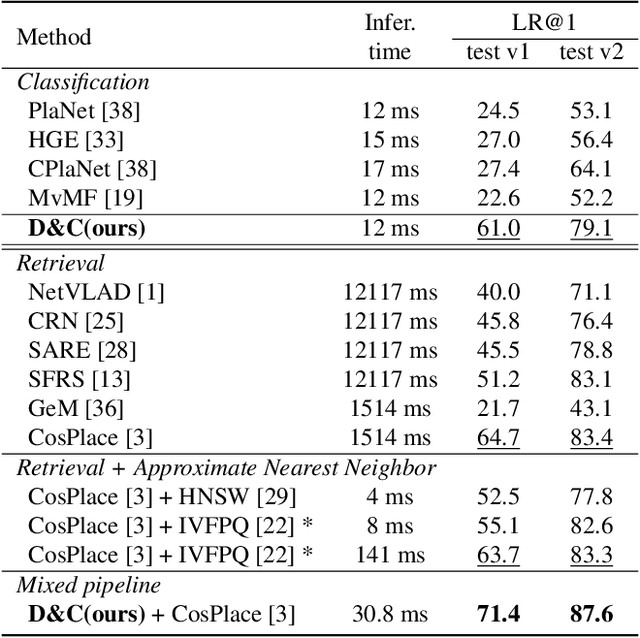
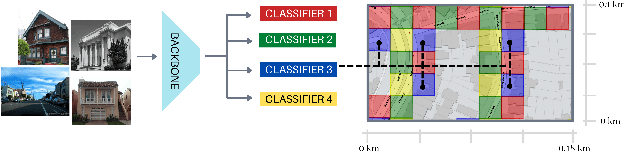
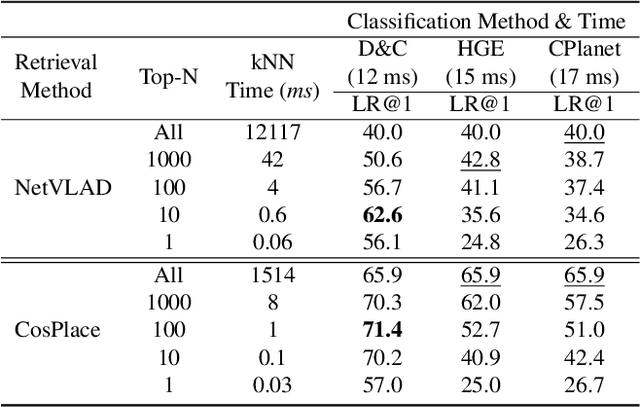
Visual Place recognition is commonly addressed as an image retrieval problem. However, retrieval methods are impractical to scale to large datasets, densely sampled from city-wide maps, since their dimension impact negatively on the inference time. Using approximate nearest neighbour search for retrieval helps to mitigate this issue, at the cost of a performance drop. In this paper we investigate whether we can effectively approach this task as a classification problem, thus bypassing the need for a similarity search. We find that existing classification methods for coarse, planet-wide localization are not suitable for the fine-grained and city-wide setting. This is largely due to how the dataset is split into classes, because these methods are designed to handle a sparse distribution of photos and as such do not consider the visual aliasing problem across neighbouring classes that naturally arises in dense scenarios. Thus, we propose a partitioning scheme that enables a fast and accurate inference, preserving a simple learning procedure, and a novel inference pipeline based on an ensemble of novel classifiers that uses the prototypes learned via an angular margin loss. Our method, Divide&Classify (D&C), enjoys the fast inference of classification solutions and an accuracy competitive with retrieval methods on the fine-grained, city-wide setting. Moreover, we show that D&C can be paired with existing retrieval pipelines to speed up computations by over 20 times while increasing their recall, leading to new state-of-the-art results.
Are Local Features All You Need for Cross-Domain Visual Place Recognition?
Apr 12, 2023



