 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaiwen Feng
Explorative Inbetweening of Time and Space
Mar 21, 2024




We introduce bounded generation as a generalized task to control video generation to synthesize arbitrary camera and subject motion based only on a given start and end frame. Our objective is to fully leverage the inherent generalization capability of an image-to-video model without additional training or fine-tuning of the original model. This is achieved through the proposed new sampling strategy, which we call Time Reversal Fusion, that fuses the temporally forward and backward denoising paths conditioned on the start and end frame, respectively. The fused path results in a video that smoothly connects the two frames, generating inbetweening of faithful subject motion, novel views of static scenes, and seamless video looping when the two bounding frames are identical. We curate a diverse evaluation dataset of image pairs and compare against the closest existing methods. We find that Time Reversal Fusion outperforms related work on all subtasks, exhibiting the ability to generate complex motions and 3D-consistent views guided by bounded frames. See project page at https://time-reversal.github.io.
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
Nov 10, 2023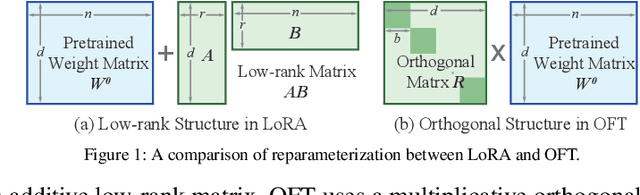
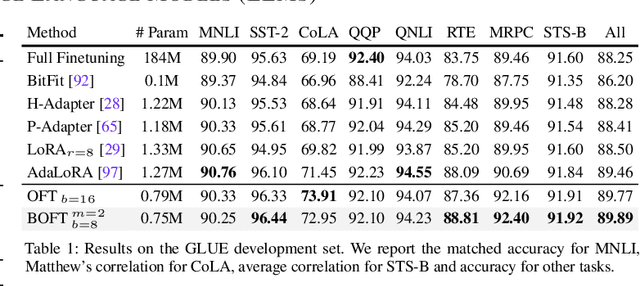
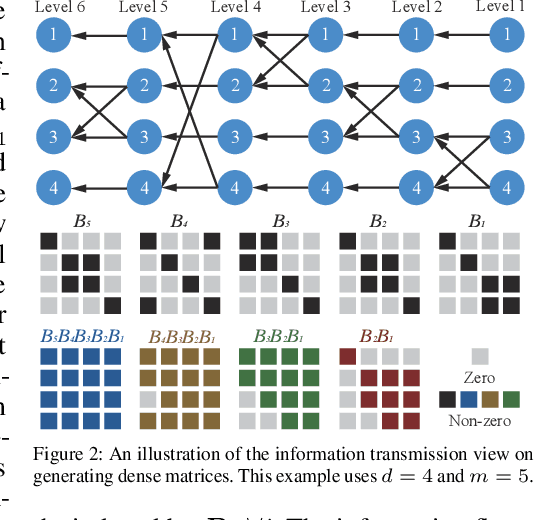

Large foundation models are becoming ubiquitous, but training them from scratch is prohibitively expensive. Thus, efficiently adapting these powerful models to downstream tasks is increasingly important. In this paper, we study a principled finetuning paradigm -- Orthogonal Finetuning (OFT) -- for downstream task adaptation. Despite demonstrating good generalizability, OFT still uses a fairly large number of trainable parameters due to the high dimensionality of orthogonal matrices. To address this, we start by examining OFT from an information transmission perspective, and then identify a few key desiderata that enable better parameter-efficiency. Inspired by how the Cooley-Tukey fast Fourier transform algorithm enables efficient information transmission, we propose an efficient orthogonal parameterization using butterfly structures. We apply this parameterization to OFT, creating a novel parameter-efficient finetuning method, called Orthogonal Butterfly (BOFT). By subsuming OFT as a special case, BOFT introduces a generalized orthogonal finetuning framework. Finally, we conduct an extensive empirical study of adapting large vision transformers, large language models, and text-to-image diffusion models to various downstream tasks in vision and language.
