 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuoping Qiu
PSAvatar: A Point-based Morphable Shape Model for Real-Time Head Avatar Animation with 3D Gaussian Splatting
Jan 30, 2024
Despite much progress, achieving real-time high-fidelity head avatar animation is still difficult and existing methods have to trade-off between speed and quality. 3DMM based methods often fail to model non-facial structures such as eyeglasses and hairstyles, while neural implicit models suffer from deformation inflexibility and rendering inefficiency. Although 3D Gaussian has been demonstrated to possess promising capability for geometry representation and radiance field reconstruction, applying 3D Gaussian in head avatar creation remains a major challenge since it is difficult for 3D Gaussian to model the head shape variations caused by changing poses and expressions. In this paper, we introduce PSAvatar, a novel framework for animatable head avatar creation that utilizes discrete geometric primitive to create a parametric morphable shape model and employs 3D Gaussian for fine detail representation and high fidelity rendering. The parametric morphable shape model is a Point-based Morphable Shape Model (PMSM) which uses points instead of meshes for 3D representation to achieve enhanced representation flexibility. The PMSM first converts the FLAME mesh to points by sampling on the surfaces as well as off the meshes to enable the reconstruction of not only surface-like structures but also complex geometries such as eyeglasses and hairstyles. By aligning these points with the head shape in an analysis-by-synthesis manner, the PMSM makes it possible to utilize 3D Gaussian for fine detail representation and appearance modeling, thus enabling the creation of high-fidelity avatars. We show that PSAvatar can reconstruct high-fidelity head avatars of a variety of subjects and the avatars can be animated in real-time ($\ge$ 25 fps at a resolution of 512 $\times$ 512 ).
3D Reconstruction and New View Synthesis of Indoor Environments based on a Dual Neural Radiance Field
Jan 26, 2024Simultaneously achieving 3D reconstruction and new view synthesis for indoor environments has widespread applications but is technically very challenging. State-of-the-art methods based on implicit neural functions can achieve excellent 3D reconstruction results, but their performances on new view synthesis can be unsatisfactory. The exciting development of neural radiance field (NeRF) has revolutionized new view synthesis, however, NeRF-based models can fail to reconstruct clean geometric surfaces. We have developed a dual neural radiance field (Du-NeRF) to simultaneously achieve high-quality geometry reconstruction and view rendering. Du-NeRF contains two geometric fields, one derived from the SDF field to facilitate geometric reconstruction and the other derived from the density field to boost new view synthesis. One of the innovative features of Du-NeRF is that it decouples a view-independent component from the density field and uses it as a label to supervise the learning process of the SDF field. This reduces shape-radiance ambiguity and enables geometry and color to benefit from each other during the learning process. Extensive experiments demonstrate that Du-NeRF can significantly improve the performance of novel view synthesis and 3D reconstruction for indoor environments and it is particularly effective in constructing areas containing fine geometries that do not obey multi-view color consistency.
