 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaiyu Wu
CRAFT: Contextual Re-Activation of Filters for face recognition Training
Dec 05, 2023
The first layer of a deep CNN backbone applies filters to an image to extract the basic features available to later layers. During training, some filters may go inactive, mean ing all weights in the filter approach zero. An inactive fil ter in the final model represents a missed opportunity to extract a useful feature. This phenomenon is especially prevalent in specialized CNNs such as for face recogni tion (as opposed to, e.g., ImageNet). For example, in one the most widely face recognition model (ArcFace), about half of the convolution filters in the first layer are inactive. We propose a novel approach designed and tested specif ically for face recognition networks, known as "CRAFT: Contextual Re-Activation of Filters for Face Recognition Training". CRAFT identifies inactive filters during training and reinitializes them based on the context of strong filters at that stage in training. We show that CRAFT reduces fraction of inactive filters from 44% to 32% on average and discovers filter patterns not found by standard training. Compared to standard training without reactivation, CRAFT demonstrates enhanced model accuracy on standard face-recognition benchmark datasets including AgeDB-30, CPLFW, LFW, CALFW, and CFP-FP, as well as on more challenging datasets like IJBB and IJBC.
LogicNet: A Logical Consistency Embedded Face Attribute Learning Network
Nov 19, 2023Ensuring logical consistency in predictions is a crucial yet overlooked aspect in multi-attribute classification. We explore the potential reasons for this oversight and introduce two pressing challenges to the field: 1) How can we ensure that a model, when trained with data checked for logical consistency, yields predictions that are logically consistent? 2) How can we achieve the same with data that hasn't undergone logical consistency checks? Minimizing manual effort is also essential for enhancing automation. To address these challenges, we introduce two datasets, FH41K and CelebA-logic, and propose LogicNet, an adversarial training framework that learns the logical relationships between attributes. Accuracy of LogicNet surpasses that of the next-best approach by 23.05%, 9.96%, and 1.71% on FH37K, FH41K, and CelebA-logic, respectively. In real-world case analysis, our approach can achieve a reduction of more than 50% in the average number of failed cases compared to other methods.
Our Deep CNN Face Matchers Have Developed Achromatopsia
Sep 11, 2023

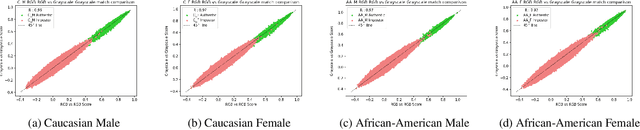
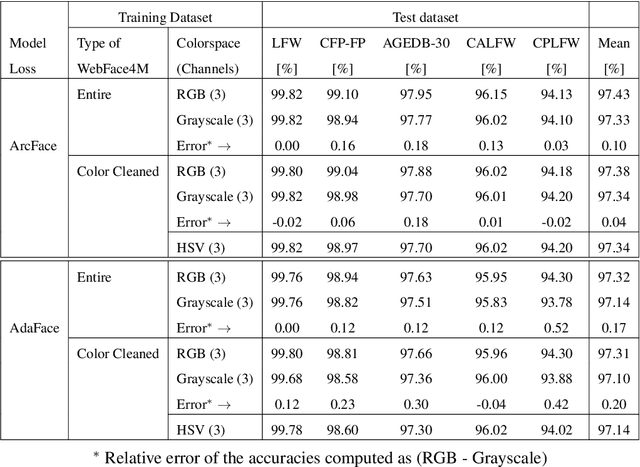
Modern deep CNN face matchers are trained on datasets containing color images. We show that such matchers achieve essentially the same accuracy on the grayscale or the color version of a set of test images. We then consider possible causes for deep CNN face matchers ``not seeing color''. Popular web-scraped face datasets actually have 30 to 60\% of their identities with one or more grayscale images. We analyze whether this grayscale element in the training set impacts the accuracy achieved, and conclude that it does not. Further, we show that even with a 100\% grayscale training set, comparable accuracy is achieved on color or grayscale test images. Then we show that the skin region of an individual's images in a web-scraped training set exhibit significant variation in their mapping to color space. This suggests that color, at least for web-scraped, in-the-wild face datasets, carries limited identity-related information for training state-of-the-art matchers. Finally, we verify that comparable accuracy is achieved from training using single-channel grayscale images, implying that a larger dataset can be used within the same memory limit, with a less computationally intensive early layer.
Beard Segmentation and Recognition Bias
Aug 30, 2023



