 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiuseppe Paolo
Unlocking the Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention
Feb 19, 2024
Transformer-based architectures achieved breakthrough performance in natural language processing and computer vision, yet they remain inferior to simpler linear baselines in multivariate long-term forecasting. To better understand this phenomenon, we start by studying a toy linear forecasting problem for which we show that transformers are incapable of converging to their true solution despite their high expressive power. We further identify the attention of transformers as being responsible for this low generalization capacity. Building upon this insight, we propose a shallow lightweight transformer model that successfully escapes bad local minima when optimized with sharpness-aware optimization. We empirically demonstrate that this result extends to all commonly used real-world multivariate time series datasets. In particular, SAMformer surpasses the current state-of-the-art model TSMixer by 14.33% on average, while having ~4 times fewer parameters. The code is available at https://github.com/romilbert/samformer.
A call for embodied AI
Feb 06, 2024We propose Embodied AI as the next fundamental step in the pursuit of Artificial General Intelligence, juxtaposing it against current AI advancements, particularly Large Language Models. We traverse the evolution of the embodiment concept across diverse fields - philosophy, psychology, neuroscience, and robotics - to highlight how EAI distinguishes itself from the classical paradigm of static learning. By broadening the scope of Embodied AI, we introduce a theoretical framework based on cognitive architectures, emphasizing perception, action, memory, and learning as essential components of an embodied agent. This framework is aligned with Friston's active inference principle, offering a comprehensive approach to EAI development. Despite the progress made in the field of AI, substantial challenges, such as the formulation of a novel AI learning theory and the innovation of advanced hardware, persist. Our discussion lays down a foundational guideline for future Embodied AI research. Highlighting the importance of creating Embodied AI agents capable of seamless communication, collaboration, and coexistence with humans and other intelligent entities within real-world environments, we aim to steer the AI community towards addressing the multifaceted challenges and seizing the opportunities that lie ahead in the quest for AGI.
A Multi-step Loss Function for Robust Learning of the Dynamics in Model-based Reinforcement Learning
Feb 05, 2024In model-based reinforcement learning, most algorithms rely on simulating trajectories from one-step models of the dynamics learned on data. A critical challenge of this approach is the compounding of one-step prediction errors as the length of the trajectory grows. In this paper we tackle this issue by using a multi-step objective to train one-step models. Our objective is a weighted sum of the mean squared error (MSE) loss at various future horizons. We find that this new loss is particularly useful when the data is noisy (additive Gaussian noise in the observations), which is often the case in real-life environments. To support the multi-step loss, first we study its properties in two tractable cases: i) uni-dimensional linear system, and ii) two-parameter non-linear system. Second, we show in a variety of tasks (environments or datasets) that the models learned with this loss achieve a significant improvement in terms of the averaged R2-score on future prediction horizons. Finally, in the pure batch reinforcement learning setting, we demonstrate that one-step models serve as strong baselines when dynamics are deterministic, while multi-step models would be more advantageous in the presence of noise, highlighting the potential of our approach in real-world applications.
