 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuanxing Lu
ManiGaussian: Dynamic Gaussian Splatting for Multi-task Robotic Manipulation
Mar 13, 2024
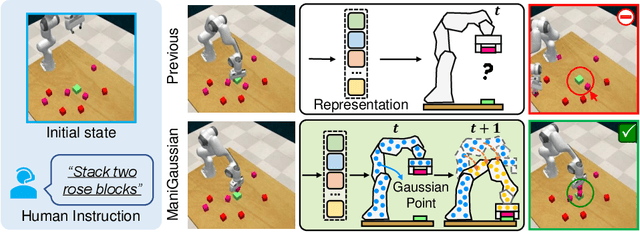
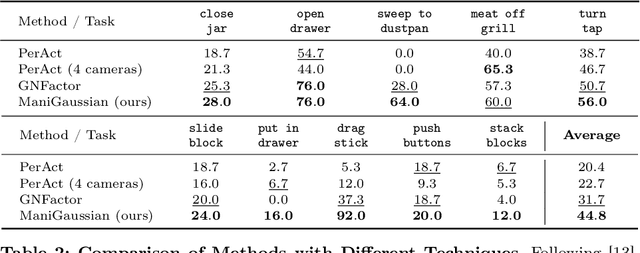
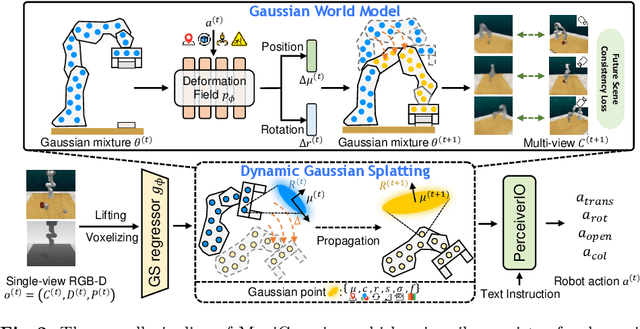

Performing language-conditioned robotic manipulation tasks in unstructured environments is highly demanded for general intelligent robots. Conventional robotic manipulation methods usually learn semantic representation of the observation for action prediction, which ignores the scene-level spatiotemporal dynamics for human goal completion. In this paper, we propose a dynamic Gaussian Splatting method named ManiGaussian for multi-task robotic manipulation, which mines scene dynamics via future scene reconstruction. Specifically, we first formulate the dynamic Gaussian Splatting framework that infers the semantics propagation in the Gaussian embedding space, where the semantic representation is leveraged to predict the optimal robot action. Then, we build a Gaussian world model to parameterize the distribution in our dynamic Gaussian Splatting framework, which provides informative supervision in the interactive environment via future scene reconstruction. We evaluate our ManiGaussian on 10 RLBench tasks with 166 variations, and the results demonstrate our framework can outperform the state-of-the-art methods by 13.1\% in average success rate.
ThinkBot: Embodied Instruction Following with Thought Chain Reasoning
Dec 14, 2023Embodied Instruction Following (EIF) requires agents to complete human instruction by interacting objects in complicated surrounding environments. Conventional methods directly consider the sparse human instruction to generate action plans for agents, which usually fail to achieve human goals because of the instruction incoherence in action descriptions. On the contrary, we propose ThinkBot that reasons the thought chain in human instruction to recover the missing action descriptions, so that the agent can successfully complete human goals by following the coherent instruction. Specifically, we first design an instruction completer based on large language models to recover the missing actions with interacted objects between consecutive human instruction, where the perceived surrounding environments and the completed sub-goals are considered for instruction completion. Based on the partially observed scene semantic maps, we present an object localizer to infer the position of interacted objects for agents to achieve complex human goals. Extensive experiments in the simulated environment show that our ThinkBot outperforms the state-of-the-art EIF methods by a sizable margin in both success rate and execution efficiency.
Semi-Supervised Subspace Clustering via Tensor Low-Rank Representation
May 21, 2022



In this letter, we propose a novel semi-supervised subspace clustering method, which is able to simultaneously augment the initial supervisory information and construct a discriminative affinity matrix. By representing the limited amount of supervisory information as a pairwise constraint matrix, we observe that the ideal affinity matrix for clustering shares the same low-rank structure as the ideal pairwise constraint matrix. Thus, we stack the two matrices into a 3-D tensor, where a global low-rank constraint is imposed to promote the affinity matrix construction and augment the initial pairwise constraints synchronously. Besides, we use the local geometry structure of input samples to complement the global low-rank prior to achieve better affinity matrix learning. The proposed model is formulated as a Laplacian graph regularized convex low-rank tensor representation problem, which is further solved with an alternative iterative algorithm. In addition, we propose to refine the affinity matrix with the augmented pairwise constraints. Comprehensive experimental results on six commonly-used benchmark datasets demonstrate the superiority of our method over state-of-the-art methods. The code is publicly available at https://github.com/GuanxingLu/Subspace-Clustering.