A person's facial hairstyle, such as presence and size of beard, can significantly impact face recognition accuracy. There are publicly-available deep networks that achieve reasonable accuracy at binary attribute classification, such as beard / no beard, but few if any that segment the facial hair region. To investigate the effect of facial hair in a rigorous manner, we first created a set of fine-grained facial hair annotations to train a segmentation model and evaluate its accuracy across African-American and Caucasian face images. We then use our facial hair segmentations to categorize image pairs according to the degree of difference or similarity in the facial hairstyle. We find that the False Match Rate (FMR) for image pairs with different categories of facial hairstyle varies by a factor of over 10 for African-American males and over 25 for Caucasian males. To reduce the bias across image pairs with different facial hairstyles, we propose a scheme for adaptive thresholding based on facial hairstyle similarity. Evaluation on a subject-disjoint set of images shows that adaptive similarity thresholding based on facial hairstyles of the image pair reduces the ratio between the highest and lowest FMR across facial hairstyle categories for African-American from 10.7 to 1.8 and for Caucasians from 25.9 to 1.3. Facial hair annotations and facial hair segmentation model will be publicly available.
A Real Balanced Dataset For Understanding Bias? Factors That Impact Accuracy, Not Numbers of Identities and Images
Apr 17, 2023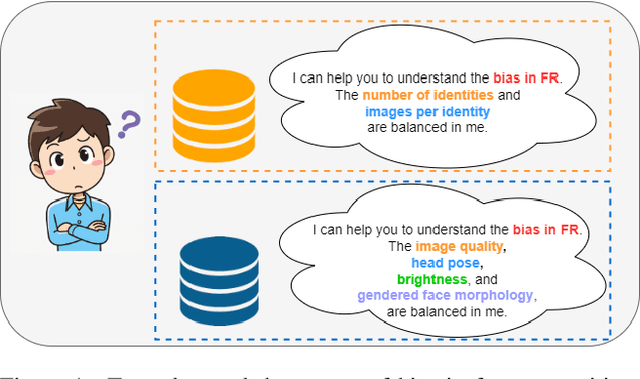
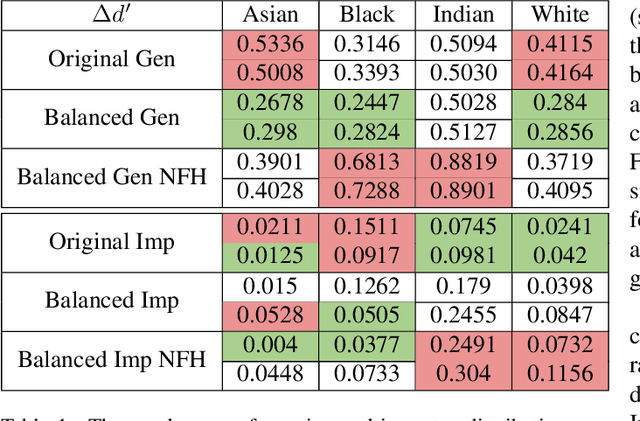
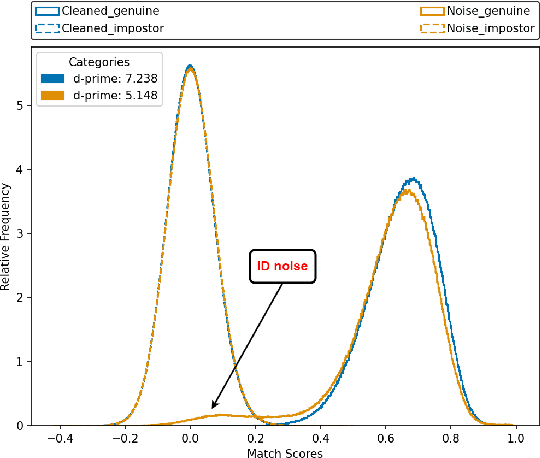
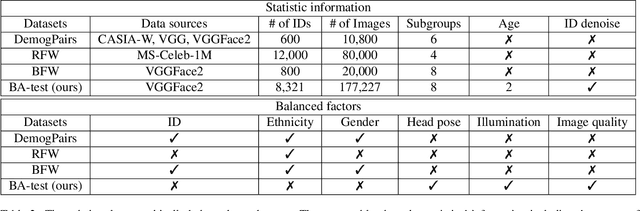
The issue of disparities in face recognition accuracy across demographic groups has attracted increasing attention in recent years. Various face image datasets have been proposed as 'fair' or 'balanced' to assess the accuracy of face recognition algorithms across demographics. While these datasets often balance the number of identities and images across demographic groups. It is important to note that the number of identities and images in an evaluation dataset are not the driving factors for 1-to-1 face matching accuracy. Moreover, balancing the number of identities and images does not ensure balance in other factors known to impact accuracy, such as head pose, brightness, and image quality. We demonstrate these issues using several recently proposed datasets. To enhance the capacity for less biased evaluations, we propose a bias-aware toolkit that facilitates the creation of cross-demographic evaluation datasets balanced on factors mentioned in this paper.
Logical Consistency and Greater Descriptive Power for Facial Hair Attribute Learning
Feb 22, 2023
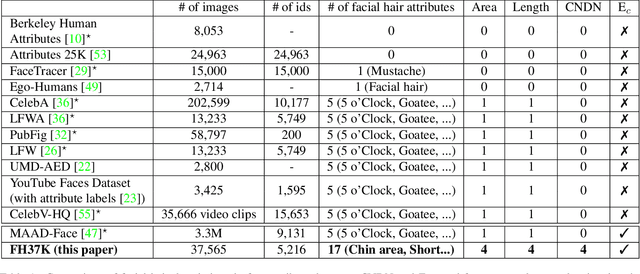


