 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeorgios C. Chasparis
AI-Powered Predictions for Electricity Load in Prosumer Communities
Feb 21, 2024
The flexibility in electricity consumption and production in communities of residential buildings, including those with renewable energy sources and energy storage (a.k.a., prosumers), can effectively be utilized through the advancement of short-term demand response mechanisms. It is known that flexibility can further be increased if demand response is performed at the level of communities of prosumers, since aggregated groups can better coordinate electricity consumption. However, the effectiveness of such short-term optimization is highly dependent on the accuracy of electricity load forecasts both for each building as well as for the whole community. Structural variations in the electricity load profile can be associated with different exogenous factors, such as weather conditions, calendar information and day of the week, as well as user behavior. In this paper, we review a wide range of electricity load forecasting techniques, that can provide significant assistance in optimizing load consumption in prosumer communities. We present and test artificial intelligence (AI) powered short-term load forecasting methodologies that operate with black-box time series models, such as Facebook's Prophet and Long Short-term Memory (LSTM) models; season-based SARIMA and smoothing Holt-Winters models; and empirical regression-based models that utilize domain knowledge. The integration of weather forecasts into data-driven time series forecasts is also tested. Results show that the combination of persistent and regression terms (adapted to the load forecasting task) achieves the best forecast accuracy.
Hierarchical Framework for Interpretable and Probabilistic Model-Based Safe Reinforcement Learning
Oct 28, 2023



The difficulty of identifying the physical model of complex systems has led to exploring methods that do not rely on such complex modeling of the systems. Deep reinforcement learning has been the pioneer for solving this problem without the need for relying on the physical model of complex systems by just interacting with it. However, it uses a black-box learning approach that makes it difficult to be applied within real-world and safety-critical systems without providing explanations of the actions derived by the model. Furthermore, an open research question in deep reinforcement learning is how to focus the policy learning of critical decisions within a sparse domain. This paper proposes a novel approach for the use of deep reinforcement learning in safety-critical systems. It combines the advantages of probabilistic modeling and reinforcement learning with the added benefits of interpretability and works in collaboration and synchronization with conventional decision-making strategies. The BC-SRLA is activated in specific situations which are identified autonomously through the fused information of probabilistic model and reinforcement learning, such as abnormal conditions or when the system is near-to-failure. Further, it is initialized with a baseline policy using policy cloning to allow minimum interactions with the environment to address the challenges associated with using RL in safety-critical industries. The effectiveness of the BC-SRLA is demonstrated through a case study in maintenance applied to turbofan engines, where it shows superior performance to the prior art and other baselines.
* arXiv admin note: text overlap with arXiv:2206.13433
Specialized Deep Residual Policy Safe Reinforcement Learning-Based Controller for Complex and Continuous State-Action Spaces
Oct 15, 2023



Traditional controllers have limitations as they rely on prior knowledge about the physics of the problem, require modeling of dynamics, and struggle to adapt to abnormal situations. Deep reinforcement learning has the potential to address these problems by learning optimal control policies through exploration in an environment. For safety-critical environments, it is impractical to explore randomly, and replacing conventional controllers with black-box models is also undesirable. Also, it is expensive in continuous state and action spaces, unless the search space is constrained. To address these challenges we propose a specialized deep residual policy safe reinforcement learning with a cycle of learning approach adapted for complex and continuous state-action spaces. Residual policy learning allows learning a hybrid control architecture where the reinforcement learning agent acts in synchronous collaboration with the conventional controller. The cycle of learning initiates the policy through the expert trajectory and guides the exploration around it. Further, the specialization through the input-output hidden Markov model helps to optimize policy that lies within the region of interest (such as abnormality), where the reinforcement learning agent is required and is activated. The proposed solution is validated on the Tennessee Eastman process control.
An Evolutionary Stochastic-Local-Search Framework for One-Dimensional Cutting-Stock Problems
Jul 27, 2017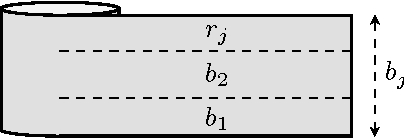


We introduce an evolutionary stochastic-local-search (SLS) algorithm for addressing a generalized version of the so-called 1/V/D/R cutting-stock problem. Cutting-stock problems are encountered often in industrial environments and the ability to address them efficiently usually results in large economic benefits. Traditionally linear-programming-based techniques have been utilized to address such problems, however their flexibility might be limited when nonlinear constraints and objective functions are introduced. To this end, this paper proposes an evolutionary SLS algorithm for addressing one-dimensional cutting-stock problems. The contribution lies in the introduction of a flexible structural framework of the optimization that may accommodate a large family of diversification strategies including a novel parallel pattern appropriate for SLS algorithms (not necessarily restricted to cutting-stock problems). We finally demonstrate through experiments in a real-world manufacturing problem the benefit in cost reduction of the considered diversification strategies.
Aspiration Learning in Coordination Games
Oct 19, 2011



We consider the problem of distributed convergence to efficient outcomes in coordination games through dynamics based on aspiration learning. Under aspiration learning, a player continues to play an action as long as the rewards received exceed a specified aspiration level. Here, the aspiration level is a fading memory average of past rewards, and these levels also are subject to occasional random perturbations. A player becomes dissatisfied whenever a received reward is less than the aspiration level, in which case the player experiments with a probability proportional to the degree of dissatisfaction. Our first contribution is the characterization of the asymptotic behavior of the induced Markov chain of the iterated process in terms of an equivalent finite-state Markov chain. We then characterize explicitly the behavior of the proposed aspiration learning in a generalized version of coordination games, examples of which include network formation and common-pool games. In particular, we show that in generic coordination games the frequency at which an efficient action profile is played can be made arbitrarily large. Although convergence to efficient outcomes is desirable, in several coordination games, such as common-pool games, attainability of fair outcomes, i.e., sequences of plays at which players experience highly rewarding returns with the same frequency, might also be of special interest. To this end, we demonstrate through analysis and simulations that aspiration learning also establishes fair outcomes in all symmetric coordination games, including common-pool games.