 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGagandeep Singh
Is Watermarking LLM-Generated Code Robust?
Mar 24, 2024
We present the first study of the robustness of existing watermarking techniques on Python code generated by large language models. Although existing works showed that watermarking can be robust for natural language, we show that it is easy to remove these watermarks on code by semantic-preserving transformations.
Improving LLM Code Generation with Grammar Augmentation
Mar 03, 2024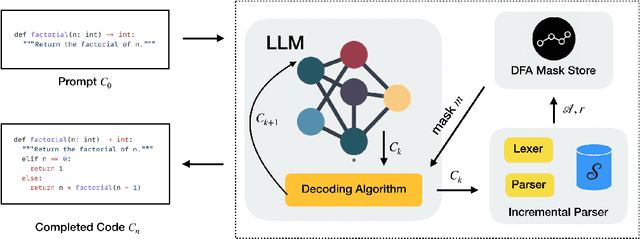
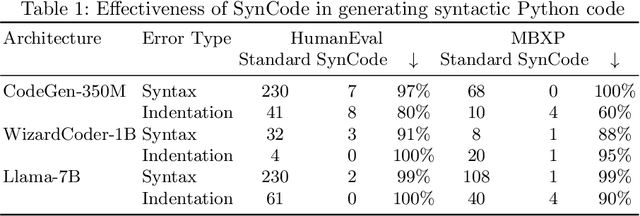
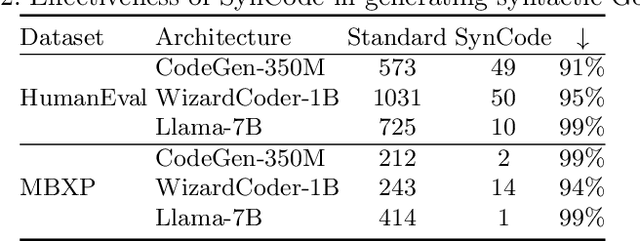

We present SynCode a novel framework for efficient and general syntactical decoding of code with large language models (LLMs). SynCode leverages the grammar of a programming language, utilizing an offline-constructed efficient lookup table called DFA mask store based on language grammar terminals. We demonstrate SynCode's soundness and completeness given the context-free grammar (CFG) of the programming language, presenting its ability to retain syntactically valid tokens while rejecting invalid ones. The framework seamlessly integrates with any language defined by CFG, as evidenced by experiments on CFGs for Python and Go. The results underscore the significant reduction of 96.07% of syntax errors achieved when SynCode is combined with state-of-the-art LLMs, showcasing its substantial impact on enhancing syntactical precision in code generation. Our code is available at https://github.com/uiuc-focal-lab/syncode.
QuaCer-C: Quantitative Certification of Knowledge Comprehension in LLMs
Feb 24, 2024Large Language Models (LLMs) have demonstrated impressive performance on several benchmarks. However, traditional studies do not provide formal guarantees on the performance of LLMs. In this work, we propose a novel certification framework for LLM, QuaCer-C, wherein we formally certify the knowledge-comprehension capabilities of popular LLMs. Our certificates are quantitative - they consist of high-confidence, tight bounds on the probability that the target LLM gives the correct answer on any relevant knowledge comprehension prompt. Our certificates for the Llama, Vicuna, and Mistral LLMs indicate that the knowledge comprehension capability improves with an increase in the number of parameters and that the Mistral model is less performant than the rest in this evaluation.
Reward Poisoning Attack Against Offline Reinforcement Learning
Feb 15, 2024We study the problem of reward poisoning attacks against general offline reinforcement learning with deep neural networks for function approximation. We consider a black-box threat model where the attacker is completely oblivious to the learning algorithm and its budget is limited by constraining both the amount of corruption at each data point, and the total perturbation. We propose an attack strategy called `policy contrast attack'. The high-level idea is to make some low-performing policies appear as high-performing while making high-performing policies appear as low-performing. To the best of our knowledge, we propose the first black-box reward poisoning attack in the general offline RL setting. We provide theoretical insights on the attack design and empirically show that our attack is efficient against current state-of-the-art offline RL algorithms in different kinds of learning datasets.