Face attribute research has so far used only simple binary attributes for facial hair; e.g., beard / no beard. We have created a new, more descriptive facial hair annotation scheme and applied it to create a new facial hair attribute dataset, FH37K. Face attribute research also so far has not dealt with logical consistency and completeness. For example, in prior research, an image might be classified as both having no beard and also having a goatee (a type of beard). We show that the test accuracy of previous classification methods on facial hair attribute classification drops significantly if logical consistency of classifications is enforced. We propose a logically consistent prediction loss, LCPLoss, to aid learning of logical consistency across attributes, and also a label compensation training strategy to eliminate the problem of no positive prediction across a set of related attributes. Using an attribute classifier trained on FH37K, we investigate how facial hair affects face recognition accuracy, including variation across demographics. Results show that similarity and difference in facial hairstyle have important effects on the impostor and genuine score distributions in face recognition.
Consistency and Accuracy of CelebA Attribute Values
Oct 13, 2022
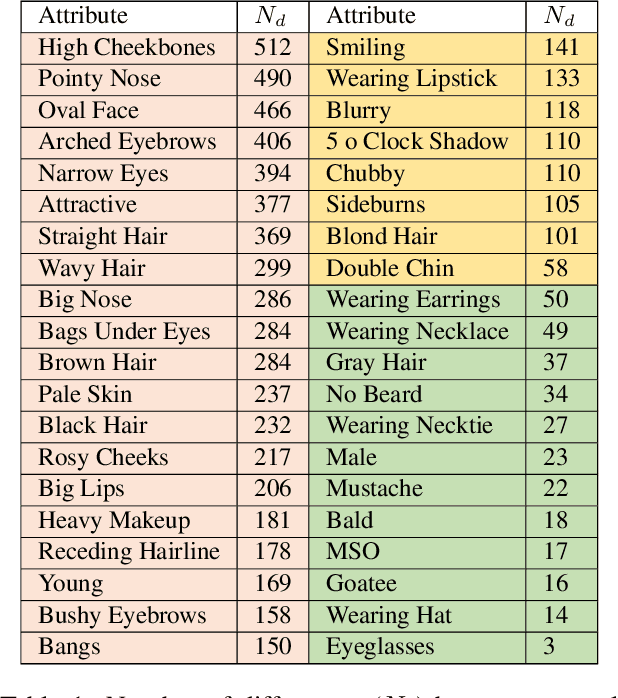

