 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeorgios Piliouras
States as Strings as Strategies: Steering Language Models with Game-Theoretic Solvers
Feb 06, 2024
Game theory is the study of mathematical models of strategic interactions among rational agents. Language is a key medium of interaction for humans, though it has historically proven difficult to model dialogue and its strategic motivations mathematically. A suitable model of the players, strategies, and payoffs associated with linguistic interactions (i.e., a binding to the conventional symbolic logic of game theory) would enable existing game-theoretic algorithms to provide strategic solutions in the space of language. In other words, a binding could provide a route to computing stable, rational conversational strategies in dialogue. Large language models (LLMs) have arguably reached a point where their generative capabilities can enable realistic, human-like simulations of natural dialogue. By prompting them in various ways, we can steer their responses towards different output utterances. Leveraging the expressivity of natural language, LLMs can also help us quickly generate new dialogue scenarios, which are grounded in real world applications. In this work, we present one possible binding from dialogue to game theory as well as generalizations of existing equilibrium finding algorithms to this setting. In addition, by exploiting LLMs generation capabilities along with our proposed binding, we can synthesize a large repository of formally-defined games in which one can study and test game-theoretic solution concepts. We also demonstrate how one can combine LLM-driven game generation, game-theoretic solvers, and imitation learning to construct a process for improving the strategic capabilities of LLMs.
Neural Population Learning beyond Symmetric Zero-sum Games
Jan 10, 2024We study computationally efficient methods for finding equilibria in n-player general-sum games, specifically ones that afford complex visuomotor skills. We show how existing methods would struggle in this setting, either computationally or in theory. We then introduce NeuPL-JPSRO, a neural population learning algorithm that benefits from transfer learning of skills and converges to a Coarse Correlated Equilibrium (CCE) of the game. We show empirical convergence in a suite of OpenSpiel games, validated rigorously by exact game solvers. We then deploy NeuPL-JPSRO to complex domains, where our approach enables adaptive coordination in a MuJoCo control domain and skill transfer in capture-the-flag. Our work shows that equilibrium convergent population learning can be implemented at scale and in generality, paving the way towards solving real-world games between heterogeneous players with mixed motives.
Exploiting hidden structures in non-convex games for convergence to Nash equilibrium
Dec 27, 2023A wide array of modern machine learning applications - from adversarial models to multi-agent reinforcement learning - can be formulated as non-cooperative games whose Nash equilibria represent the system's desired operational states. Despite having a highly non-convex loss landscape, many cases of interest possess a latent convex structure that could potentially be leveraged to yield convergence to equilibrium. Driven by this observation, our paper proposes a flexible first-order method that successfully exploits such "hidden structures" and achieves convergence under minimal assumptions for the transformation connecting the players' control variables to the game's latent, convex-structured layer. The proposed method - which we call preconditioned hidden gradient descent (PHGD) - hinges on a judiciously chosen gradient preconditioning scheme related to natural gradient methods. Importantly, we make no separability assumptions for the game's hidden structure, and we provide explicit convergence rate guarantees for both deterministic and stochastic environments.
Scalable AI Safety via Doubly-Efficient Debate
Nov 23, 2023The emergence of pre-trained AI systems with powerful capabilities across a diverse and ever-increasing set of complex domains has raised a critical challenge for AI safety as tasks can become too complicated for humans to judge directly. Irving et al. [2018] proposed a debate method in this direction with the goal of pitting the power of such AI models against each other until the problem of identifying (mis)-alignment is broken down into a manageable subtask. While the promise of this approach is clear, the original framework was based on the assumption that the honest strategy is able to simulate deterministic AI systems for an exponential number of steps, limiting its applicability. In this paper, we show how to address these challenges by designing a new set of debate protocols where the honest strategy can always succeed using a simulation of a polynomial number of steps, whilst being able to verify the alignment of stochastic AI systems, even when the dishonest strategy is allowed to use exponentially many simulation steps.
A Quadratic Speedup in Finding Nash Equilibria of Quantum Zero-Sum Games
Nov 17, 2023Recent developments in domains such as non-local games, quantum interactive proofs, and quantum generative adversarial networks have renewed interest in quantum game theory and, specifically, quantum zero-sum games. Central to classical game theory is the efficient algorithmic computation of Nash equilibria, which represent optimal strategies for both players. In 2008, Jain and Watrous proposed the first classical algorithm for computing equilibria in quantum zero-sum games using the Matrix Multiplicative Weight Updates (MMWU) method to achieve a convergence rate of $\mathcal{O}(d/\epsilon^2)$ iterations to $\epsilon$-Nash equilibria in the $4^d$-dimensional spectraplex. In this work, we propose a hierarchy of quantum optimization algorithms that generalize MMWU via an extra-gradient mechanism. Notably, within this proposed hierarchy, we introduce the Optimistic Matrix Multiplicative Weights Update (OMMWU) algorithm and establish its average-iterate convergence complexity as $\mathcal{O}(d/\epsilon)$ iterations to $\epsilon$-Nash equilibria. This quadratic speed-up relative to Jain and Watrous' original algorithm sets a new benchmark for computing $\epsilon$-Nash equilibria in quantum zero-sum games.
