 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeorge Deligiannidis
Particle Denoising Diffusion Sampler
Feb 09, 2024
Denoising diffusion models have become ubiquitous for generative modeling. The core idea is to transport the data distribution to a Gaussian by using a diffusion. Approximate samples from the data distribution are then obtained by estimating the time-reversal of this diffusion using score matching ideas. We follow here a similar strategy to sample from unnormalized probability densities and compute their normalizing constants. However, the time-reversed diffusion is here simulated by using an original iterative particle scheme relying on a novel score matching loss. Contrary to standard denoising diffusion models, the resulting Particle Denoising Diffusion Sampler (PDDS) provides asymptotically consistent estimates under mild assumptions. We demonstrate PDDS on multimodal and high dimensional sampling tasks.
Linear Convergence Bounds for Diffusion Models via Stochastic Localization
Aug 07, 2023

Diffusion models are a powerful method for generating approximate samples from high-dimensional data distributions. Several recent results have provided polynomial bounds on the convergence rate of such models, assuming $L^2$-accurate score estimators. However, up until now the best known such bounds were either superlinear in the data dimension or required strong smoothness assumptions. We provide the first convergence bounds which are linear in the data dimension (up to logarithmic factors) assuming only finite second moments of the data distribution. We show that diffusion models require at most $\tilde O(\frac{d \log^2(1/\delta)}{\varepsilon^2})$ steps to approximate an arbitrary data distribution on $\mathbb{R}^d$ corrupted with Gaussian noise of variance $\delta$ to within $\varepsilon^2$ in Kullback--Leibler divergence. Our proof builds on the Girsanov-based methods of previous works. We introduce a refined treatment of the error arising from the discretization of the reverse SDE, which is based on tools from stochastic localization.
On the Expected Size of Conformal Prediction Sets
Jun 12, 2023
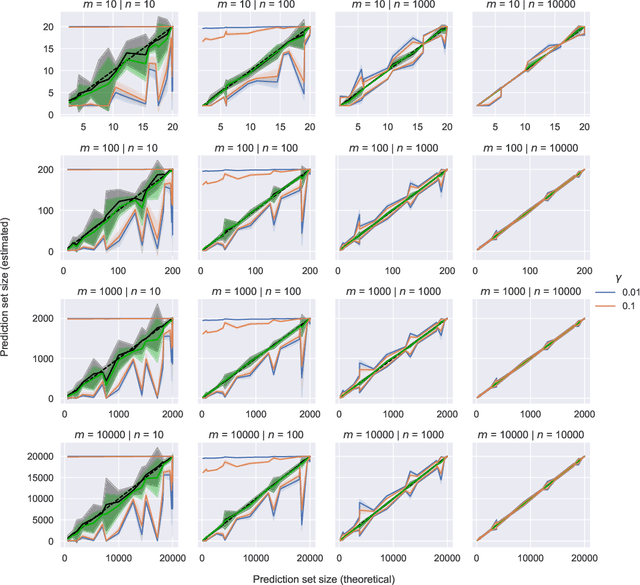
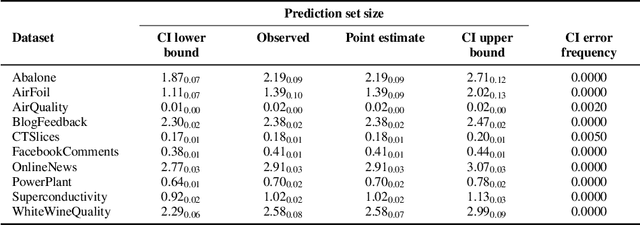
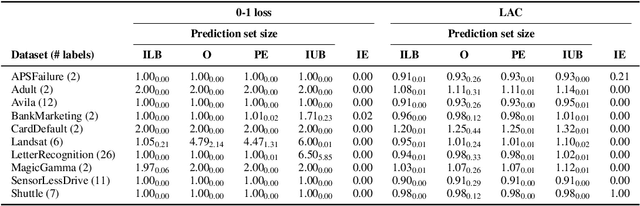
While conformal predictors reap the benefits of rigorous statistical guarantees for their error frequency, the size of their corresponding prediction sets is critical to their practical utility. Unfortunately, there is currently a lack of finite-sample analysis and guarantees for their prediction set sizes. To address this shortfall, we theoretically quantify the expected size of the prediction set under the split conformal prediction framework. As this precise formulation cannot usually be calculated directly, we further derive point estimates and high probability intervals that can be easily computed, providing a practical method for characterizing the expected prediction set size across different possible realizations of the test and calibration data. Additionally, we corroborate the efficacy of our results with experiments on real-world datasets, for both regression and classification problems.