RAMP: Boosting Adversarial Robustness Against Multiple $l_p$ Perturbations
Feb 09, 2024There is considerable work on improving robustness against adversarial attacks bounded by a single $l_p$ norm using adversarial training (AT). However, the multiple-norm robustness (union accuracy) of AT models is still low. We observe that simultaneously obtaining good union and clean accuracy is hard since there are tradeoffs between robustness against multiple $l_p$ perturbations, and accuracy/robustness/efficiency. By analyzing the tradeoffs from the lens of distribution shifts, we identify the key tradeoff pair among $l_p$ attacks to boost efficiency and design a logit pairing loss to improve the union accuracy. Next, we connect natural training with AT via gradient projection, to find and incorporate useful information from natural training into AT, which moderates the accuracy/robustness tradeoff. Combining our contributions, we propose a framework called \textbf{RAMP}, to boost the robustness against multiple $l_p$ perturbations. We show \textbf{RAMP} can be easily adapted for both robust fine-tuning and full AT. For robust fine-tuning, \textbf{RAMP} obtains a union accuracy up to $53.5\%$ on CIFAR-10, and $29.7\%$ on ImageNet. For training from scratch, \textbf{RAMP} achieves SOTA union accuracy of $44.6\%$ and relatively good clean accuracy of $81.2\%$ on ResNet-18 against AutoAttack on CIFAR-10.
Efficient Two-Phase Offline Deep Reinforcement Learning from Preference Feedback
Dec 30, 2023In this work, we consider the offline preference-based reinforcement learning problem. We focus on the two-phase learning approach that is prevalent in previous reinforcement learning from human preference works. We find a challenge in applying two-phase learning in the offline PBRL setting that the learned utility model can be too hard for the learning agent to optimize during the second learning phase. To overcome the challenge, we propose a two-phasing learning approach under behavior regularization through action clipping. The insight is that the state-actions which are poorly covered by the dataset can only provide limited information and increase the complexity of the problem in the second learning phase. Our method ignores such state-actions during the second learning phase to achieve higher learning efficiency. We empirically verify that our method has high learning efficiency on a variety of datasets in robotic control environments.
Bypassing the Safety Training of Open-Source LLMs with Priming Attacks
Dec 19, 2023With the recent surge in popularity of LLMs has come an ever-increasing need for LLM safety training. In this paper, we show that SOTA open-source LLMs are vulnerable to simple, optimization-free attacks we refer to as $\textit{priming attacks}$, which are easy to execute and effectively bypass alignment from safety training. Our proposed attack improves the Attack Success Rate on Harmful Behaviors, as measured by Llama Guard, by up to $3.3\times$ compared to baselines. Source code and data are available at https://github.com/uiuc-focal-lab/llm-priming-attacks .
FedCompass: Efficient Cross-Silo Federated Learning on Heterogeneous Client Devices using a Computing Power Aware Scheduler
Sep 26, 2023


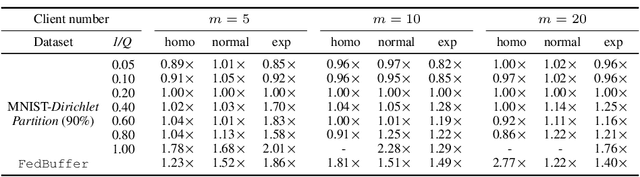
Cross-silo federated learning offers a promising solution to collaboratively train robust and generalized AI models without compromising the privacy of local datasets, e.g., healthcare, financial, as well as scientific projects that lack a centralized data facility. Nonetheless, because of the disparity of computing resources among different clients (i.e., device heterogeneity), synchronous federated learning algorithms suffer from degraded efficiency when waiting for straggler clients. Similarly, asynchronous federated learning algorithms experience degradation in the convergence rate and final model accuracy on non-identically and independently distributed (non-IID) heterogeneous datasets due to stale local models and client drift. To address these limitations in cross-silo federated learning with heterogeneous clients and data, we propose FedCompass, an innovative semi-asynchronous federated learning algorithm with a computing power aware scheduler on the server side, which adaptively assigns varying amounts of training tasks to different clients using the knowledge of the computing power of individual clients. FedCompass ensures that multiple locally trained models from clients are received almost simultaneously as a group for aggregation, effectively reducing the staleness of local models. At the same time, the overall training process remains asynchronous, eliminating prolonged waiting periods from straggler clients. Using diverse non-IID heterogeneous distributed datasets, we demonstrate that FedCompass achieves faster convergence and higher accuracy than other asynchronous algorithms while remaining more efficient than synchronous algorithms when performing federated learning on heterogeneous clients.