Stability of Multi-Agent Learning: Convergence in Network Games with Many Players
Jul 26, 2023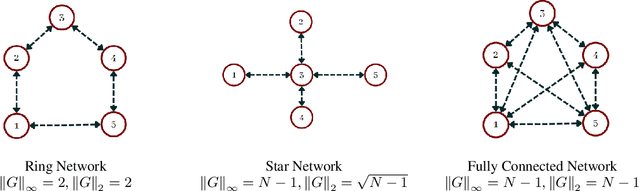


The behaviour of multi-agent learning in many player games has been shown to display complex dynamics outside of restrictive examples such as network zero-sum games. In addition, it has been shown that convergent behaviour is less likely to occur as the number of players increase. To make progress in resolving this problem, we study Q-Learning dynamics and determine a sufficient condition for the dynamics to converge to a unique equilibrium in any network game. We find that this condition depends on the nature of pairwise interactions and on the network structure, but is explicitly independent of the total number of agents in the game. We evaluate this result on a number of representative network games and show that, under suitable network conditions, stable learning dynamics can be achieved with an arbitrary number of agents.
Discovering How Agents Learn Using Few Data
Jul 13, 2023


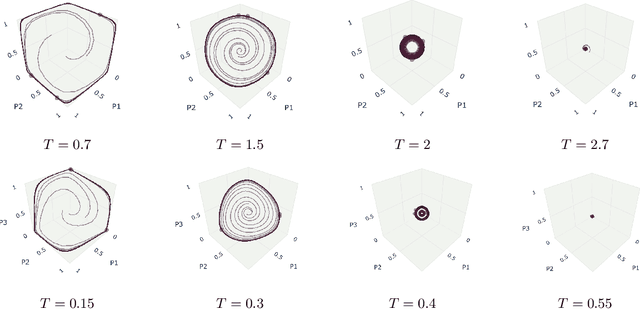
Decentralized learning algorithms are an essential tool for designing multi-agent systems, as they enable agents to autonomously learn from their experience and past interactions. In this work, we propose a theoretical and algorithmic framework for real-time identification of the learning dynamics that govern agent behavior using a short burst of a single system trajectory. Our method identifies agent dynamics through polynomial regression, where we compensate for limited data by incorporating side-information constraints that capture fundamental assumptions or expectations about agent behavior. These constraints are enforced computationally using sum-of-squares optimization, leading to a hierarchy of increasingly better approximations of the true agent dynamics. Extensive experiments demonstrated that our approach, using only 5 samples from a short run of a single trajectory, accurately recovers the true dynamics across various benchmarks, including equilibrium selection and prediction of chaotic systems up to 10 Lyapunov times. These findings suggest that our approach has significant potential to support effective policy and decision-making in strategic multi-agent systems.
Multiplicative Updates for Online Convex Optimization over Symmetric Cones
Jul 06, 2023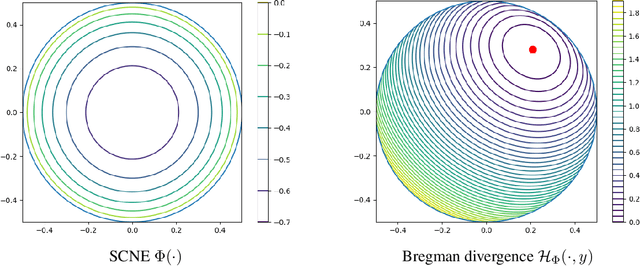

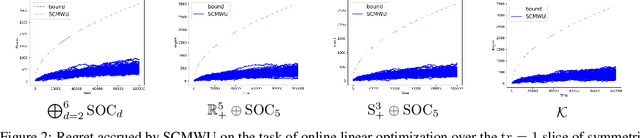

We study online convex optimization where the possible actions are trace-one elements in a symmetric cone, generalizing the extensively-studied experts setup and its quantum counterpart. Symmetric cones provide a unifying framework for some of the most important optimization models, including linear, second-order cone, and semidefinite optimization. Using tools from the field of Euclidean Jordan Algebras, we introduce the Symmetric-Cone Multiplicative Weights Update (SCMWU), a projection-free algorithm for online optimization over the trace-one slice of an arbitrary symmetric cone. We show that SCMWU is equivalent to Follow-the-Regularized-Leader and Online Mirror Descent with symmetric-cone negative entropy as regularizer. Using this structural result we show that SCMWU is a no-regret algorithm, and verify our theoretical results with extensive experiments. Our results unify and generalize the analysis for the Multiplicative Weights Update method over the probability simplex and the Matrix Multiplicative Weights Update method over the set of density matrices.
