 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHai Nguyen
Symmetry-aware Reinforcement Learning for Robotic Assembly under Partial Observability with a Soft Wrist
Feb 28, 2024
This study tackles the representative yet challenging contact-rich peg-in-hole task of robotic assembly, using a soft wrist that can operate more safely and tolerate lower-frequency control signals than a rigid one. Previous studies often use a fully observable formulation, requiring external setups or estimators for the peg-to-hole pose. In contrast, we use a partially observable formulation and deep reinforcement learning from demonstrations to learn a memory-based agent that acts purely on haptic and proprioceptive signals. Moreover, previous works do not incorporate potential domain symmetry and thus must search for solutions in a bigger space. Instead, we propose to leverage the symmetry for sample efficiency by augmenting the training data and constructing auxiliary losses to force the agent to adhere to the symmetry. Results in simulation with five different symmetric peg shapes show that our proposed agent can be comparable to or even outperform a state-based agent. In particular, the sample efficiency also allows us to learn directly on the real robot within 3 hours.
On-Robot Bayesian Reinforcement Learning for POMDPs
Jul 22, 2023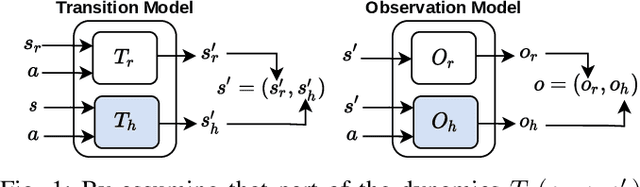

Robot learning is often difficult due to the expense of gathering data. The need for large amounts of data can, and should, be tackled with effective algorithms and leveraging expert information on robot dynamics. Bayesian reinforcement learning (BRL), thanks to its sample efficiency and ability to exploit prior knowledge, is uniquely positioned as such a solution method. Unfortunately, the application of BRL has been limited due to the difficulties of representing expert knowledge as well as solving the subsequent inference problem. This paper advances BRL for robotics by proposing a specialized framework for physical systems. In particular, we capture this knowledge in a factored representation, then demonstrate the posterior factorizes in a similar shape, and ultimately formalize the model in a Bayesian framework. We then introduce a sample-based online solution method, based on Monte-Carlo tree search and particle filtering, specialized to solve the resulting model. This approach can, for example, utilize typical low-level robot simulators and handle uncertainty over unknown dynamics of the environment. We empirically demonstrate its efficiency by performing on-robot learning in two human-robot interaction tasks with uncertainty about human behavior, achieving near-optimal performance after only a handful of real-world episodes. A video of learned policies is at https://youtu.be/H9xp60ngOes.
Learning from Pixels with Expert Observations
Jul 15, 2023