A Unified Framework for U-Net Design and Analysis
May 31, 2023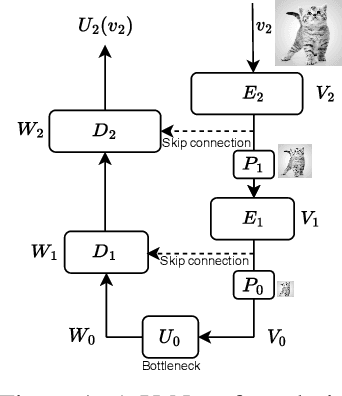

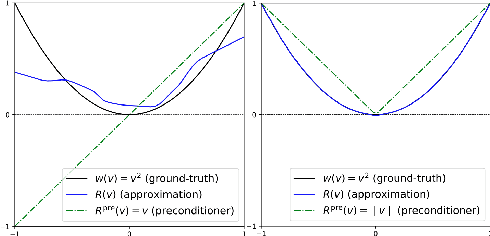

U-Nets are a go-to, state-of-the-art neural architecture across numerous tasks for continuous signals on a square such as images and Partial Differential Equations (PDE), however their design and architecture is understudied. In this paper, we provide a framework for designing and analysing general U-Net architectures. We present theoretical results which characterise the role of the encoder and decoder in a U-Net, their high-resolution scaling limits and their conjugacy to ResNets via preconditioning. We propose Multi-ResNets, U-Nets with a simplified, wavelet-based encoder without learnable parameters. Further, we show how to design novel U-Net architectures which encode function constraints, natural bases, or the geometry of the data. In diffusion models, our framework enables us to identify that high-frequency information is dominated by noise exponentially faster, and show how U-Nets with average pooling exploit this. In our experiments, we demonstrate how Multi-ResNets achieve competitive and often superior performance compared to classical U-Nets in image segmentation, PDE surrogate modelling, and generative modelling with diffusion models. Our U-Net framework paves the way to study the theoretical properties of U-Nets and design natural, scalable neural architectures for a multitude of problems beyond the square.
Error Bounds for Flow Matching Methods
May 26, 2023Score-based generative models are a popular class of generative modelling techniques relying on stochastic differential equations (SDE). From their inception, it was realized that it was also possible to perform generation using ordinary differential equations (ODE) rather than SDE. This led to the introduction of the probability flow ODE approach and denoising diffusion implicit models. Flow matching methods have recently further extended these ODE-based approaches and approximate a flow between two arbitrary probability distributions. Previous work derived bounds on the approximation error of diffusion models under the stochastic sampling regime, given assumptions on the $L^2$ loss. We present error bounds for the flow matching procedure using fully deterministic sampling, assuming an $L^2$ bound on the approximation error and a certain regularity condition on the data distributions.