Multi-timestep models for Model-based Reinforcement Learning
Oct 11, 2023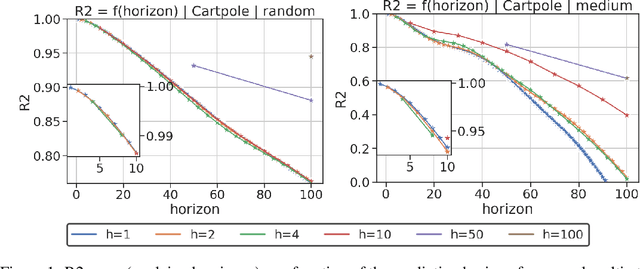

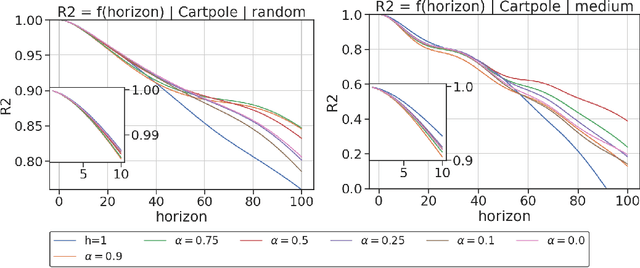
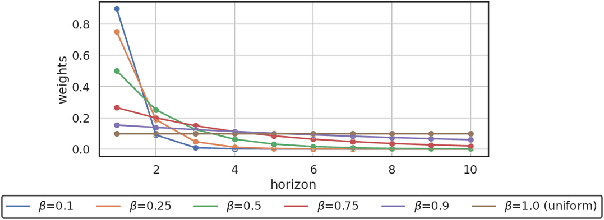
In model-based reinforcement learning (MBRL), most algorithms rely on simulating trajectories from one-step dynamics models learned on data. A critical challenge of this approach is the compounding of one-step prediction errors as length of the trajectory grows. In this paper we tackle this issue by using a multi-timestep objective to train one-step models. Our objective is a weighted sum of a loss function (e.g., negative log-likelihood) at various future horizons. We explore and test a range of weights profiles. We find that exponentially decaying weights lead to models that significantly improve the long-horizon R2 score. This improvement is particularly noticeable when the models were evaluated on noisy data. Finally, using a soft actor-critic (SAC) agent in pure batch reinforcement learning (RL) and iterated batch RL scenarios, we found that our multi-timestep models outperform or match standard one-step models. This was especially evident in a noisy variant of the considered environment, highlighting the potential of our approach in real-world applications.
Guided Safe Shooting: model based reinforcement learning with safety constraints
Jun 20, 2022
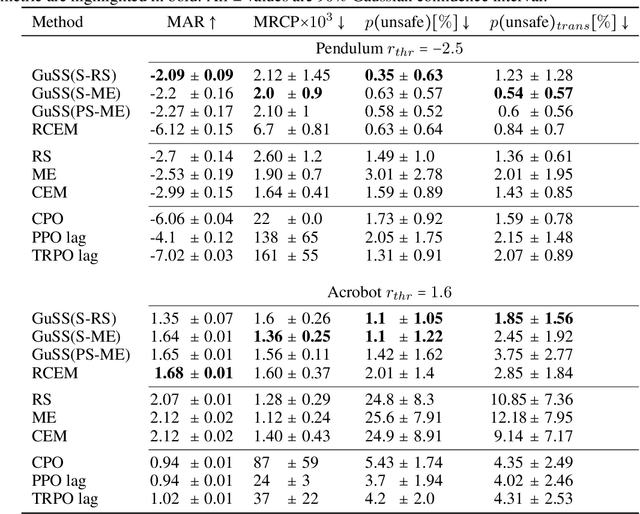

In the last decade, reinforcement learning successfully solved complex control tasks and decision-making problems, like the Go board game. Yet, there are few success stories when it comes to deploying those algorithms to real-world scenarios. One of the reasons is the lack of guarantees when dealing with and avoiding unsafe states, a fundamental requirement in critical control engineering systems. In this paper, we introduce Guided Safe Shooting (GuSS), a model-based RL approach that can learn to control systems with minimal violations of the safety constraints. The model is learned on the data collected during the operation of the system in an iterated batch fashion, and is then used to plan for the best action to perform at each time step. We propose three different safe planners, one based on a simple random shooting strategy and two based on MAP-Elites, a more advanced divergent-search algorithm. Experiments show that these planners help the learning agent avoid unsafe situations while maximally exploring the state space, a necessary aspect when learning an accurate model of the system. Furthermore, compared to model-free approaches, learning a model allows GuSS reducing the number of interactions with the real-system while still reaching high rewards, a fundamental requirement when handling engineering systems.
