 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeonhwa Jeong
Abstracting Sparse DNN Acceleration via Structured Sparse Tensor Decomposition
Mar 12, 2024
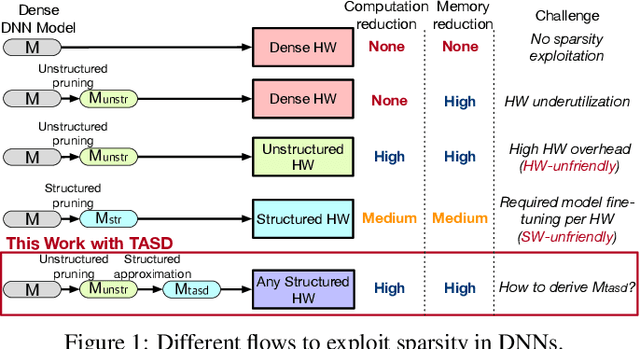
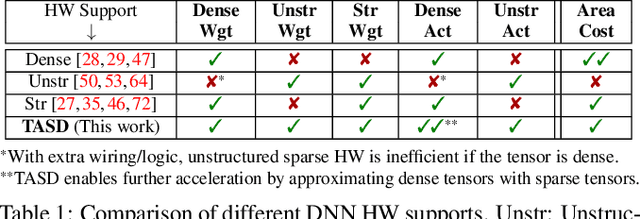


Exploiting sparsity in deep neural networks (DNNs) has been a promising area to meet the growing computation need of modern DNNs. However, in practice, sparse DNN acceleration still faces a key challenge. To minimize the overhead of sparse acceleration, hardware designers have proposed structured sparse hardware support recently, which provides limited flexibility and requires extra model fine-tuning. Moreover, any sparse model fine-tuned for certain structured sparse hardware cannot be accelerated by other structured hardware. To bridge the gap between sparse DNN models and hardware, this paper proposes tensor approximation via structured decomposition (TASD), which leverages the distributive property in linear algebra to turn any sparse tensor into a series of structured sparse tensors. Next, we develop a software framework, TASDER, to accelerate DNNs by searching layer-wise, high-quality structured decomposition for both weight and activation tensors so that they can be accelerated by any systems with structured sparse hardware support. Evaluation results show that, by exploiting prior structured sparse hardware baselines, our method can accelerate off-the-shelf dense and sparse DNNs without fine-tuning and improves energy-delay-product by up to 83% and 74% on average.
GEAR: An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM
Mar 11, 2024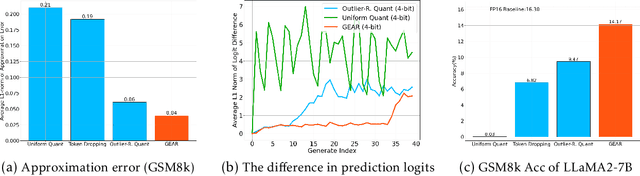
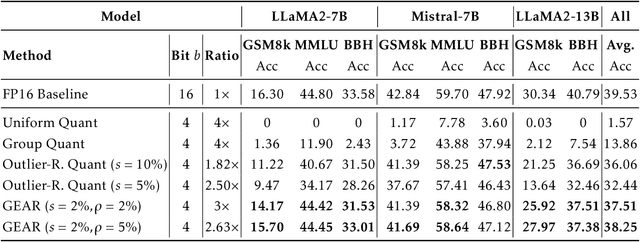
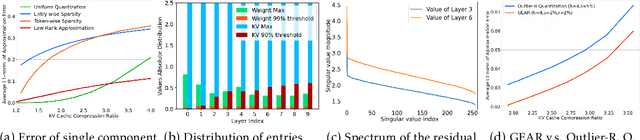
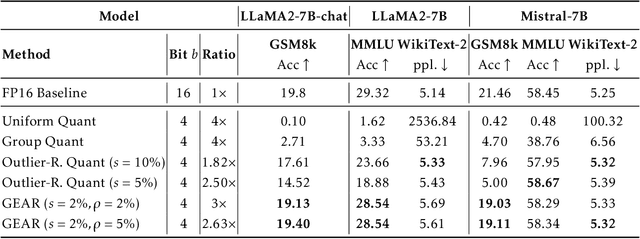
Key-value (KV) caching has become the de-facto to accelerate generation speed for large language models (LLMs) inference. However, the growing cache demand with increasing sequence length has transformed LLM inference to be a memory bound problem, significantly constraining the system throughput. Existing methods rely on dropping unimportant tokens or quantizing all entries uniformly. Such methods, however, often incur high approximation errors to represent the compressed matrices. The autoregressive decoding process further compounds the error of each step, resulting in critical deviation in model generation and deterioration of performance. To tackle this challenge, we propose GEAR, an efficient KV cache compression framework that achieves near-lossless high-ratio compression. GEAR first applies quantization to majority of entries of similar magnitudes to ultra-low precision. It then employs a low rank matrix to approximate the quantization error, and a sparse matrix to remedy individual errors from outlier entries. By adeptly integrating three techniques, GEAR is able to fully exploit their synergistic potentials. Our experiments demonstrate that compared to alternatives, GEAR achieves near-lossless 4-bit KV cache compression with up to 2.38x throughput improvement, while reducing peak-memory size up to 2.29x. Our code is publicly available at https://github.com/HaoKang-Timmy/GEAR.
Algorithm-Hardware Co-Design of Distribution-Aware Logarithmic-Posit Encodings for Efficient DNN Inference
Mar 08, 2024