In reinforcement learning (RL), sparse rewards can present a significant challenge. Fortunately, expert actions can be utilized to overcome this issue. However, acquiring explicit expert actions can be costly, and expert observations are often more readily available. This paper presents a new approach that uses expert observations for learning in robot manipulation tasks with sparse rewards from pixel observations. Specifically, our technique involves using expert observations as intermediate visual goals for a goal-conditioned RL agent, enabling it to complete a task by successively reaching a series of goals. We demonstrate the efficacy of our method in five challenging block construction tasks in simulation and show that when combined with two state-of-the-art agents, our approach can significantly improve their performance while requiring 4-20 times fewer expert actions during training. Moreover, our method is also superior to a hierarchical baseline.
Leveraging Fully Observable Policies for Learning under Partial Observability
Nov 10, 2022
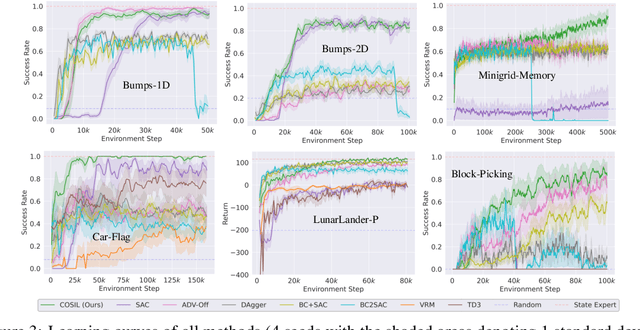
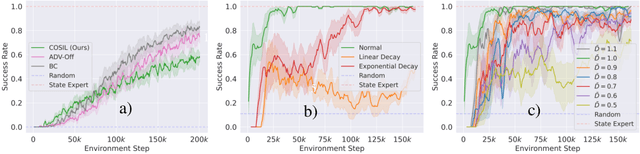
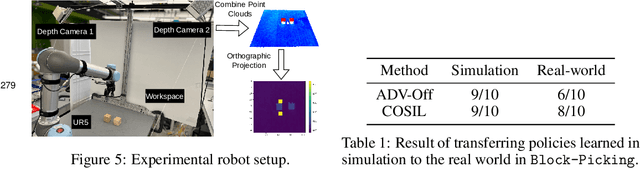
Reinforcement learning in partially observable domains is challenging due to the lack of observable state information. Thankfully, learning offline in a simulator with such state information is often possible. In particular, we propose a method for partially observable reinforcement learning that uses a fully observable policy (which we call a state expert) during offline training to improve online performance. Based on Soft Actor-Critic (SAC), our agent balances performing actions similar to the state expert and getting high returns under partial observability. Our approach can leverage the fully-observable policy for exploration and parts of the domain that are fully observable while still being able to learn under partial observability. On six robotics domains, our method outperforms pure imitation, pure reinforcement learning, the sequential or parallel combination of both types, and a recent state-of-the-art method in the same setting. A successful policy transfer to a physical robot in a manipulation task from pixels shows our approach's practicality in learning interesting policies under partial observability.
vieCap4H-VLSP 2021: Vietnamese Image Captioning for Healthcare Domain using Swin Transformer and Attention-based LSTM
Sep 03, 2022



This study presents our approach on the automatic Vietnamese image captioning for healthcare domain in text processing tasks of Vietnamese Language and Speech Processing (VLSP) Challenge 2021, as shown in Figure 1. In recent years, image captioning often employs a convolutional neural network-based architecture as an encoder and a long short-term memory (LSTM) as a decoder to generate sentences. These models perform remarkably well in different datasets. Our proposed model also has an encoder and a decoder, but we instead use a Swin Transformer in the encoder, and a LSTM combined with an attention module in the decoder. The study presents our training experiments and techniques used during the competition. Our model achieves a BLEU4 score of 0.293 on the vietCap4H dataset, and the score is ranked the 3$^{rd}$ place on the private leaderboard. Our code can be found at \url{https://git.io/JDdJm}.
Hierarchical Reinforcement Learning under Mixed Observability
Apr 05, 2022



The framework of mixed observable Markov decision processes (MOMDP) models many robotic domains in which some state variables are fully observable while others are not. In this work, we identify a significant subclass of MOMDPs defined by how actions influence the fully observable components of the state and how those, in turn, influence the partially observable components and the rewards. This unique property allows for a two-level hierarchical approach we call HIerarchical Reinforcement Learning under Mixed Observability (HILMO), which restricts partial observability to the top level while the bottom level remains fully observable, enabling higher learning efficiency. The top level produces desired goals to be reached by the bottom level until the task is solved. We further develop theoretical guarantees to show that our approach can achieve optimal and quasi-optimal behavior under mild assumptions. Empirical results on long-horizon continuous control tasks demonstrate the efficacy and efficiency of our approach in terms of improved success rate, sample efficiency, and wall-clock training time. We also deploy policies learned in simulation on a real robot.
BADDr: Bayes-Adaptive Deep Dropout RL for POMDPs
Feb 17, 2022