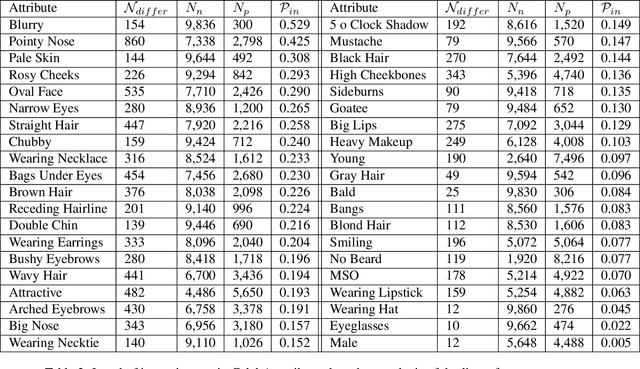
We report the first analysis of the experimental foundations of facial attribute classification. An experiment with two annotators independently assigning values shows that only 12 of 40 commonly-used attributes are assigned values with >= 95% consistency, and that three (high cheekbones, pointed nose, oval face) have random consistency (50%). These results show that the binary face attributes currently used in this research area could re-focused to be more objective. We identify 5,068 duplicate face appearances in CelebA, the most widely used dataset in this research area, and find that individual attributes have contradicting values on from 10 to 860 of 5,068 duplicates. Manual audit of a subset of CelebA estimates error rates as high as 40% for (no beard=false), even though the labeling consistency experiment indicates that no beard could be assigned with >= 95% consistency. Selecting the mouth slightly open (MSO) attribute for deeper analysis, we estimate the error rate for (MSO=true) at about 20% and for (MSO=false) at about 2%. We create a corrected version of the MSO attribute values, and compare classification models created using the original versus corrected values. The corrected values enable a model that achieves higher accuracy than has been previously reported for MSO. Also, ScoreCAM visualizations show that the model created using the corrected attribute values is in fact more focused on the mouth region of the face. These results show that the error rate in the current CelebA attribute values should be reduced in order to enable learning of better models. The corrected attribute values for CelebA's MSO and the CelebA facial hair attributes will be made available upon publication.
Face Recognition Accuracy Across Demographics: Shining a Light Into the Problem
Jun 04, 2022



This is the first work that we are aware of to explore how the level of brightness of the skin region in a pair of face images impacts face recognition accuracy. Image pairs with both images having mean face skin brightness in an upper-middle range of brightness are found to have the highest matching accuracy across demographics and matchers. Image pairs with both images having mean face skin brightness that is too dark or too light are found to have an increased false match rate (FMR). Image pairs with strongly different face skin brightness are found to have decreased FMR and increased false non-match rate (FNMR). Using a brightness information metric that captures the variation in brightness in the face skin region, the variation in matching accuracy is shown to correlate with the level of information available in the face skin region. For operational scenarios where image acquisition is controlled, we propose acquiring images with lighting adjusted to yield face skin brightness in a narrow range.
Research on Fast Text Recognition Method for Financial Ticket Image
Jan 05, 2021



Currently, deep learning methods have been widely applied in and thus promoted the development of different fields. In the financial accounting field, the rapid increase in the number of financial tickets dramatically increases labor costs; hence, using a deep learning method to relieve the pressure on accounting is necessary. At present, a few works have applied deep learning methods to financial ticket recognition. However, first, their approaches only cover a few types of tickets. In addition, the precision and speed of their recognition models cannot meet the requirements of practical financial accounting systems. Moreover, none of the methods provides a detailed analysis of both the types and content of tickets. Therefore, this paper first analyzes the different features of 482 kinds of financial tickets, divides all kinds of financial tickets into three categories and proposes different recognition patterns for each category. These recognition patterns can meet almost all types of financial ticket recognition needs. Second, regarding the fixed format types of financial tickets (accounting for 68.27\% of the total types of tickets), we propose a simple yet efficient network named the Financial Ticket Faster Detection network (FTFDNet) based on a Faster RCNN. Furthermore, according to the characteristics of the financial ticket text, in order to obtain higher recognition accuracy, the loss function, Region Proposal Network (RPN), and Non-Maximum Suppression (NMS) are improved to make FTFDNet focus more on text. Finally, we perform a comparison with the best ticket recognition model from the ICDAR2019 invoice competition. The experimental results illustrate that FTFDNet increases the processing speed by 50\% while maintaining similar precision.
Towards Boosting the Channel Attention in Real Image Denoising : Sub-band Pyramid Attention
Dec 23, 2020



Convolutional layers in Artificial Neural Networks (ANN) treat the channel features equally without feature selection flexibility. While using ANNs for image denoising in real-world applications with unknown noise distributions, particularly structured noise with learnable patterns, modeling informative features can substantially boost the performance. Channel attention methods in real image denoising tasks exploit dependencies between the feature channels, hence being a frequency component filtering mechanism. Existing channel attention modules typically use global statics as descriptors to learn the inter-channel correlations. This method deems inefficient at learning representative coefficients for re-scaling the channels in frequency level. This paper proposes a novel Sub-band Pyramid Attention (SPA) based on wavelet sub-band pyramid to recalibrate the frequency components of the extracted features in a more fine-grained fashion. We equip the SPA blocks on a network designed for real image denoising. Experimental results show that the proposed method achieves a remarkable improvement than the benchmark naive channel attention block. Furthermore, our results show how the pyramid level affects the performance of the SPA blocks and exhibits favorable generalization capability for the SPA blocks.