Chaos persists in large-scale multi-agent learning despite adaptive learning rates
Jun 01, 2023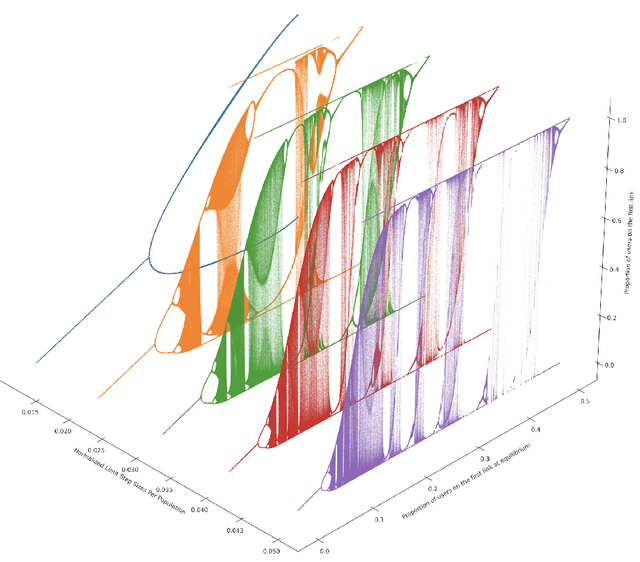
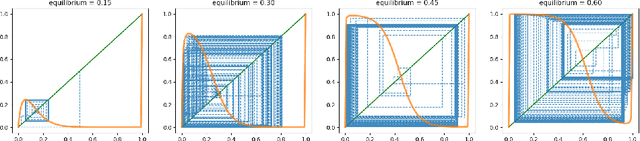
Multi-agent learning is intrinsically harder, more unstable and unpredictable than single agent optimization. For this reason, numerous specialized heuristics and techniques have been designed towards the goal of achieving convergence to equilibria in self-play. One such celebrated approach is the use of dynamically adaptive learning rates. Although such techniques are known to allow for improved convergence guarantees in small games, it has been much harder to analyze them in more relevant settings with large populations of agents. These settings are particularly hard as recent work has established that learning with fixed rates will become chaotic given large enough populations.In this work, we show that chaos persists in large population congestion games despite using adaptive learning rates even for the ubiquitous Multiplicative Weight Updates algorithm, even in the presence of only two strategies. At a technical level, due to the non-autonomous nature of the system, our approach goes beyond conventional period-three techniques Li-Yorke by studying fundamental properties of the dynamics including invariant sets, volume expansion and turbulent sets. We complement our theoretical insights with experiments showcasing that slight variations to system parameters lead to a wide variety of unpredictable behaviors.
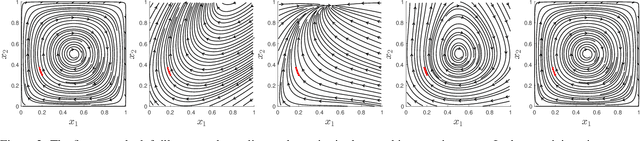
Asymptotic Convergence and Performance of Multi-Agent Q-Learning Dynamics
Jan 23, 2023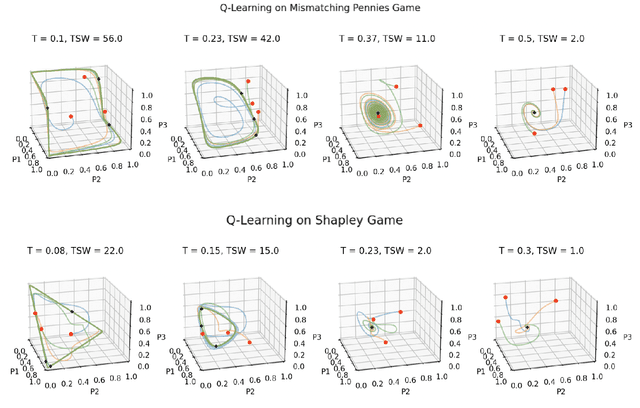
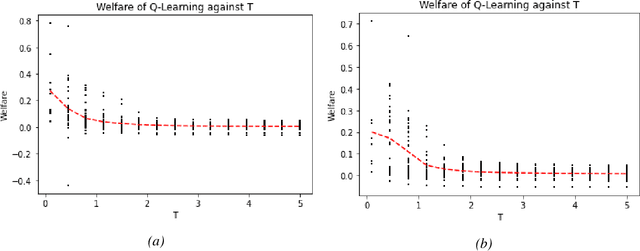
Achieving convergence of multiple learning agents in general $N$-player games is imperative for the development of safe and reliable machine learning (ML) algorithms and their application to autonomous systems. Yet it is known that, outside the bounds of simple two-player games, convergence cannot be taken for granted. To make progress in resolving this problem, we study the dynamics of smooth Q-Learning, a popular reinforcement learning algorithm which quantifies the tendency for learning agents to explore their state space or exploit their payoffs. We show a sufficient condition on the rate of exploration such that the Q-Learning dynamics is guaranteed to converge to a unique equilibrium in any game. We connect this result to games for which Q-Learning is known to converge with arbitrary exploration rates, including weighted Potential games and weighted zero sum polymatrix games. Finally, we examine the performance of the Q-Learning dynamic as measured by the Time Averaged Social Welfare, and comparing this with the Social Welfare achieved by the equilibrium. We provide a sufficient condition whereby the Q-Learning dynamic will outperform the equilibrium even if the dynamics do not converge.