While reinforcement learning (RL) has made great advances in scalability, exploration and partial observability are still active research topics. In contrast, Bayesian RL (BRL) provides a principled answer to both state estimation and the exploration-exploitation trade-off, but struggles to scale. To tackle this challenge, BRL frameworks with various prior assumptions have been proposed, with varied success. This work presents a representation-agnostic formulation of BRL under partially observability, unifying the previous models under one theoretical umbrella. To demonstrate its practical significance we also propose a novel derivation, Bayes-Adaptive Deep Dropout rl (BADDr), based on dropout networks. Under this parameterization, in contrast to previous work, the belief over the state and dynamics is a more scalable inference problem. We choose actions through Monte-Carlo tree search and empirically show that our method is competitive with state-of-the-art BRL methods on small domains while being able to solve much larger ones.
Recurrent Off-policy Baselines for Memory-based Continuous Control
Oct 25, 2021



When the environment is partially observable (PO), a deep reinforcement learning (RL) agent must learn a suitable temporal representation of the entire history in addition to a strategy to control. This problem is not novel, and there have been model-free and model-based algorithms proposed for this problem. However, inspired by recent success in model-free image-based RL, we noticed the absence of a model-free baseline for history-based RL that (1) uses full history and (2) incorporates recent advances in off-policy continuous control. Therefore, we implement recurrent versions of DDPG, TD3, and SAC (RDPG, RTD3, and RSAC) in this work, evaluate them on short-term and long-term PO domains, and investigate key design choices. Our experiments show that RDPG and RTD3 can surprisingly fail on some domains and that RSAC is the most reliable, reaching near-optimal performance on nearly all domains. However, one task that requires systematic exploration still proved to be difficult, even for RSAC. These results show that model-free RL can learn good temporal representation using only reward signals; the primary difficulty seems to be computational cost and exploration. To facilitate future research, we have made our PyTorch implementation publicly available at https://github.com/zhihanyang2022/off-policy-continuous-control.
Fruit-CoV: An Efficient Vision-based Framework for Speedy Detection and Diagnosis of SARS-CoV-2 Infections Through Recorded Cough Sounds
Sep 06, 2021



SARS-CoV-2 is colloquially known as COVID-19 that had an initial outbreak in December 2019. The deadly virus has spread across the world, taking part in the global pandemic disease since March 2020. In addition, a recent variant of SARS-CoV-2 named Delta is intractably contagious and responsible for more than four million deaths over the world. Therefore, it is vital to possess a self-testing service of SARS-CoV-2 at home. In this study, we introduce Fruit-CoV, a two-stage vision framework, which is capable of detecting SARS-CoV-2 infections through recorded cough sounds. Specifically, we convert sounds into Log-Mel Spectrograms and use the EfficientNet-V2 network to extract its visual features in the first stage. In the second stage, we use 14 convolutional layers extracted from the large-scale Pretrained Audio Neural Networks for audio pattern recognition (PANNs) and the Wavegram-Log-Mel-CNN to aggregate feature representations of the Log-Mel Spectrograms. Finally, we use the combined features to train a binary classifier. In this study, we use a dataset provided by the AICovidVN 115M Challenge, which includes a total of 7371 recorded cough sounds collected throughout Vietnam, India, and Switzerland. Experimental results show that our proposed model achieves an AUC score of 92.8% and ranks the 1st place on the leaderboard of the AICovidVN Challenge. More importantly, our proposed framework can be integrated into a call center or a VoIP system to speed up detecting SARS-CoV-2 infections through online/recorded cough sounds.
Multi-directional Bicycle Robot for Steel Structure Inspection
Mar 27, 2021



This paper presents a novel design of a multi-directional bicycle robot, which targets inspecting general ferromagnetic structures including complex-shaped structures. The locomotion concept is based on arranging two magnetic wheels in a bicycle-like configuration with two independent steering actuators. This configuration allows the robot to possess multi-directional mobility. An additional free joint helps the robot naturally adapt to non-flat and complex surfaces of steel structures. The robot has the biggest advantage to be mechanically simple with high mobility. Besides, the robot is equipped with sensing tools for structure health monitoring. We demonstrate the deployment of our robot to perform steel rust detection on steel bridges. The final inspection results are visualized as 3D models of the bridges together with marked locations of detected rusty areas.