Controlling Text-to-Image Diffusion by Orthogonal Finetuning
Jun 12, 2023
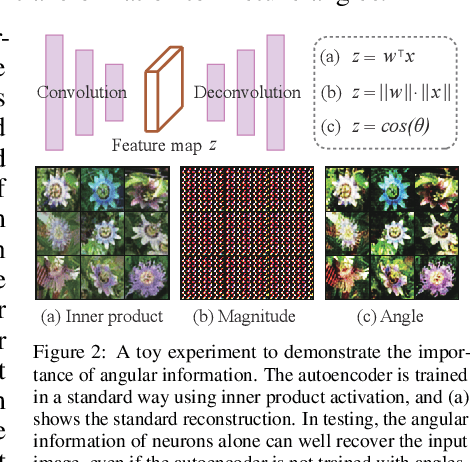
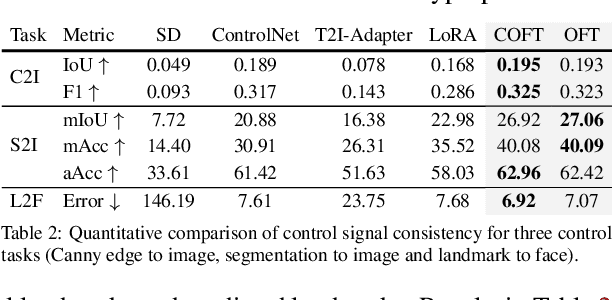

Large text-to-image diffusion models have impressive capabilities in generating photorealistic images from text prompts. How to effectively guide or control these powerful models to perform different downstream tasks becomes an important open problem. To tackle this challenge, we introduce a principled finetuning method -- Orthogonal Finetuning (OFT), for adapting text-to-image diffusion models to downstream tasks. Unlike existing methods, OFT can provably preserve hyperspherical energy which characterizes the pairwise neuron relationship on the unit hypersphere. We find that this property is crucial for preserving the semantic generation ability of text-to-image diffusion models. To improve finetuning stability, we further propose Constrained Orthogonal Finetuning (COFT) which imposes an additional radius constraint to the hypersphere. Specifically, we consider two important finetuning text-to-image tasks: subject-driven generation where the goal is to generate subject-specific images given a few images of a subject and a text prompt, and controllable generation where the goal is to enable the model to take in additional control signals. We empirically show that our OFT framework outperforms existing methods in generation quality and convergence speed.
Generalizing Neural Human Fitting to Unseen Poses With Articulated SE(3) Equivariance
Apr 20, 2023
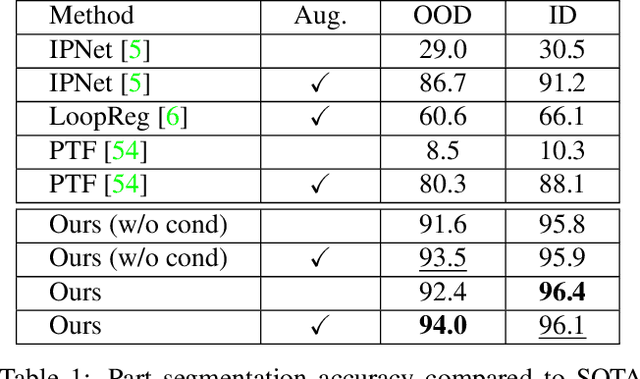
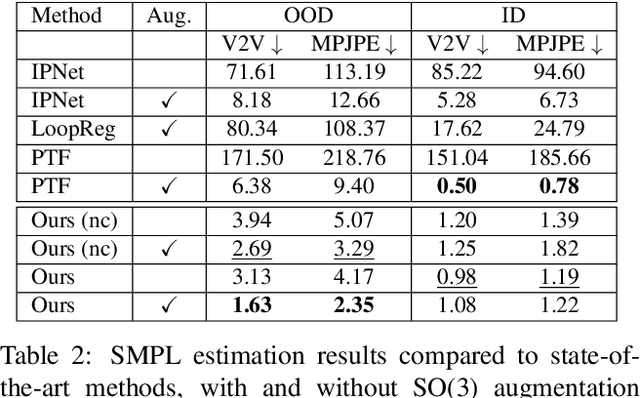
We address the problem of fitting a parametric human body model (SMPL) to point cloud data. Optimization-based methods require careful initialization and are prone to becoming trapped in local optima. Learning-based methods address this but do not generalize well when the input pose is far from those seen during training. For rigid point clouds, remarkable generalization has been achieved by leveraging SE(3)-equivariant networks, but these methods do not work on articulated objects. In this work we extend this idea to human bodies and propose ArtEq, a novel part-based SE(3)-equivariant neural architecture for SMPL model estimation from point clouds. Specifically, we learn a part detection network by leveraging local SO(3) invariance, and regress shape and pose using articulated SE(3) shape-invariant and pose-equivariant networks, all trained end-to-end. Our novel equivariant pose regression module leverages the permutation-equivariant property of self-attention layers to preserve rotational equivariance. Experimental results show that ArtEq can generalize to poses not seen during training, outperforming state-of-the-art methods by 74.5%, without requiring an optimization refinement step. Further, compared with competing works, our method is more than three orders of magnitude faster during inference and has 97.3% fewer parameters. The code and model will be available for research purposes at https://arteq.is.tue.mpg.de.