Visual Place Recognition is a task that aims to predict the coordinates of an image (called query) based solely on visual clues. Most commonly, a retrieval approach is adopted, where the query is matched to the most similar images from a large database of geotagged photos, using learned global descriptors. Despite recent advances, recognizing the same place when the query comes from a significantly different distribution is still a major hurdle for state of the art retrieval methods. Examples are heavy illumination changes (e.g. night-time images) or substantial occlusions (e.g. transient objects). In this work we explore whether re-ranking methods based on spatial verification can tackle these challenges, following the intuition that local descriptors are inherently more robust than global features to domain shifts. To this end, we provide a new, comprehensive benchmark on current state of the art models. We also introduce two new demanding datasets with night and occluded queries, to be matched against a city-wide database. Code and datasets are available at https://github.com/gbarbarani/re-ranking-for-VPR.
Learning Sequential Descriptors for Sequence-based Visual Place Recognition
Jul 08, 2022



In robotics, Visual Place Recognition is a continuous process that receives as input a video stream to produce a hypothesis of the robot's current position within a map of known places. This task requires robust, scalable, and efficient techniques for real applications. This work proposes a detailed taxonomy of techniques using sequential descriptors, highlighting different mechanism to fuse the information from the individual images. This categorization is supported by a complete benchmark of experimental results that provides evidence on the strengths and weaknesses of these different architectural choices. In comparison to existing sequential descriptors methods, we further investigate the viability of Transformers instead of CNN backbones, and we propose a new ad-hoc sequence-level aggregator called SeqVLAD, which outperforms prior state of the art on different datasets. The code is available at https://github.com/vandal-vpr/vg-transformers.
Deep Visual Geo-localization Benchmark
Apr 07, 2022



In this paper, we propose a new open-source benchmarking framework for Visual Geo-localization (VG) that allows to build, train, and test a wide range of commonly used architectures, with the flexibility to change individual components of a geo-localization pipeline. The purpose of this framework is twofold: i) gaining insights into how different components and design choices in a VG pipeline impact the final results, both in terms of performance (recall@N metric) and system requirements (such as execution time and memory consumption); ii) establish a systematic evaluation protocol for comparing different methods. Using the proposed framework, we perform a large suite of experiments which provide criteria for choosing backbone, aggregation and negative mining depending on the use-case and requirements. We also assess the impact of engineering techniques like pre/post-processing, data augmentation and image resizing, showing that better performance can be obtained through somewhat simple procedures: for example, downscaling the images' resolution to 80% can lead to similar results with a 36% savings in extraction time and dataset storage requirement. Code and trained models are available at https://deep-vg-bench.herokuapp.com/.
Rethinking Visual Geo-localization for Large-Scale Applications
Apr 07, 2022



Visual Geo-localization (VG) is the task of estimating the position where a given photo was taken by comparing it with a large database of images of known locations. To investigate how existing techniques would perform on a real-world city-wide VG application, we build San Francisco eXtra Large, a new dataset covering a whole city and providing a wide range of challenging cases, with a size 30x bigger than the previous largest dataset for visual geo-localization. We find that current methods fail to scale to such large datasets, therefore we design a new highly scalable training technique, called CosPlace, which casts the training as a classification problem avoiding the expensive mining needed by the commonly used contrastive learning. We achieve state-of-the-art performance on a wide range of datasets and find that CosPlace is robust to heavy domain changes. Moreover, we show that, compared to the previous state-of-the-art, CosPlace requires roughly 80% less GPU memory at train time, and it achieves better results with 8x smaller descriptors, paving the way for city-wide real-world visual geo-localization. Dataset, code and trained models are available for research purposes at https://github.com/gmberton/CosPlace.
Learning Semantics for Visual Place Recognition through Multi-Scale Attention
Jan 25, 2022



In this paper we address the task of visual place recognition (VPR), where the goal is to retrieve the correct GPS coordinates of a given query image against a huge geotagged gallery. While recent works have shown that building descriptors incorporating semantic and appearance information is beneficial, current state-of-the-art methods opt for a top down definition of the significant semantic content. Here we present the first VPR algorithm that learns robust global embeddings from both visual appearance and semantic content of the data, with the segmentation process being dynamically guided by the recognition of places through a multi-scale attention module. Experiments on various scenarios validate this new approach and demonstrate its performance against state-of-the-art methods. Finally, we propose the first synthetic-world dataset suited for both place recognition and segmentation tasks.