 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiuseppe Casalicchio
Position Paper: Rethinking Empirical Research in Machine Learning: Addressing Epistemic and Methodological Challenges of Experimentation
May 03, 2024
We warn against a common but incomplete understanding of empirical research in machine learning (ML) that leads to non-replicable results, makes findings unreliable, and threatens to undermine progress in the field. To overcome this alarming situation, we call for more awareness of the plurality of ways of gaining knowledge experimentally but also of some epistemic limitations. In particular, we argue most current empirical ML research is fashioned as confirmatory research while it should rather be considered exploratory.
mlr3summary: Concise and interpretable summaries for machine learning models
Apr 25, 2024This work introduces a novel R package for concise, informative summaries of machine learning models. We take inspiration from the summary function for (generalized) linear models in R, but extend it in several directions: First, our summary function is model-agnostic and provides a unified summary output also for non-parametric machine learning models; Second, the summary output is more extensive and customizable -- it comprises information on the dataset, model performance, model complexity, model's estimated feature importances, feature effects, and fairness metrics; Third, models are evaluated based on resampling strategies for unbiased estimates of model performances, feature importances, etc. Overall, the clear, structured output should help to enhance and expedite the model selection process, making it a helpful tool for practitioners and researchers alike.
A Guide to Feature Importance Methods for Scientific Inference
Apr 19, 2024While machine learning (ML) models are increasingly used due to their high predictive power, their use in understanding the data-generating process (DGP) is limited. Understanding the DGP requires insights into feature-target associations, which many ML models cannot directly provide, due to their opaque internal mechanisms. Feature importance (FI) methods provide useful insights into the DGP under certain conditions. Since the results of different FI methods have different interpretations, selecting the correct FI method for a concrete use case is crucial and still requires expert knowledge. This paper serves as a comprehensive guide to help understand the different interpretations of FI methods. Through an extensive review of FI methods and providing new proofs regarding their interpretation, we facilitate a thorough understanding of these methods and formulate concrete recommendations for scientific inference. We conclude by discussing options for FI uncertainty estimation and point to directions for future research aiming at full statistical inference from black-box ML models.
Effector: A Python package for regional explanations
Apr 03, 2024



Global feature effect methods explain a model outputting one plot per feature. The plot shows the average effect of the feature on the output, like the effect of age on the annual income. However, average effects may be misleading when derived from local effects that are heterogeneous, i.e., they significantly deviate from the average. To decrease the heterogeneity, regional effects provide multiple plots per feature, each representing the average effect within a specific subspace. For interpretability, subspaces are defined as hyperrectangles defined by a chain of logical rules, like age's effect on annual income separately for males and females and different levels of professional experience. We introduce Effector, a Python library dedicated to regional feature effects. Effector implements well-established global effect methods, assesses the heterogeneity of each method and, based on that, provides regional effects. Effector automatically detects subspaces where regional effects have reduced heterogeneity. All global and regional effect methods share a common API, facilitating comparisons between them. Moreover, the library's interface is extensible so new methods can be easily added and benchmarked. The library has been thoroughly tested, ships with many tutorials (https://xai-effector.github.io/) and is available under an open-source license at PyPi (https://pypi.org/project/effector/) and Github (https://github.com/givasile/effector).
Explaining Bayesian Optimization by Shapley Values Facilitates Human-AI Collaboration
Mar 08, 2024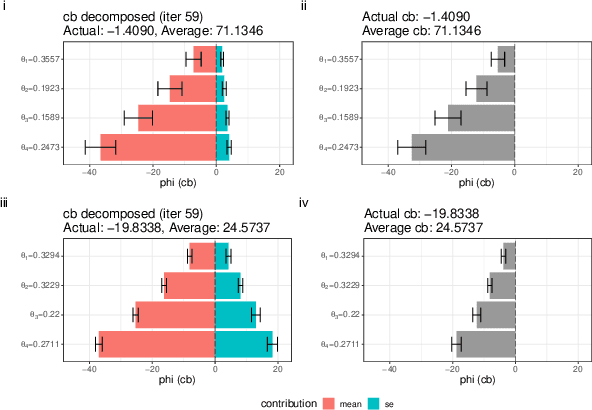