Generalization Bounds with Data-dependent Fractal Dimensions
Feb 06, 2023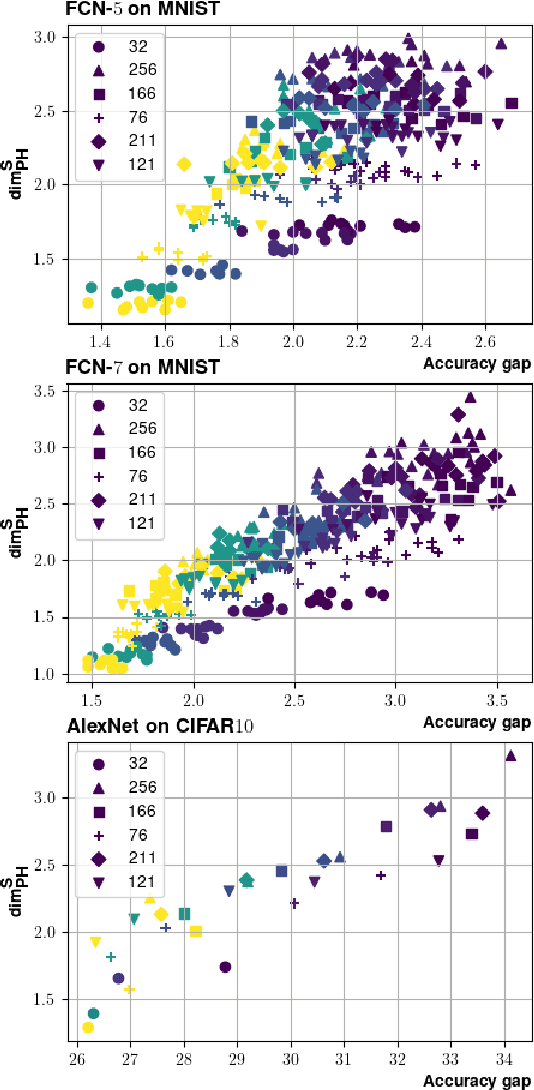
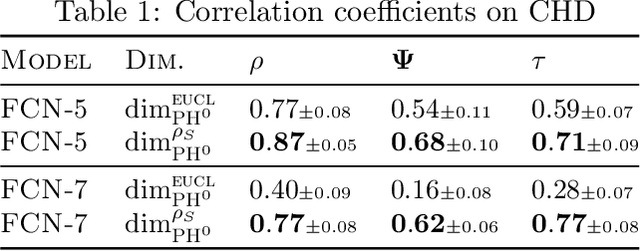
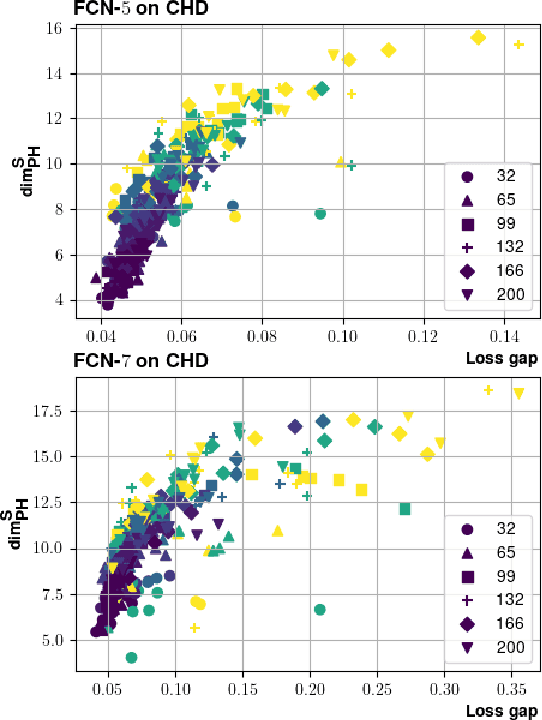
Providing generalization guarantees for modern neural networks has been a crucial task in statistical learning. Recently, several studies have attempted to analyze the generalization error in such settings by using tools from fractal geometry. While these works have successfully introduced new mathematical tools to apprehend generalization, they heavily rely on a Lipschitz continuity assumption, which in general does not hold for neural networks and might make the bounds vacuous. In this work, we address this issue and prove fractal geometry-based generalization bounds without requiring any Lipschitz assumption. To achieve this goal, we build up on a classical covering argument in learning theory and introduce a data-dependent fractal dimension. Despite introducing a significant amount of technical complications, this new notion lets us control the generalization error (over either fixed or random hypothesis spaces) along with certain mutual information (MI) terms. To provide a clearer interpretation to the newly introduced MI terms, as a next step, we introduce a notion of "geometric stability" and link our bounds to the prior art. Finally, we make a rigorous connection between the proposed data-dependent dimension and topological data analysis tools, which then enables us to compute the dimension in a numerically efficient way. We support our theory with experiments conducted on various settings.