Learning in Sparse Rewards settings through Quality-Diversity algorithms
Mar 02, 2022

In the Reinforcement Learning (RL) framework, the learning is guided through a reward signal. This means that in situations of sparse rewards the agent has to focus on exploration, in order to discover which action, or set of actions leads to the reward. RL agents usually struggle with this. Exploration is the focus of Quality-Diversity (QD) methods. In this thesis, we approach the problem of sparse rewards with these algorithms, and in particular with Novelty Search (NS). This is a method that only focuses on the diversity of the possible policies behaviors. The first part of the thesis focuses on learning a representation of the space in which the diversity of the policies is evaluated. In this regard, we propose the TAXONS algorithm, a method that learns a low-dimensional representation of the search space through an AutoEncoder. While effective, TAXONS still requires information on when to capture the observation used to learn said space. For this, we study multiple ways, and in particular the signature transform, to encode information about the whole trajectory of observations. The thesis continues with the introduction of the SERENE algorithm, a method that can efficiently focus on the interesting parts of the search space. This method separates the exploration of the search space from the exploitation of the reward through a two-alternating-steps approach. The exploration is performed through NS. Any discovered reward is then locally exploited through emitters. The third and final contribution combines TAXONS and SERENE into a single approach: STAX. Throughout this thesis, we introduce methods that lower the amount of prior information needed in sparse rewards settings. These contributions are a promising step towards the development of methods that can autonomously explore and find high-performance policies in a variety of sparse rewards settings.
Discovering and Exploiting Sparse Rewards in a Learned Behavior Space
Nov 02, 2021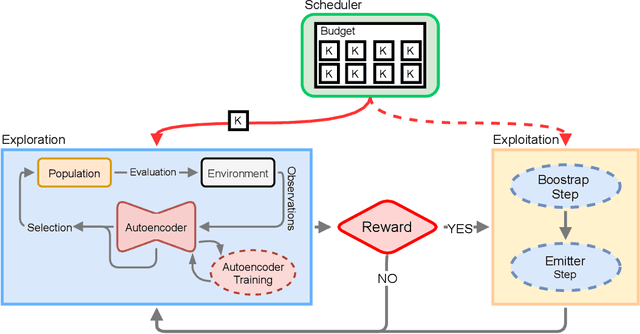
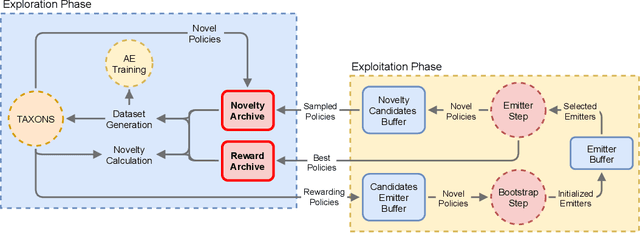
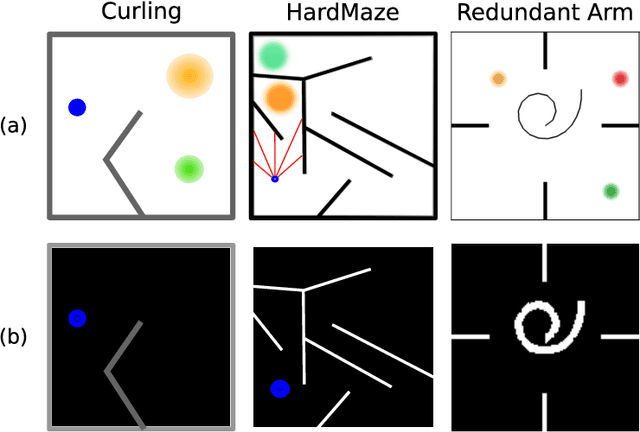
Learning optimal policies in sparse rewards settings is difficult as the learning agent has little to no feedback on the quality of its actions. In these situations, a good strategy is to focus on exploration, hopefully leading to the discovery of a reward signal to improve on. A learning algorithm capable of dealing with this kind of settings has to be able to (1) explore possible agent behaviors and (2) exploit any possible discovered reward. Efficient exploration algorithms have been proposed that require to define a behavior space, that associates to an agent its resulting behavior in a space that is known to be worth exploring. The need to define this space is a limitation of these algorithms. In this work, we introduce STAX, an algorithm designed to learn a behavior space on-the-fly and to explore it while efficiently optimizing any reward discovered. It does so by separating the exploration and learning of the behavior space from the exploitation of the reward through an alternating two-steps process. In the first step, STAX builds a repertoire of diverse policies while learning a low-dimensional representation of the high-dimensional observations generated during the policies evaluation. In the exploitation step, emitters are used to optimize the performance of the discovered rewarding solutions. Experiments conducted on three different sparse reward environments show that STAX performs comparably to existing baselines while requiring much less prior information about the task as it autonomously builds the behavior space.