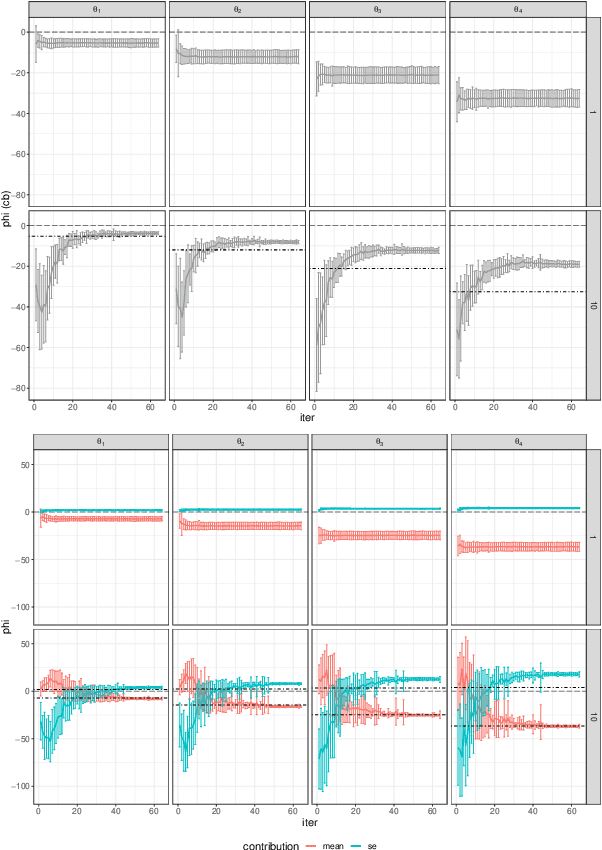
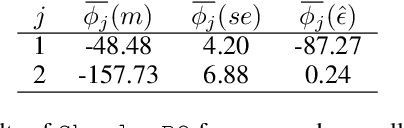
Bayesian optimization (BO) with Gaussian processes (GP) has become an indispensable algorithm for black box optimization problems. Not without a dash of irony, BO is often considered a black box itself, lacking ways to provide reasons as to why certain parameters are proposed to be evaluated. This is particularly relevant in human-in-the-loop applications of BO, such as in robotics. We address this issue by proposing ShapleyBO, a framework for interpreting BO's proposals by game-theoretic Shapley values.They quantify each parameter's contribution to BO's acquisition function. Exploiting the linearity of Shapley values, we are further able to identify how strongly each parameter drives BO's exploration and exploitation for additive acquisition functions like the confidence bound. We also show that ShapleyBO can disentangle the contributions to exploration into those that explore aleatoric and epistemic uncertainty. Moreover, our method gives rise to a ShapleyBO-assisted human machine interface (HMI), allowing users to interfere with BO in case proposals do not align with human reasoning. We demonstrate this HMI's benefits for the use case of personalizing wearable robotic devices (assistive back exosuits) by human-in-the-loop BO. Results suggest human-BO teams with access to ShapleyBO can achieve lower regret than teams without.
Position Paper: Bridging the Gap Between Machine Learning and Sensitivity Analysis
Dec 20, 2023We argue that interpretations of machine learning (ML) models or the model-building process can bee seen as a form of sensitivity analysis (SA), a general methodology used to explain complex systems in many fields such as environmental modeling, engineering, or economics. We address both researchers and practitioners, calling attention to the benefits of a unified SA-based view of explanations in ML and the necessity to fully credit related work. We bridge the gap between both fields by formally describing how (a) the ML process is a system suitable for SA, (b) how existing ML interpretation methods relate to this perspective, and (c) how other SA techniques could be applied to ML.
Leveraging Model-based Trees as Interpretable Surrogate Models for Model Distillation
Oct 04, 2023Surrogate models play a crucial role in retrospectively interpreting complex and powerful black box machine learning models via model distillation. This paper focuses on using model-based trees as surrogate models which partition the feature space into interpretable regions via decision rules. Within each region, interpretable models based on additive main effects are used to approximate the behavior of the black box model, striking for an optimal balance between interpretability and performance. Four model-based tree algorithms, namely SLIM, GUIDE, MOB, and CTree, are compared regarding their ability to generate such surrogate models. We investigate fidelity, interpretability, stability, and the algorithms' capability to capture interaction effects through appropriate splits. Based on our comprehensive analyses, we finally provide an overview of user-specific recommendations.
fmeffects: An R Package for Forward Marginal Effects
Oct 03, 2023



Forward marginal effects (FMEs) have recently been introduced as a versatile and effective model-agnostic interpretation method. They provide comprehensible and actionable model explanations in the form of: If we change $x$ by an amount $h$, what is the change in predicted outcome $\widehat{y}$? We present the R package fmeffects, the first software implementation of FMEs. The relevant theoretical background, package functionality and handling, as well as the software design and options for future extensions are discussed in this paper.
Decomposing Global Feature Effects Based on Feature Interactions
Jun 01, 2023



Global feature effect methods, such as partial dependence plots, provide an intelligible visualization of the expected marginal feature effect. However, such global feature effect methods can be misleading, as they do not represent local feature effects of single observations well when feature interactions are present. We formally introduce generalized additive decomposition of global effects (GADGET), which is a new framework based on recursive partitioning to find interpretable regions in the feature space such that the interaction-related heterogeneity of local feature effects is minimized. We provide a mathematical foundation of the framework and show that it is applicable to the most popular methods to visualize marginal feature effects, namely partial dependence, accumulated local effects, and Shapley additive explanations (SHAP) dependence. Furthermore, we introduce a new permutation-based interaction test to detect significant feature interactions that is applicable to any feature effect method that fits into our proposed framework. We empirically evaluate the theoretical characteristics of the proposed methods based on various feature effect methods in different experimental settings. Moreover, we apply our introduced methodology to two real-world examples to showcase their usefulness.
Interpretable Regional Descriptors: Hyperbox-Based Local Explanations
May 04, 2023



This work introduces interpretable regional descriptors, or IRDs, for local, model-agnostic interpretations. IRDs are hyperboxes that describe how an observation's feature values can be changed without affecting its prediction. They justify a prediction by providing a set of "even if" arguments (semi-factual explanations), and they indicate which features affect a prediction and whether pointwise biases or implausibilities exist. A concrete use case shows that this is valuable for both machine learning modelers and persons subject to a decision. We formalize the search for IRDs as an optimization problem and introduce a unifying framework for computing IRDs that covers desiderata, initialization techniques, and a post-processing method. We show how existing hyperbox methods can be adapted to fit into this unified framework. A benchmark study compares the methods based on several quality measures and identifies two strategies to improve IRDs.