 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGui-Bo Ye
Robust recovery of complex exponential signals from random Gaussian projections via low rank Hankel matrix reconstruction
Mar 10, 2015
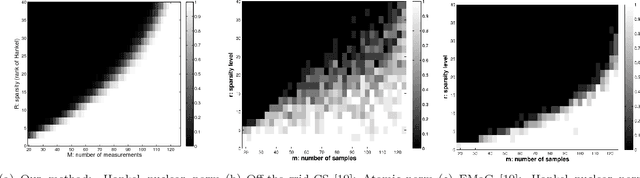
This paper explores robust recovery of a superposition of $R$ distinct complex exponential functions from a few random Gaussian projections. We assume that the signal of interest is of $2N-1$ dimensional and $R<<2N-1$. This framework covers a large class of signals arising from real applications in biology, automation, imaging science, etc. To reconstruct such a signal, our algorithm is to seek a low-rank Hankel matrix of the signal by minimizing its nuclear norm subject to the consistency on the sampled data. Our theoretical results show that a robust recovery is possible as long as the number of projections exceeds $O(R\ln^2N)$. No incoherence or separation condition is required in our proof. Our method can be applied to spectral compressed sensing where the signal of interest is a superposition of $R$ complex sinusoids. Compared to existing results, our result here does not need any separation condition on the frequencies, while achieving better or comparable bounds on the number of measurements. Furthermore, our method provides theoretical guidance on how many samples are required in the state-of-the-art non-uniform sampling in NMR spectroscopy. The performance of our algorithm is further demonstrated by numerical experiments.
Efficient Latent Variable Graphical Model Selection via Split Bregman Method
Oct 13, 2011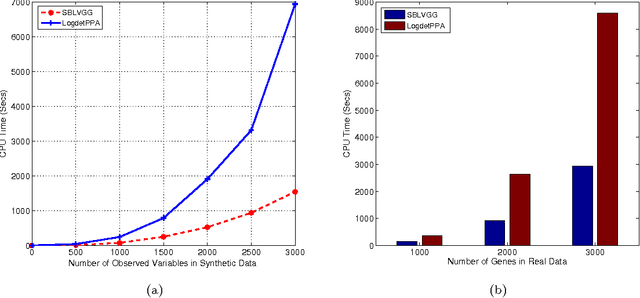
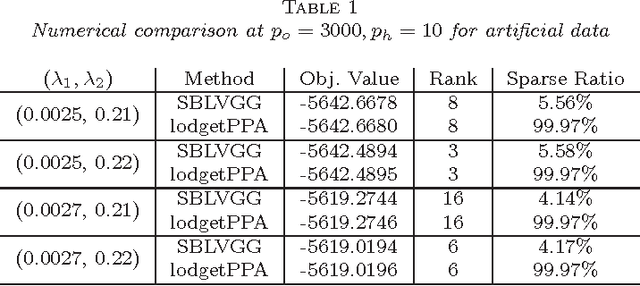
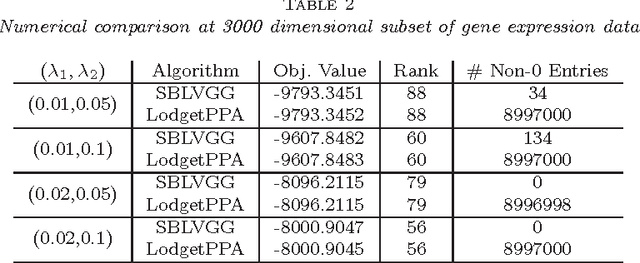
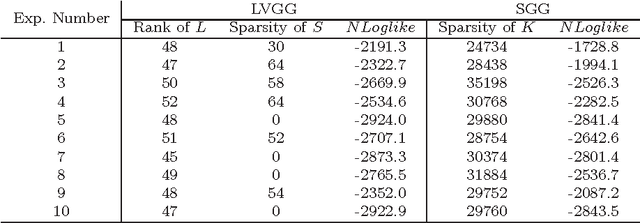
We consider the problem of covariance matrix estimation in the presence of latent variables. Under suitable conditions, it is possible to learn the marginal covariance matrix of the observed variables via a tractable convex program, where the concentration matrix of the observed variables is decomposed into a sparse matrix (representing the graphical structure of the observed variables) and a low rank matrix (representing the marginalization effect of latent variables). We present an efficient first-order method based on split Bregman to solve the convex problem. The algorithm is guaranteed to converge under mild conditions. We show that our algorithm is significantly faster than the state-of-the-art algorithm on both artificial and real-world data. Applying the algorithm to a gene expression data involving thousands of genes, we show that most of the correlation between observed variables can be explained by only a few dozen latent factors.