Traditional Deep Neural Network (DNN) quantization methods using integer, fixed-point, or floating-point data types struggle to capture diverse DNN parameter distributions at low precision, and often require large silicon overhead and intensive quantization-aware training. In this study, we introduce Logarithmic Posits (LP), an adaptive, hardware-friendly data type inspired by posits that dynamically adapts to DNN weight/activation distributions by parameterizing LP bit fields. We also develop a novel genetic-algorithm based framework, LP Quantization (LPQ), to find optimal layer-wise LP parameters while reducing representational divergence between quantized and full-precision models through a novel global-local contrastive objective. Additionally, we design a unified mixed-precision LP accelerator (LPA) architecture comprising of processing elements (PEs) incorporating LP in the computational datapath. Our algorithm-hardware co-design demonstrates on average <1% drop in top-1 accuracy across various CNN and ViT models. It also achieves ~ 2x improvements in performance per unit area and 2.2x gains in energy efficiency compared to state-of-the-art quantization accelerators using different data types.
VEGETA: Vertically-Integrated Extensions for Sparse/Dense GEMM Tile Acceleration on CPUs
Feb 23, 2023



Deep Learning (DL) acceleration support in CPUs has recently gained a lot of traction, with several companies (Arm, Intel, IBM) announcing products with specialized matrix engines accessible via GEMM instructions. CPUs are pervasive and need to handle diverse requirements across DL workloads running in edge/HPC/cloud platforms. Therefore, as DL workloads embrace sparsity to reduce the computations and memory size of models, it is also imperative for CPUs to add support for sparsity to avoid under-utilization of the dense matrix engine and inefficient usage of the caches and registers. This work presents VEGETA, a set of ISA and microarchitecture extensions over dense matrix engines to support flexible structured sparsity for CPUs, enabling programmable support for diverse DL models with varying degrees of sparsity. Compared to the state-of-the-art (SOTA) dense matrix engine in CPUs, a VEGETA engine provides 1.09x, 2.20x, 3.74x, and 3.28x speed-ups when running 4:4 (dense), 2:4, 1:4, and unstructured (95%) sparse DNN layers.
RASA: Efficient Register-Aware Systolic Array Matrix Engine for CPU
Oct 05, 2021