Sparse Reward Exploration via Novelty Search and Emitters
Feb 05, 2021
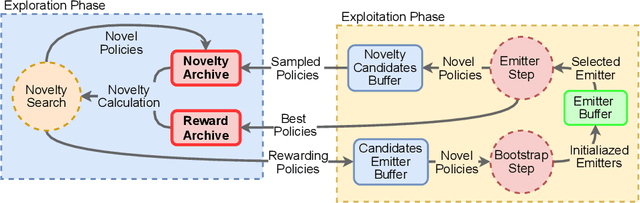
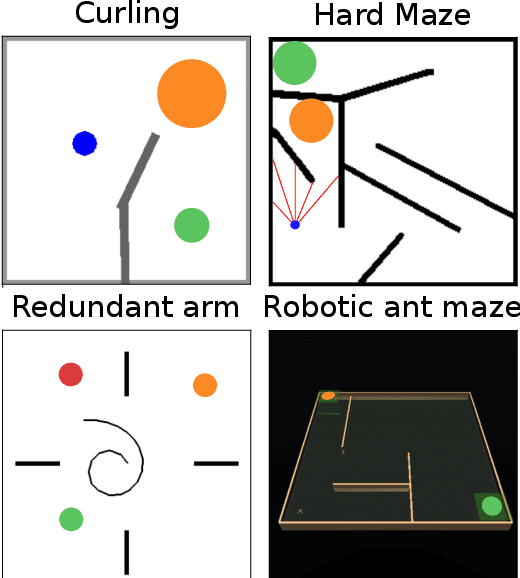
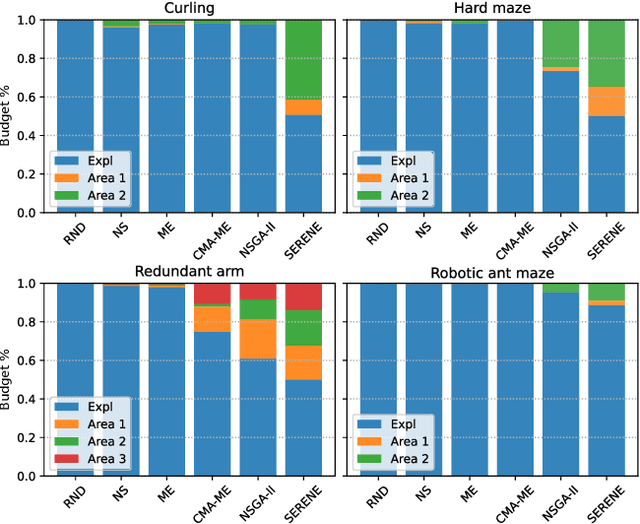
Reward-based optimization algorithms require both exploration, to find rewards, and exploitation, to maximize performance. The need for efficient exploration is even more significant in sparse reward settings, in which performance feedback is given sparingly, thus rendering it unsuitable for guiding the search process. In this work, we introduce the SparsE Reward Exploration via Novelty and Emitters (SERENE) algorithm, capable of efficiently exploring a search space, as well as optimizing rewards found in potentially disparate areas. Contrary to existing emitters-based approaches, SERENE separates the search space exploration and reward exploitation into two alternating processes. The first process performs exploration through Novelty Search, a divergent search algorithm. The second one exploits discovered reward areas through emitters, i.e. local instances of population-based optimization algorithms. A meta-scheduler allocates a global computational budget by alternating between the two processes, ensuring the discovery and efficient exploitation of disjoint reward areas. SERENE returns both a collection of diverse solutions covering the search space and a collection of high-performing solutions for each distinct reward area. We evaluate SERENE on various sparse reward environments and show it compares favorably to existing baselines.