P2I-NET: Mapping Camera Pose to Image via Adversarial Learning for New View Synthesis in Real Indoor Environments
Sep 27, 2023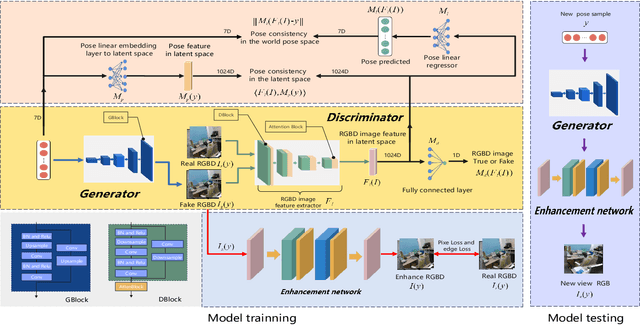
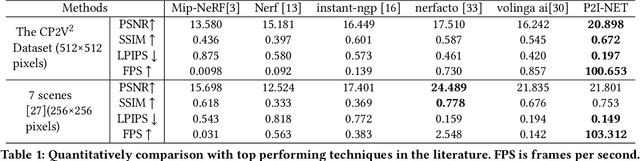
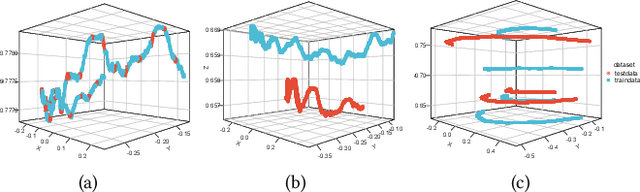

Given a new $6DoF$ camera pose in an indoor environment, we study the challenging problem of predicting the view from that pose based on a set of reference RGBD views. Existing explicit or implicit 3D geometry construction methods are computationally expensive while those based on learning have predominantly focused on isolated views of object categories with regular geometric structure. Differing from the traditional \textit{render-inpaint} approach to new view synthesis in the real indoor environment, we propose a conditional generative adversarial neural network (P2I-NET) to directly predict the new view from the given pose. P2I-NET learns the conditional distribution of the images of the environment for establishing the correspondence between the camera pose and its view of the environment, and achieves this through a number of innovative designs in its architecture and training lost function. Two auxiliary discriminator constraints are introduced for enforcing the consistency between the pose of the generated image and that of the corresponding real world image in both the latent feature space and the real world pose space. Additionally a deep convolutional neural network (CNN) is introduced to further reinforce this consistency in the pixel space. We have performed extensive new view synthesis experiments on real indoor datasets. Results show that P2I-NET has superior performance against a number of NeRF based strong baseline models. In particular, we show that P2I-NET is 40 to 100 times faster than these competitor techniques while synthesising similar quality images. Furthermore, we contribute a new publicly available indoor environment dataset containing 22 high resolution RGBD videos where each frame also has accurate camera pose parameters.
Collaborative Auto-encoding for Blind Image Quality Assessment
May 24, 2023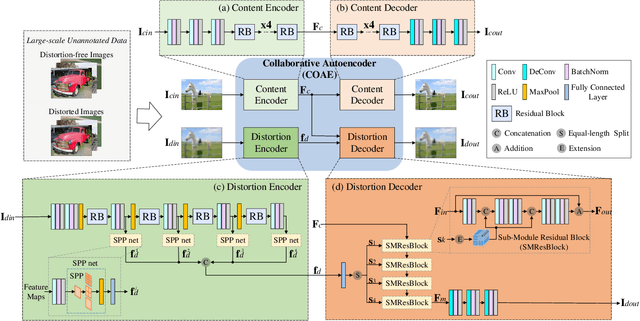
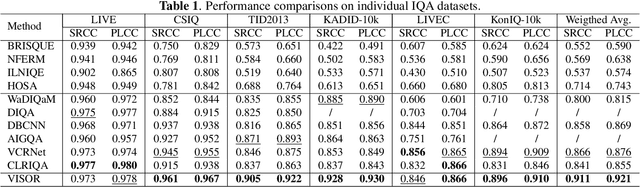
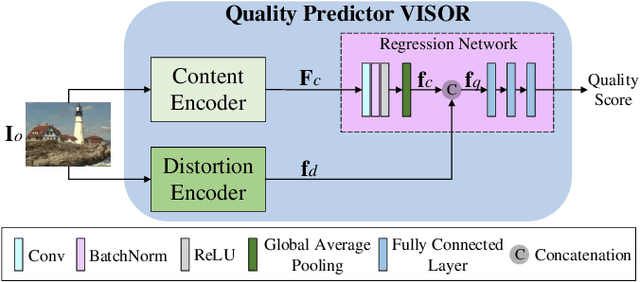
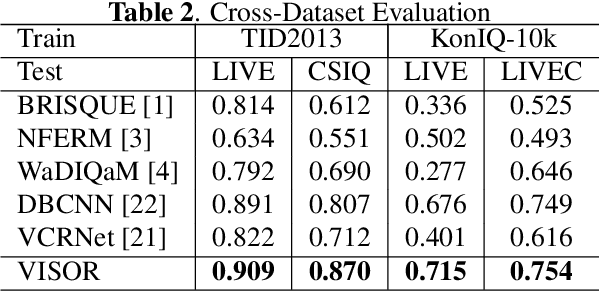
Blind image quality assessment (BIQA) is a challenging problem with important real-world applications. Recent efforts attempting to exploit powerful representations by deep neural networks (DNN) are hindered by the lack of subjectively annotated data. This paper presents a novel BIQA method which overcomes this fundamental obstacle. Specifically, we design a pair of collaborative autoencoders (COAE) consisting of a content autoencoder (CAE) and a distortion autoencoder (DAE) that work together to extract content and distortion representations, which are shown to be highly descriptive of image quality. While the CAE follows a standard codec procedure, we introduce the CAE-encoded feature as an extra input to the DAE's decoder for reconstructing distorted images, thus effectively forcing DAE's encoder to extract distortion representations. The self-supervised learning framework allows the COAE including two feature extractors to be trained by almost unlimited amount of data, thus leaving limited samples with annotations to finetune a BIQA model. We will show that the proposed BIQA method achieves state-of-the-art performance and has superior generalization capability over other learning based models. The codes are available at: https://github.com/Macro-Zhou/NRIQA-VISOR/.