A Multi-Resolution Framework for U-Nets with Applications to Hierarchical VAEs
Jan 19, 2023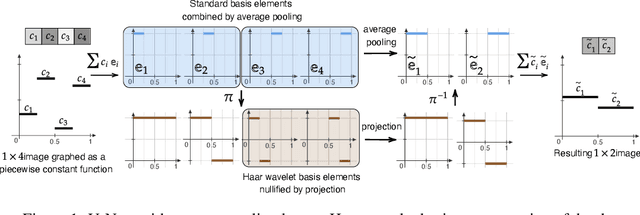
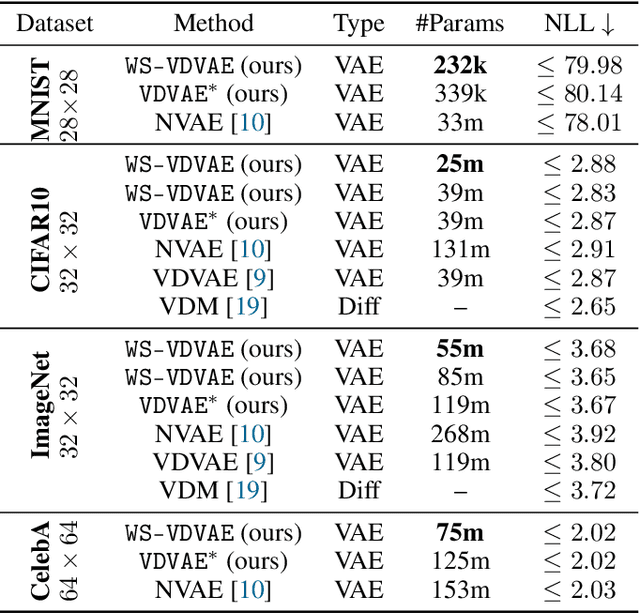
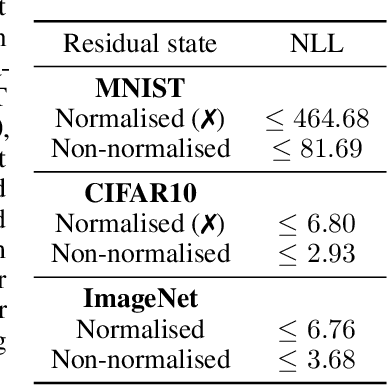
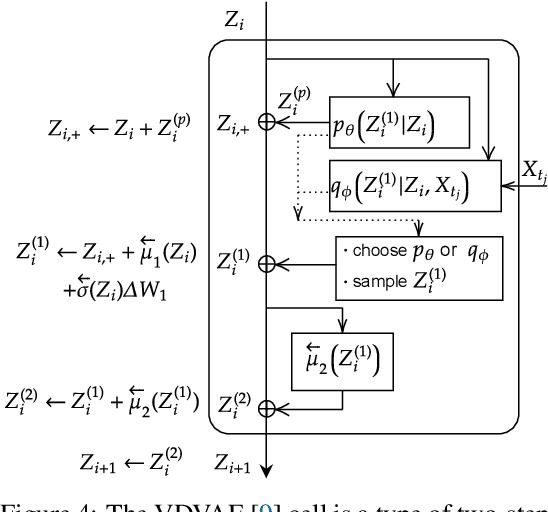
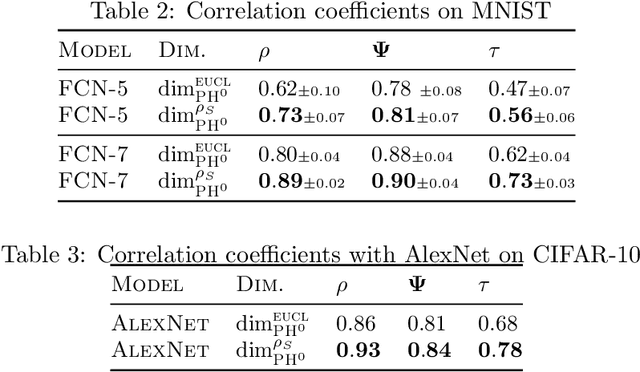
U-Net architectures are ubiquitous in state-of-the-art deep learning, however their regularisation properties and relationship to wavelets are understudied. In this paper, we formulate a multi-resolution framework which identifies U-Nets as finite-dimensional truncations of models on an infinite-dimensional function space. We provide theoretical results which prove that average pooling corresponds to projection within the space of square-integrable functions and show that U-Nets with average pooling implicitly learn a Haar wavelet basis representation of the data. We then leverage our framework to identify state-of-the-art hierarchical VAEs (HVAEs), which have a U-Net architecture, as a type of two-step forward Euler discretisation of multi-resolution diffusion processes which flow from a point mass, introducing sampling instabilities. We also demonstrate that HVAEs learn a representation of time which allows for improved parameter efficiency through weight-sharing. We use this observation to achieve state-of-the-art HVAE performance with half the number of parameters of existing models, exploiting the properties of our continuous-time formulation.