Novelty Search makes Evolvability Inevitable
May 13, 2020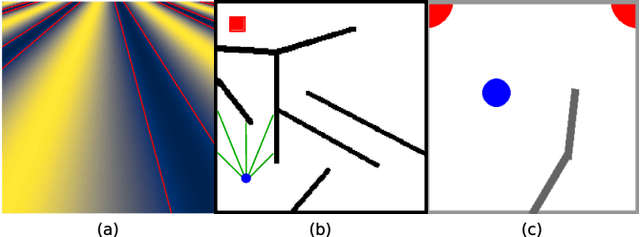
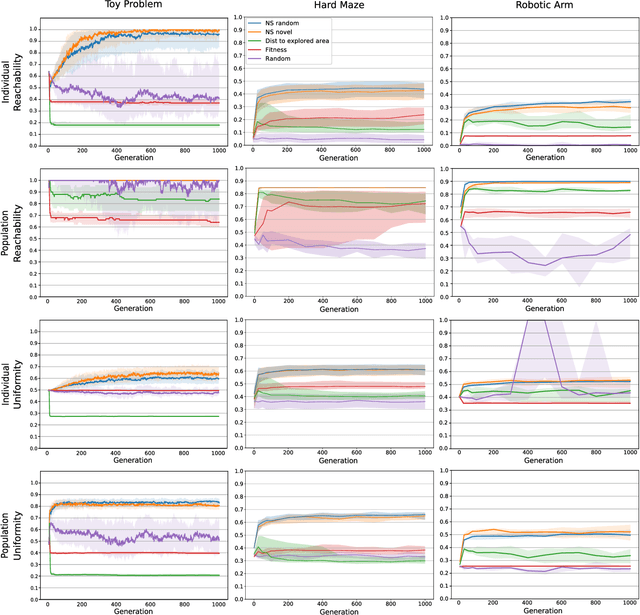
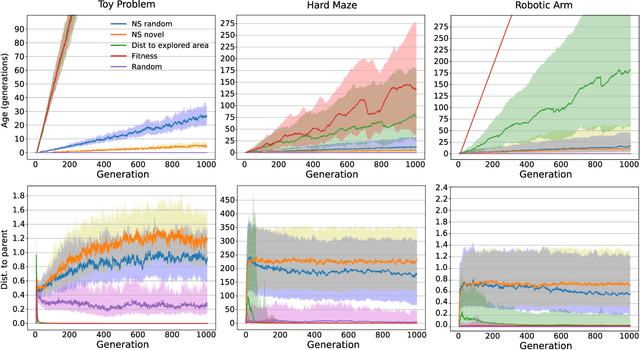
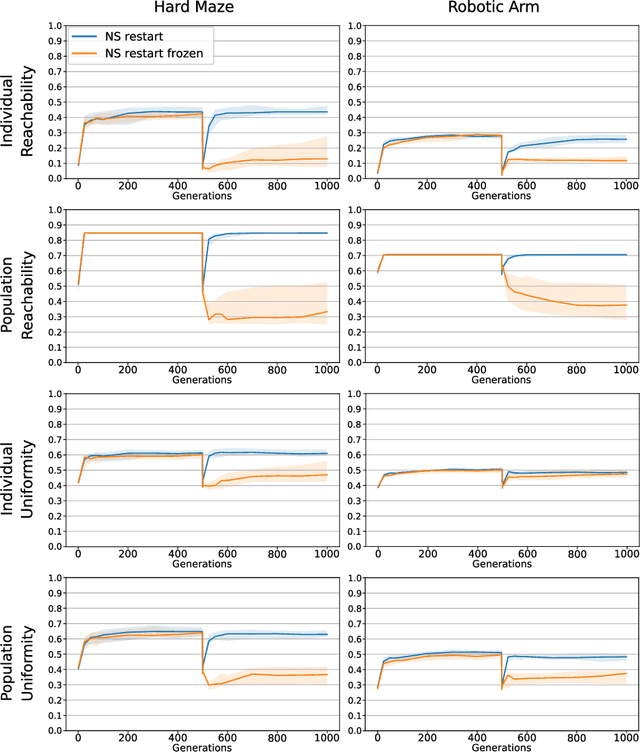
Evolvability is an important feature that impacts the ability of evolutionary processes to find interesting novel solutions and to deal with changing conditions of the problem to solve. The estimation of evolvability is not straightforward and is generally too expensive to be directly used as selective pressure in the evolutionary process. Indirectly promoting evolvability as a side effect of other easier and faster to compute selection pressures would thus be advantageous. In an unbounded behavior space, it has already been shown that evolvable individuals naturally appear and tend to be selected as they are more likely to invade empty behavior niches. Evolvability is thus a natural byproduct of the search in this context. However, practical agents and environments often impose limits on the reach-able behavior space. How do these boundaries impact evolvability? In this context, can evolvability still be promoted without explicitly rewarding it? We show that Novelty Search implicitly creates a pressure for high evolvability even in bounded behavior spaces, and explore the reasons for such a behavior. More precisely we show that, throughout the search, the dynamic evaluation of novelty rewards individuals which are very mobile in the behavior space, which in turn promotes evolvability.