Aesthetically Relevant Image Captioning
Nov 25, 2022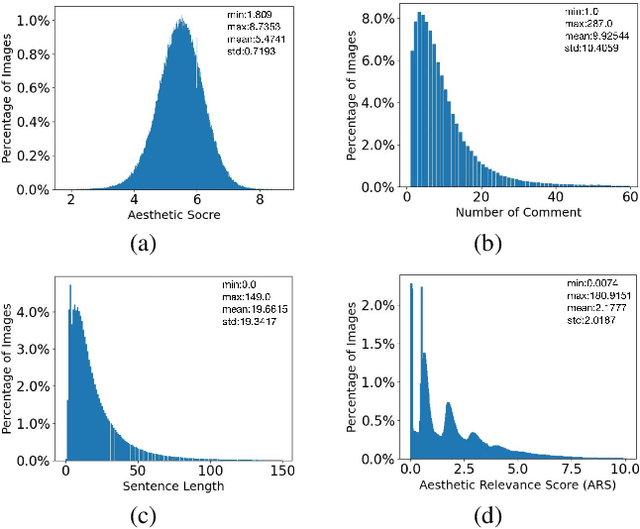

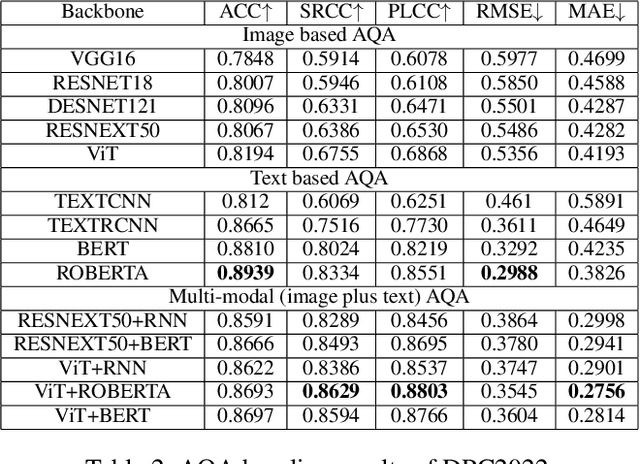

Image aesthetic quality assessment (AQA) aims to assign numerical aesthetic ratings to images whilst image aesthetic captioning (IAC) aims to generate textual descriptions of the aesthetic aspects of images. In this paper, we study image AQA and IAC together and present a new IAC method termed Aesthetically Relevant Image Captioning (ARIC). Based on the observation that most textual comments of an image are about objects and their interactions rather than aspects of aesthetics, we first introduce the concept of Aesthetic Relevance Score (ARS) of a sentence and have developed a model to automatically label a sentence with its ARS. We then use the ARS to design the ARIC model which includes an ARS weighted IAC loss function and an ARS based diverse aesthetic caption selector (DACS). We present extensive experimental results to show the soundness of the ARS concept and the effectiveness of the ARIC model by demonstrating that texts with higher ARS's can predict the aesthetic ratings more accurately and that the new ARIC model can generate more accurate, aesthetically more relevant and more diverse image captions. Furthermore, a large new research database containing 510K images with over 5 million comments and 350K aesthetic scores, and code for implementing ARIC are available at https://github.com/PengZai/ARIC.