From Denoising Diffusions to Denoising Markov Models
Nov 07, 2022
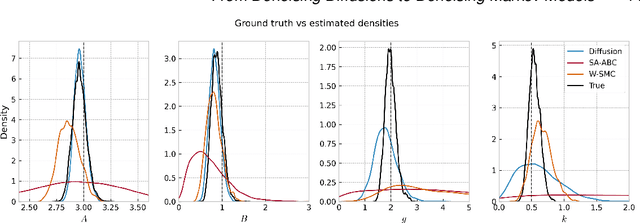
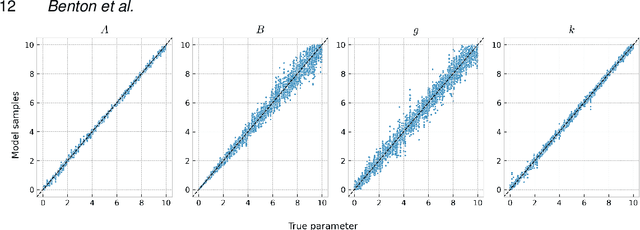
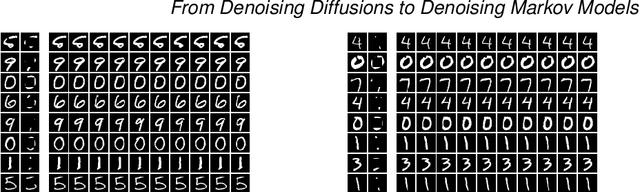
Denoising diffusions are state-of-the-art generative models which exhibit remarkable empirical performance and come with theoretical guarantees. The core idea of these models is to progressively transform the empirical data distribution into a simple Gaussian distribution by adding noise using a diffusion. We obtain new samples whose distribution is close to the data distribution by simulating a "denoising" diffusion approximating the time reversal of this "noising" diffusion. This denoising diffusion relies on approximations of the logarithmic derivatives of the noised data densities, known as scores, obtained using score matching. Such models can be easily extended to perform approximate posterior simulation in high-dimensional scenarios where one can only sample from the prior and simulate synthetic observations from the likelihood. These methods have been primarily developed for data on $\mathbb{R}^d$ while extensions to more general spaces have been developed on a case-by-case basis. We propose here a general framework which not only unifies and generalizes this approach to a wide class of spaces but also leads to an original extension of score matching. We illustrate the resulting class of denoising Markov models on various applications.
A PAC-Bayes bound for deterministic classifiers
Sep 06, 2022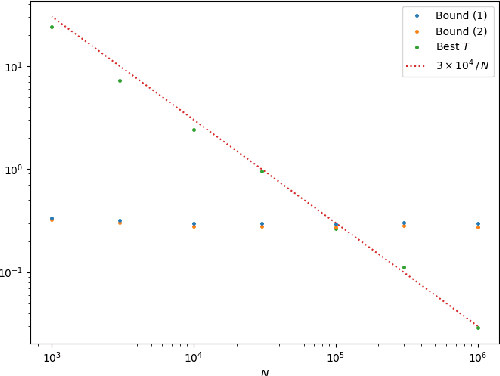
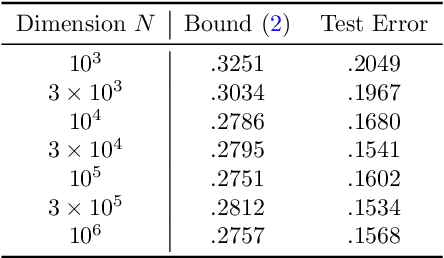
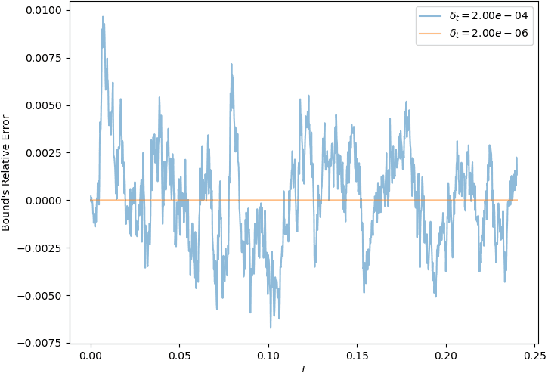

We establish a disintegrated PAC-Bayesian bound, for classifiers that are trained via continuous-time (non-stochastic) gradient descent. Contrarily to what is standard in the PAC-Bayesian setting, our result applies to a training algorithm that is deterministic, conditioned on a random initialisation, without requiring any $\textit{de-randomisation}$ step. We provide a broad discussion of the main features of the bound that we propose, and we study analytically and empirically its behaviour on linear models, finding promising results.