Unsupervised Learning and Exploration of Reachable Outcome Space
Sep 13, 2019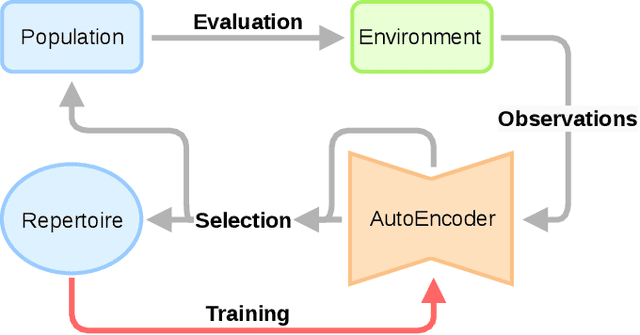
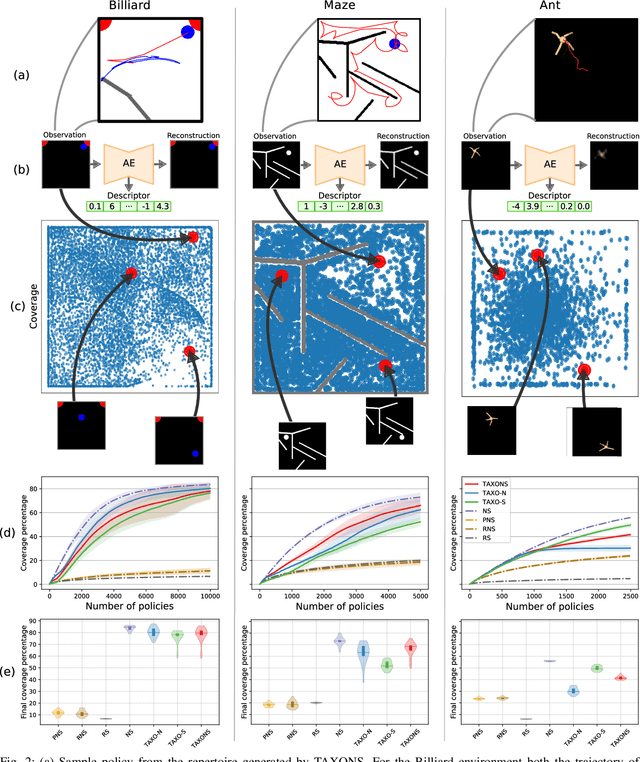
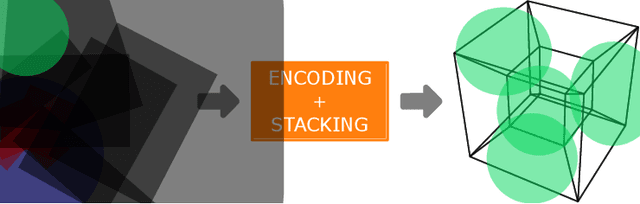
Performing Reinforcement Learning in sparse rewards settings, with very little prior knowledge, is a challenging problem since there is no signal to properly guide the learning process. In such situations, a good search strategy is fundamental. At the same time, not having to adapt the algorithm to every single problem is very desirable. Here we introduce TAXONS, a Task Agnostic eXploration of Outcome spaces through Novelty and Surprise algorithm. Based on a population-based divergent-search approach, it learns a set of diverse policies directly from high-dimensional observations, without any task-specific information. TAXONS builds a repertoire of policies while training an autoencoder on the high-dimensional observation of the final state of the system to build a low-dimensional outcome space. The learned outcome space, combined with the reconstruction error, is used to drive the search for new policies. Results show that TAXONS can find a diverse set of controllers, covering a good part of the ground-truth outcome space, while having no information about such space.