ConvTransSeg: A Multi-resolution Convolution-Transformer Network for Medical Image Segmentation
Oct 13, 2022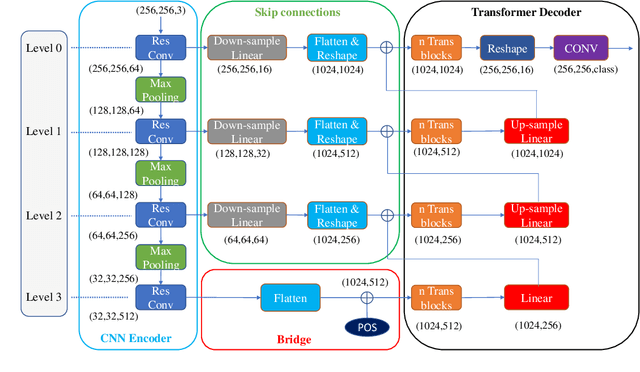
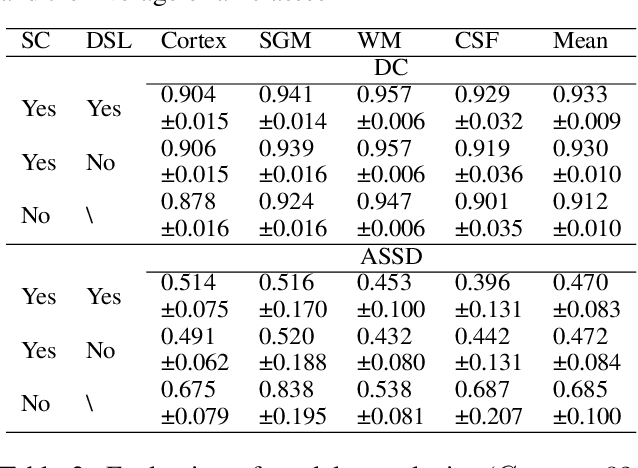
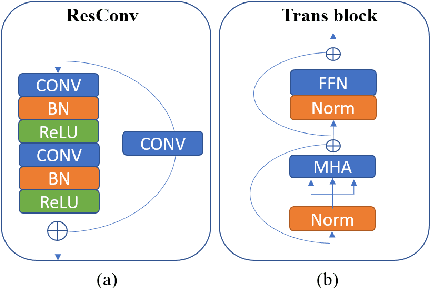
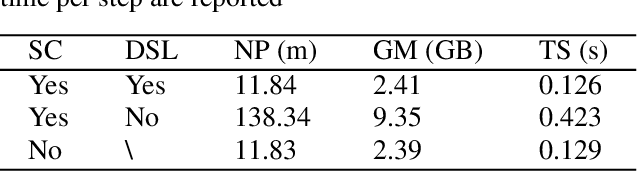
Convolutional neural networks (CNNs) achieved the state-of-the-art performance in medical image segmentation due to their ability to extract highly complex feature representations. However, it is argued in recent studies that traditional CNNs lack the intelligence to capture long-term dependencies of different image regions. Following the success of applying Transformer models on natural language processing tasks, the medical image segmentation field has also witnessed growing interest in utilizing Transformers, due to their ability to capture long-range contextual information. However, unlike CNNs, Transformers lack the ability to learn local feature representations. Thus, to fully utilize the advantages of both CNNs and Transformers, we propose a hybrid encoder-decoder segmentation model (ConvTransSeg). It consists of a multi-layer CNN as the encoder for feature learning and the corresponding multi-level Transformer as the decoder for segmentation prediction. The encoder and decoder are interconnected in a multi-resolution manner. We compared our method with many other state-of-the-art hybrid CNN and Transformer segmentation models on binary and multiple class image segmentation tasks using several public medical image datasets, including skin lesion, polyp, cell and brain tissue. The experimental results show that our method achieves overall the best performance in terms of Dice coefficient and average symmetric surface distance measures with low model complexity and memory consumption. In contrast to most Transformer-based methods that we compared, our method does not require the use of pre-trained models to achieve similar or better performance. The code is freely available for research purposes on Github: (the link will be added upon acceptance).