Ranking in Contextual Multi-Armed Bandits
Jun 30, 2022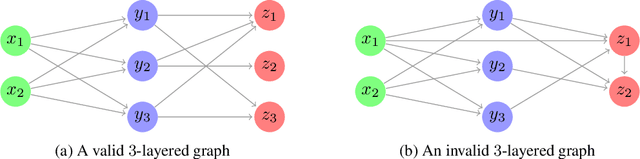
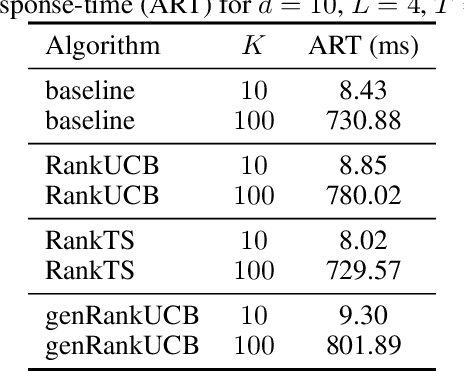
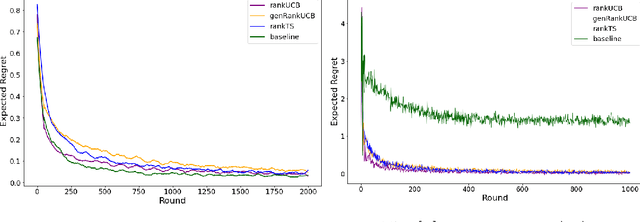
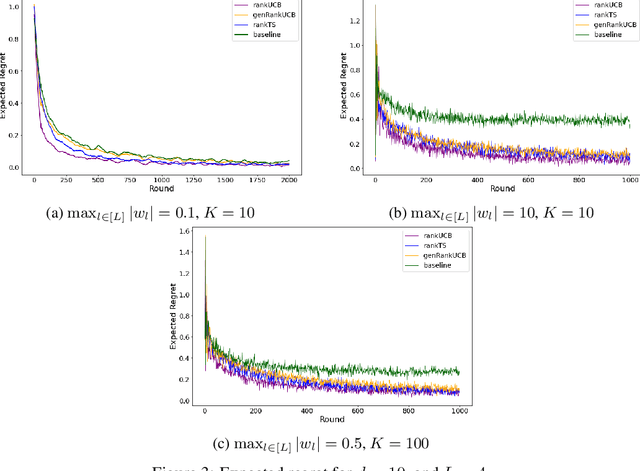
We study a ranking problem in the contextual multi-armed bandit setting. A learning agent selects an ordered list of items at each time step and observes stochastic outcomes for each position. In online recommendation systems, showing an ordered list of the most attractive items would not be the best choice since both position and item dependencies result in a complicated reward function. A very naive example is the lack of diversity when all the most attractive items are from the same category. We model position and item dependencies in the ordered list and design UCB and Thompson Sampling type algorithms for this problem. We prove that the regret bound over $T$ rounds and $L$ positions is $\Tilde{O}(L\sqrt{d T})$, which has the same order as the previous works with respect to $T$ and only increases linearly with $L$. Our work generalizes existing studies in several directions, including position dependencies where position discount is a particular case, and proposes a more general contextual bandit model.