As AI-based applications become pervasive, CPU vendors are starting to incorporate matrix engines within the datapath to boost efficiency. Systolic arrays have been the premier architectural choice as matrix engines in offload accelerators. However, we demonstrate that incorporating them inside CPUs can introduce under-utilization and stalls due to limited register storage to amortize the fill and drain times of the array. To address this, we propose RASA, Register-Aware Systolic Array. We develop techniques to divide an execution stage into several sub-stages and overlap instructions to hide overheads and run them concurrently. RASA-based designs improve performance significantly with negligible area and power overhead.
Union: A Unified HW-SW Co-Design Ecosystem in MLIR for Evaluating Tensor Operations on Spatial Accelerators
Sep 17, 2021



To meet the extreme compute demands for deep learning across commercial and scientific applications, dataflow accelerators are becoming increasingly popular. While these "domain-specific" accelerators are not fully programmable like CPUs and GPUs, they retain varying levels of flexibility with respect to data orchestration, i.e., dataflow and tiling optimizations to enhance efficiency. There are several challenges when designing new algorithms and mapping approaches to execute the algorithms for a target problem on new hardware. Previous works have addressed these challenges individually. To address this challenge as a whole, in this work, we present a HW-SW co-design ecosystem for spatial accelerators called Union within the popular MLIR compiler infrastructure. Our framework allows exploring different algorithms and their mappings on several accelerator cost models. Union also includes a plug-and-play library of accelerator cost models and mappers which can easily be extended. The algorithms and accelerator cost models are connected via a novel mapping abstraction that captures the map space of spatial accelerators which can be systematically pruned based on constraints from the hardware, workload, and mapper. We demonstrate the value of Union for the community with several case studies which examine offloading different tensor operations(CONV/GEMM/Tensor Contraction) on diverse accelerator architectures using different mapping schemes.
Evaluating Spatial Accelerator Architectures with Tiled Matrix-Matrix Multiplication
Jun 19, 2021



There is a growing interest in custom spatial accelerators for machine learning applications. These accelerators employ a spatial array of processing elements (PEs) interacting via custom buffer hierarchies and networks-on-chip. The efficiency of these accelerators comes from employing optimized dataflow (i.e., spatial/temporal partitioning of data across the PEs and fine-grained scheduling) strategies to optimize data reuse. The focus of this work is to evaluate these accelerator architectures using a tiled general matrix-matrix multiplication (GEMM) kernel. To do so, we develop a framework that finds optimized mappings (dataflow and tile sizes) for a tiled GEMM for a given spatial accelerator and workload combination, leveraging an analytical cost model for runtime and energy. Our evaluations over five spatial accelerators demonstrate that the tiled GEMM mappings systematically generated by our framework achieve high performance on various GEMM workloads and accelerators.
ConfuciuX: Autonomous Hardware Resource Assignment for DNN Accelerators using Reinforcement Learning
Sep 04, 2020



DNN accelerators provide efficiency by leveraging reuse of activations/weights/outputs during the DNN computations to reduce data movement from DRAM to the chip. The reuse is captured by the accelerator's dataflow. While there has been significant prior work in exploring and comparing various dataflows, the strategy for assigning on-chip hardware resources (i.e., compute and memory) given a dataflow that can optimize for performance/energy while meeting platform constraints of area/power for DNN(s) of interest is still relatively unexplored. The design-space of choices for balancing compute and memory explodes combinatorially, as we show in this work (e.g., as large as O(10^(72)) choices for running \mobilenet), making it infeasible to do manual-tuning via exhaustive searches. It is also difficult to come up with a specific heuristic given that different DNNs and layer types exhibit different amounts of reuse. In this paper, we propose an autonomous strategy called ConfuciuX to find optimized HW resource assignments for a given model and dataflow style. ConfuciuX leverages a reinforcement learning method, REINFORCE, to guide the search process, leveraging a detailed HW performance cost model within the training loop to estimate rewards. We also augment the RL approach with a genetic algorithm for further fine-tuning. ConfuciuX demonstrates the highest sample-efficiency for training compared to other techniques such as Bayesian optimization, genetic algorithm, simulated annealing, and other RL methods. It converges to the optimized hardware configuration 4.7 to 24 times faster than alternate techniques.