Improving Image Clustering through Sample Ranking and Its Application to remote--sensing images
Sep 26, 2022


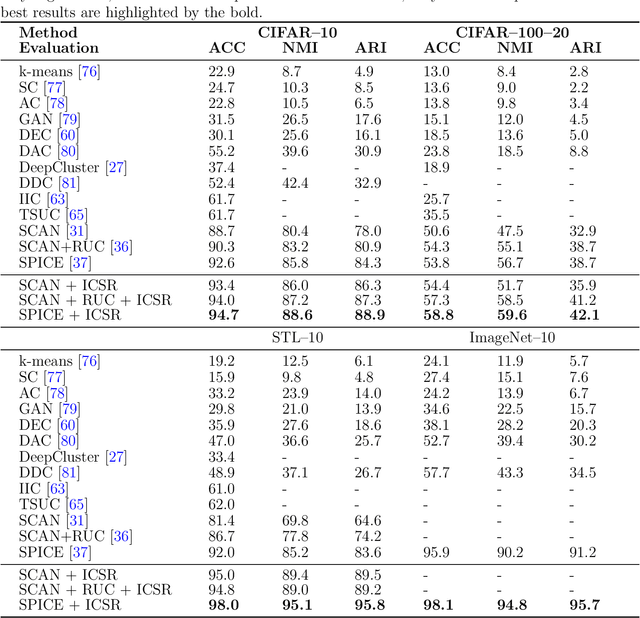
Image clustering is a very useful technique that is widely applied to various areas, including remote sensing. Recently, visual representations by self-supervised learning have greatly improved the performance of image clustering. To further improve the well-trained clustering models, this paper proposes a novel method by first ranking samples within each cluster based on the confidence in their belonging to the current cluster and then using the ranking to formulate a weighted cross-entropy loss to train the model. For ranking the samples, we developed a method for computing the likelihood of samples belonging to the current clusters based on whether they are situated in densely populated neighborhoods, while for training the model, we give a strategy for weighting the ranked samples. We present extensive experimental results that demonstrate that the new technique can be used to improve the State-of-the-Art image clustering models, achieving accuracy performance gains ranging from $2.1\%$ to $15.9\%$. Performing our method on a variety of datasets from remote sensing, we show that our method can be effectively applied to remote--sensing images.
* 39
Restoration of User Videos Shared on Social Media
Aug 26, 2022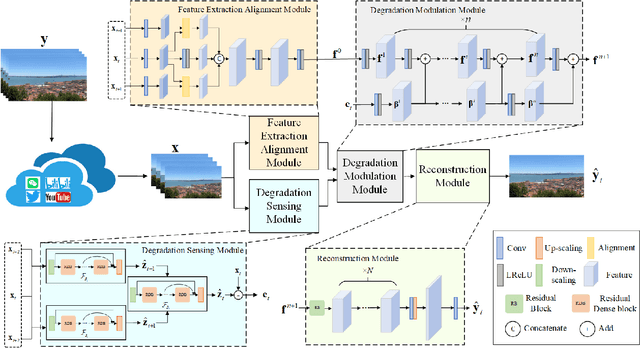



User videos shared on social media platforms usually suffer from degradations caused by unknown proprietary processing procedures, which means that their visual quality is poorer than that of the originals. This paper presents a new general video restoration framework for the restoration of user videos shared on social media platforms. In contrast to most deep learning-based video restoration methods that perform end-to-end mapping, where feature extraction is mostly treated as a black box, in the sense that what role a feature plays is often unknown, our new method, termed Video restOration through adapTive dEgradation Sensing (VOTES), introduces the concept of a degradation feature map (DFM) to explicitly guide the video restoration process. Specifically, for each video frame, we first adaptively estimate its DFM to extract features representing the difficulty of restoring its different regions. We then feed the DFM to a convolutional neural network (CNN) to compute hierarchical degradation features to modulate an end-to-end video restoration backbone network, such that more attention is paid explicitly to potentially more difficult to restore areas, which in turn leads to enhanced restoration performance. We will explain the design rationale of the VOTES framework and present extensive experimental results to show that the new VOTES method outperforms various state-of-the-art techniques both quantitatively and qualitatively. In addition, we contribute a large scale real-world database of user videos shared on different social media platforms. Codes and datasets are available at https://github.com/luohongming/VOTES.git
On Designing Good Representation Learning Models
Aug 06, 2021
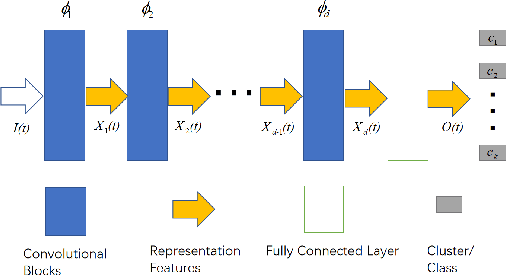
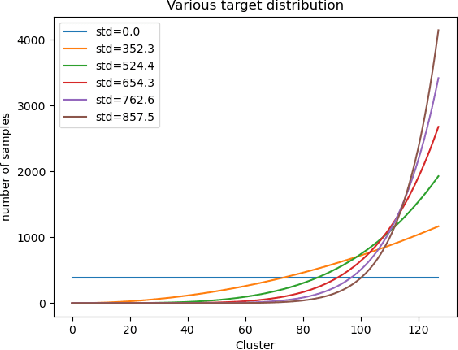
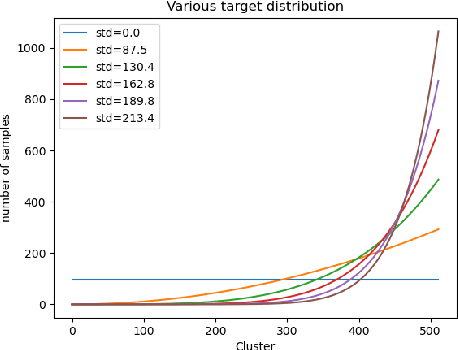
