 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiacomo Camposampiero
Limits of Transformer Language Models on Learning Algorithmic Compositions
Feb 13, 2024
We analyze the capabilities of Transformer language models on learning discrete algorithms. To this end, we introduce two new tasks demanding the composition of several discrete sub-tasks. On both training LLaMA models from scratch and prompting on GPT-4 and Gemini we measure learning compositions of learned primitives. We observe that the compositional capabilities of state-of-the-art Transformer language models are very limited and sample-wise scale worse than relearning all sub-tasks for a new algorithmic composition. We also present a theorem in complexity theory, showing that gradient descent on memorizing feedforward models can be exponentially data inefficient.
Visual Abstraction and Reasoning through Language
Mar 07, 2023
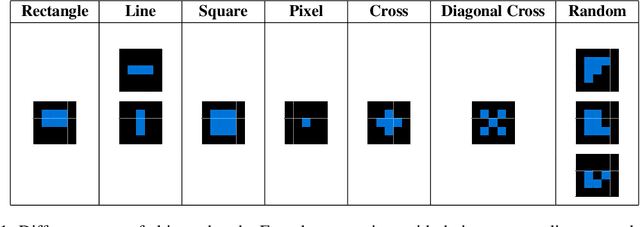

While Artificial Intelligence (AI) models have achieved human or even superhuman performance in narrowly defined applications, they still struggle to show signs of broader and more flexible intelligence. The Abstraction and Reasoning Corpus (ARC), introduced by Fran\c{c}ois Chollet, aims to assess how close AI systems are to human-like cognitive abilities. Most current approaches rely on carefully handcrafted domain-specific languages (DSLs), which are used to brute-force solutions to the tasks present in ARC. In this work, we propose a general framework for solving ARC based on natural language descriptions of the tasks. While not yet beating state-of-the-art DSL models on ARC, we demonstrate the immense potential of our approach hinted at by the ability to solve previously unsolved tasks.
The effectiveness of factorization and similarity blending
Sep 16, 2022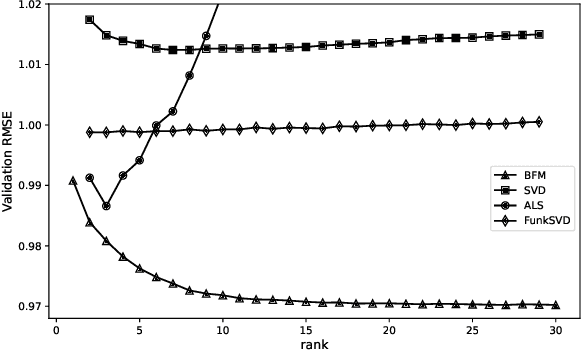
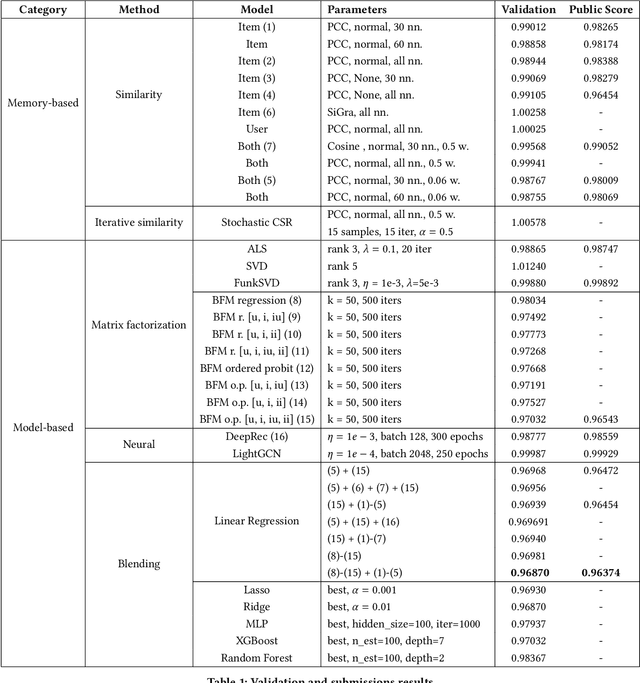
Collaborative Filtering (CF) is a widely used technique which allows to leverage past users' preferences data to identify behavioural patterns and exploit them to predict custom recommendations. In this work, we illustrate our review of different CF techniques in the context of the Computational Intelligence Lab (CIL) CF project at ETH Z\"urich. After evaluating the performances of the individual models, we show that blending factorization-based and similarity-based approaches can lead to a significant error decrease (-9.4%) on the best-performing stand-alone model. Moreover, we propose a novel stochastic extension of a similarity model, SCSR, which consistently reduce the asymptotic complexity of the original algorithm.