Split Bregman Method for Sparse Inverse Covariance Estimation with Matrix Iteration Acceleration
Dec 23, 2010
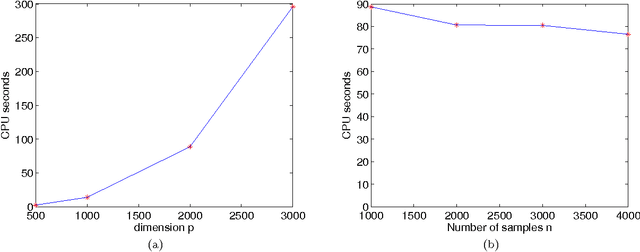
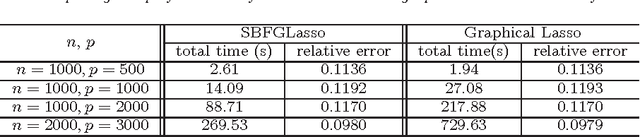

We consider the problem of estimating the inverse covariance matrix by maximizing the likelihood function with a penalty added to encourage the sparsity of the resulting matrix. We propose a new approach based on the split Bregman method to solve the regularized maximum likelihood estimation problem. We show that our method is significantly faster than the widely used graphical lasso method, which is based on blockwise coordinate descent, on both artificial and real-world data. More importantly, different from the graphical lasso, the split Bregman based method is much more general, and can be applied to a class of regularization terms other than the $\ell_1$ norm
Learning sparse gradients for variable selection and dimension reduction
Jul 01, 2010
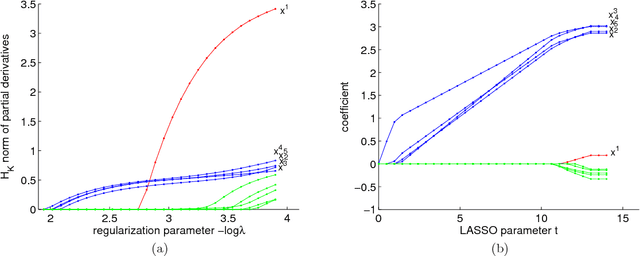
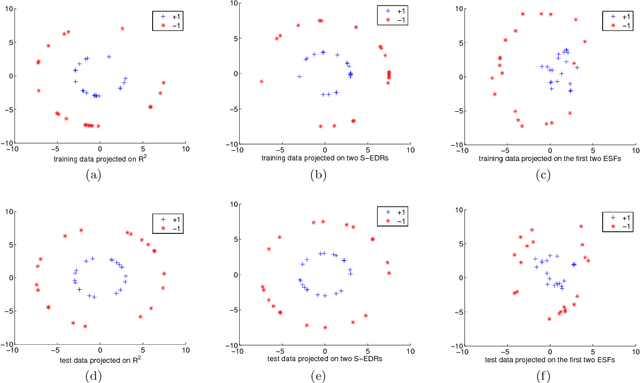

Variable selection and dimension reduction are two commonly adopted approaches for high-dimensional data analysis, but have traditionally been treated separately. Here we propose an integrated approach, called sparse gradient learning (SGL), for variable selection and dimension reduction via learning the gradients of the prediction function directly from samples. By imposing a sparsity constraint on the gradients, variable selection is achieved by selecting variables corresponding to non-zero partial derivatives, and effective dimensions are extracted based on the eigenvectors of the derived sparse empirical gradient covariance matrix. An error analysis is given for the convergence of the estimated gradients to the true ones in both the Euclidean and the manifold setting. We also develop an efficient forward-backward splitting algorithm to solve the SGL problem, making the framework practically scalable for medium or large datasets. The utility of SGL for variable selection and feature extraction is explicitly given and illustrated on artificial data as well as real-world examples. The main advantages of our method include variable selection for both linear and nonlinear predictions, effective dimension reduction with sparse loadings, and an efficient algorithm for large p, small n problems.