The goal of representation learning is different from the ultimate objective of machine learning such as decision making, it is therefore very difficult to establish clear and direct objectives for training representation learning models. It has been argued that a good representation should disentangle the underlying variation factors, yet how to translate this into training objectives remains unknown. This paper presents an attempt to establish direct training criterions and design principles for developing good representation learning models. We propose that a good representation learning model should be maximally expressive, i.e., capable of distinguishing the maximum number of input configurations. We formally define expressiveness and introduce the maximum expressiveness (MEXS) theorem of a general learning model. We propose to train a model by maximizing its expressiveness while at the same time incorporating general priors such as model smoothness. We present a conscience competitive learning algorithm which encourages the model to reach its MEXS whilst at the same time adheres to model smoothness prior. We also introduce a label consistent training (LCT) technique to boost model smoothness by encouraging it to assign consistent labels to similar samples. We present extensive experimental results to show that our method can indeed design representation learning models capable of developing representations that are as good as or better than state of the art. We also show that our technique is computationally efficient, robust against different parameter settings and can work effectively on a variety of datasets. Code available at https://github.com/qlilx/odgrlm.git
Lightness Modulated Deep Inverse Tone Mapping
Jul 16, 2021

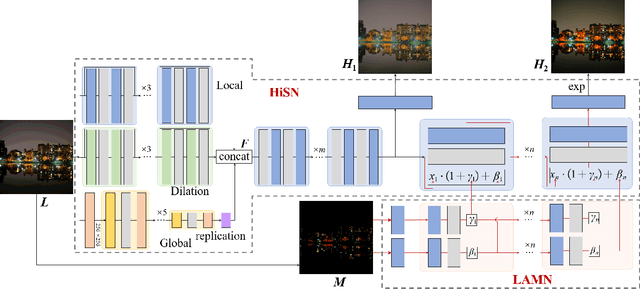

Single-image HDR reconstruction or inverse tone mapping (iTM) is a challenging task. In particular, recovering information in over-exposed regions is extremely difficult because details in such regions are almost completely lost. In this paper, we present a deep learning based iTM method that takes advantage of the feature extraction and mapping power of deep convolutional neural networks (CNNs) and uses a lightness prior to modulate the CNN to better exploit observations in the surrounding areas of the over-exposed regions to enhance the quality of HDR image reconstruction. Specifically, we introduce a Hierarchical Synthesis Network (HiSN) for inferring a HDR image from a LDR input and a Lightness Adpative Modulation Network (LAMN) to incorporate the the lightness prior knowledge in the inferring process. The HiSN hierarchically synthesizes the high-brightness component and the low-brightness component of the HDR image whilst the LAMN uses a lightness adaptive mask that separates detail-less saturated bright pixels from well-exposed lower light pixels to enable HiSN to better infer the missing information, particularly in the difficult over-exposed detail-less areas. We present experimental results to demonstrate the effectiveness of the new technique based on quantitative measures and visual comparisons. In addition, we present ablation studies of HiSN and visualization of the activation maps inside LAMN to help gain a deeper understanding of the internal working of the new iTM algorithm and explain why it can achieve much improved performance over state-of-the-art algorithms.