Incremental Randomized Smoothing Certification
May 31, 2023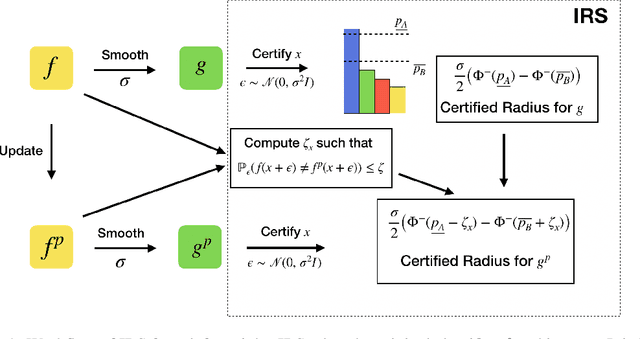
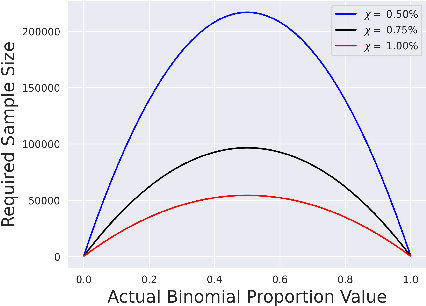


Randomized smoothing-based certification is an effective approach for obtaining robustness certificates of deep neural networks (DNNs) against adversarial attacks. This method constructs a smoothed DNN model and certifies its robustness through statistical sampling, but it is computationally expensive, especially when certifying with a large number of samples. Furthermore, when the smoothed model is modified (e.g., quantized or pruned), certification guarantees may not hold for the modified DNN, and recertifying from scratch can be prohibitively expensive. We present the first approach for incremental robustness certification for randomized smoothing, IRS. We show how to reuse the certification guarantees for the original smoothed model to certify an approximated model with very few samples. IRS significantly reduces the computational cost of certifying modified DNNs while maintaining strong robustness guarantees. We experimentally demonstrate the effectiveness of our approach, showing up to 3x certification speedup over the certification that applies randomized smoothing of the approximate model from scratch.
Black-Box Targeted Reward Poisoning Attack Against Online Deep Reinforcement Learning
May 18, 2023
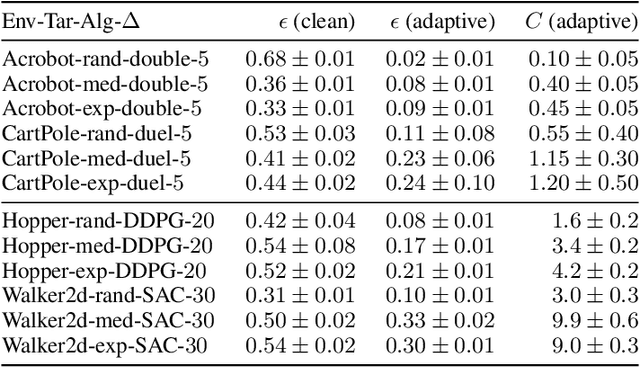
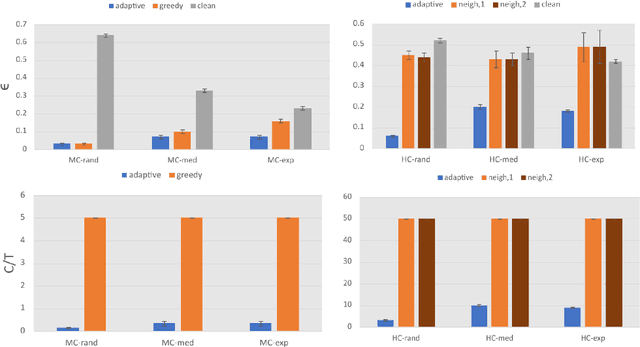
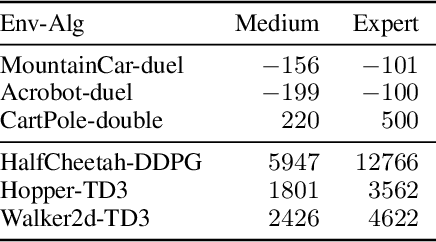
We propose the first black-box targeted attack against online deep reinforcement learning through reward poisoning during training time. Our attack is applicable to general environments with unknown dynamics learned by unknown algorithms and requires limited attack budgets and computational resources. We leverage a general framework and find conditions to ensure efficient attack under a general assumption of the learning algorithms. We show that our attack is optimal in our framework under the conditions. We experimentally verify that with limited budgets, our attack efficiently leads the learning agent to various target policies under a diverse set of popular DRL environments and state-of-the-art learners.