Split Bregman method for large scale fused Lasso
Jun 26, 2010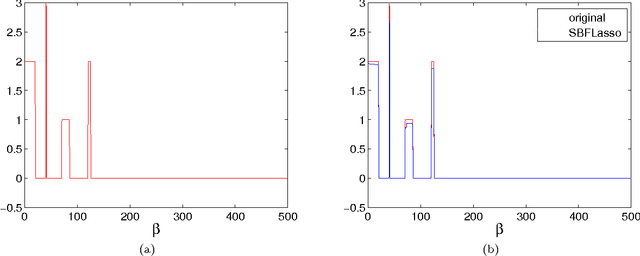
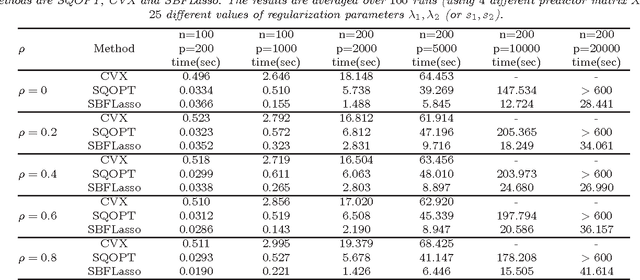
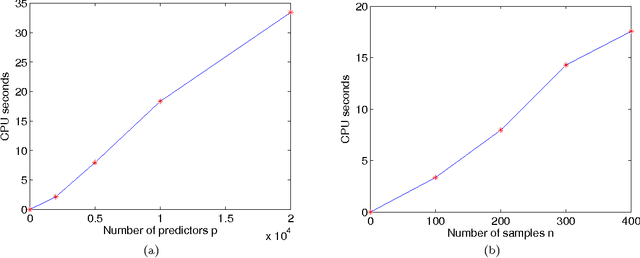
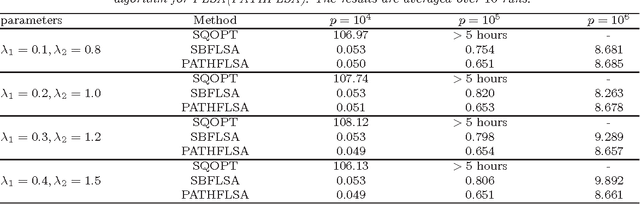
rdering of regression or classification coefficients occurs in many real-world applications. Fused Lasso exploits this ordering by explicitly regularizing the differences between neighboring coefficients through an $\ell_1$ norm regularizer. However, due to nonseparability and nonsmoothness of the regularization term, solving the fused Lasso problem is computationally demanding. Existing solvers can only deal with problems of small or medium size, or a special case of the fused Lasso problem in which the predictor matrix is identity matrix. In this paper, we propose an iterative algorithm based on split Bregman method to solve a class of large-scale fused Lasso problems, including a generalized fused Lasso and a fused Lasso support vector classifier. We derive our algorithm using augmented Lagrangian method and prove its convergence properties. The performance of our method is tested on both artificial data and real-world applications including proteomic data from mass spectrometry and genomic data from array CGH. We demonstrate that our method is many times faster than the existing solvers, and show that it is especially efficient for large p, small n problems.