Towards Racially Unbiased Skin Tone Estimation via Scene Disambiguation
May 08, 2022Virtual facial avatars will play an increasingly important role in immersive communication, games and the metaverse, and it is therefore critical that they be inclusive. This requires accurate recovery of the appearance, represented by albedo, regardless of age, sex, or ethnicity. While significant progress has been made on estimating 3D facial geometry, albedo estimation has received less attention. The task is fundamentally ambiguous because the observed color is a function of albedo and lighting, both of which are unknown. We find that current methods are biased towards light skin tones due to (1) strongly biased priors that prefer lighter pigmentation and (2) algorithmic solutions that disregard the light/albedo ambiguity. To address this, we propose a new evaluation dataset (FAIR) and an algorithm (TRUST) to improve albedo estimation and, hence, fairness. Specifically, we create the first facial albedo evaluation benchmark where subjects are balanced in terms of skin color, and measure accuracy using the Individual Typology Angle (ITA) metric. We then address the light/albedo ambiguity by building on a key observation: the image of the full scene -- as opposed to a cropped image of the face -- contains important information about lighting that can be used for disambiguation. TRUST regresses facial albedo by conditioning both on the face region and a global illumination signal obtained from the scene image. Our experimental results show significant improvement compared to state-of-the-art methods on albedo estimation, both in terms of accuracy and fairness. The evaluation benchmark and code will be made available for research purposes at https://trust.is.tue.mpg.de.
Learning an Animatable Detailed 3D Face Model from In-The-Wild Images
Dec 07, 2020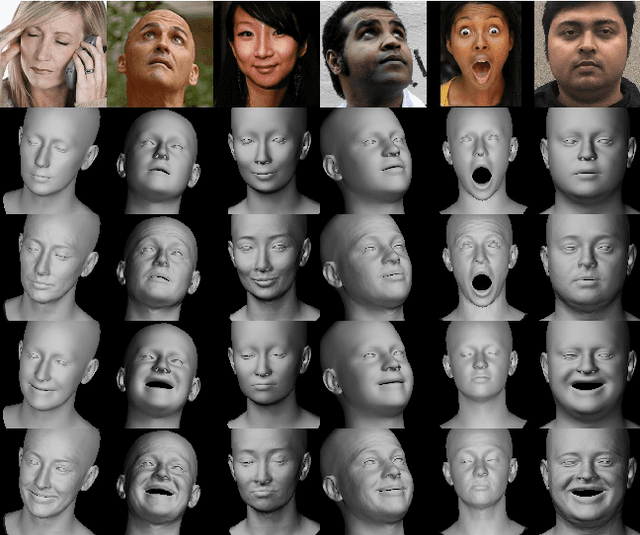
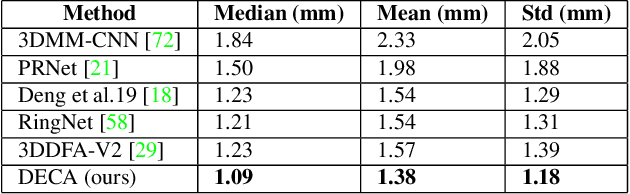
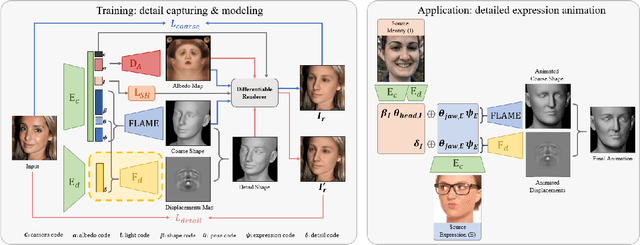
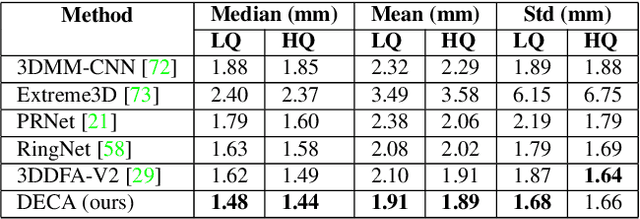
While current monocular 3D face reconstruction methods can recover fine geometric details, they suffer several limitations. Some methods produce faces that cannot be realistically animated because they do not model how wrinkles vary with expression. Other methods are trained on high-quality face scans and do not generalize well to in-the-wild images. We present the first approach to jointly learn a model with animatable detail and a detailed 3D face regressor from in-the-wild images that recovers shape details as well as their relationship to facial expressions. Our DECA (Detailed Expression Capture and Animation) model is trained to robustly produce a UV displacement map from a low-dimensional latent representation that consists of person-specific detail parameters and generic expression parameters, while a regressor is trained to predict detail, shape, albedo, expression, pose and illumination parameters from a single image. We introduce a novel detail-consistency loss to disentangle person-specific details and expression-dependent wrinkles. This disentanglement allows us to synthesize realistic person-specific wrinkles by controlling expression parameters while keeping person-specific details unchanged. DECA achieves state-of-the-art shape reconstruction accuracy on two benchmarks. Qualitative results on in-the-wild data demonstrate DECA's robustness and its ability to disentangle identity and expression dependent details enabling animation of reconstructed faces. The model and code are publicly available at https://github.com/YadiraF/DECA.
Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
May 16, 2019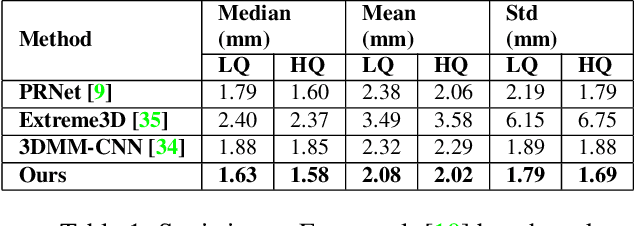
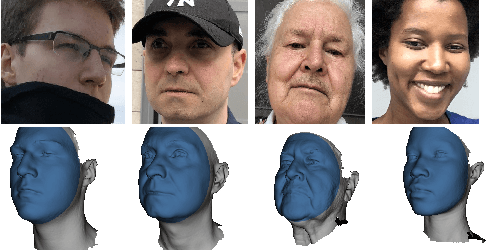
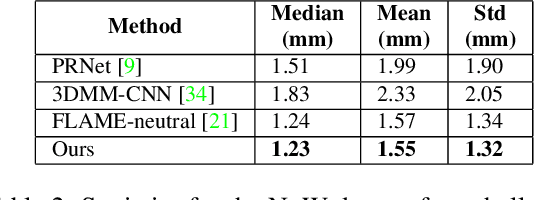
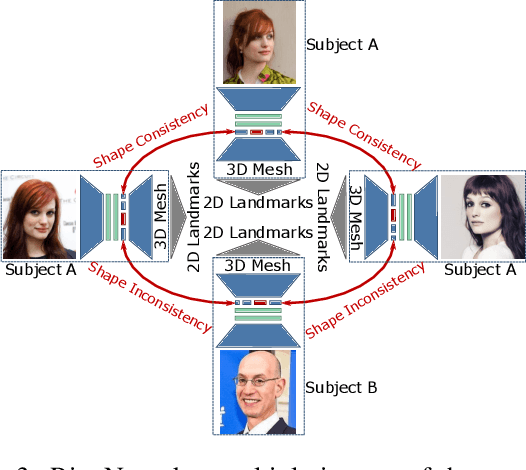
The estimation of 3D face shape from a single image must be robust to variations in lighting, head pose, expression, facial hair, makeup, and occlusions. Robustness requires a large training set of in-the-wild images, which by construction, lack ground truth 3D shape. To train a network without any 2D-to-3D supervision, we present RingNet, which learns to compute 3D face shape from a single image. Our key observation is that an individual's face shape is constant across images, regardless of expression, pose, lighting, etc. RingNet leverages multiple images of a person and automatically detected 2D face features. It uses a novel loss that encourages the face shape to be similar when the identity is the same and different for different people. We achieve invariance to expression by representing the face using the FLAME model. Once trained, our method takes a single image and outputs the parameters of FLAME, which can be readily animated. Additionally we create a new database of faces `not quite in-the-wild' (NoW) with 3D head scans and high-resolution images of the subjects in a wide variety of conditions. We evaluate publicly available methods and find that RingNet is more accurate than methods that use 3D supervision. The dataset, model, and results are available for research purposes at http://ringnet.is.tuebingen.mpg.de.