 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHakim Hacid
Would You Trust an AI Doctor? Building Reliable Medical Predictions with Kernel Dropout Uncertainty
Apr 16, 2024
The growing capabilities of AI raise questions about their trustworthiness in healthcare, particularly due to opaque decision-making and limited data availability. This paper proposes a novel approach to address these challenges, introducing a Bayesian Monte Carlo Dropout model with kernel modelling. Our model is designed to enhance reliability on small medical datasets, a crucial barrier to the wider adoption of AI in healthcare. This model leverages existing language models for improved effectiveness and seamlessly integrates with current workflows. We demonstrate significant improvements in reliability, even with limited data, offering a promising step towards building trust in AI-driven medical predictions and unlocking its potential to improve patient care.
BayesJudge: Bayesian Kernel Language Modelling with Confidence Uncertainty in Legal Judgment Prediction
Apr 16, 2024Predicting legal judgments with reliable confidence is paramount for responsible legal AI applications. While transformer-based deep neural networks (DNNs) like BERT have demonstrated promise in legal tasks, accurately assessing their prediction confidence remains crucial. We present a novel Bayesian approach called BayesJudge that harnesses the synergy between deep learning and deep Gaussian Processes to quantify uncertainty through Bayesian kernel Monte Carlo dropout. Our method leverages informative priors and flexible data modelling via kernels, surpassing existing methods in both predictive accuracy and confidence estimation as indicated through brier score. Extensive evaluations of public legal datasets showcase our model's superior performance across diverse tasks. We also introduce an optimal solution to automate the scrutiny of unreliable predictions, resulting in a significant increase in the accuracy of the model's predictions by up to 27\%. By empowering judges and legal professionals with more reliable information, our work paves the way for trustworthy and transparent legal AI applications that facilitate informed decisions grounded in both knowledge and quantified uncertainty.
Training Machine Learning models at the Edge: A Survey
Mar 13, 2024



Edge Computing (EC) has gained significant traction in recent years, promising enhanced efficiency by integrating Artificial Intelligence (AI) capabilities at the edge. While the focus has primarily been on the deployment and inference of Machine Learning (ML) models at the edge, the training aspect remains less explored. This survey delves into Edge Learning (EL), specifically the optimization of ML model training at the edge. The objective is to comprehensively explore diverse approaches and methodologies in EL, synthesize existing knowledge, identify challenges, and highlight future trends. Utilizing Scopus' advanced search, relevant literature on EL was identified, revealing a concentration of research efforts in distributed learning methods, particularly Federated Learning (FL). This survey further provides a guideline for comparing techniques used to optimize ML for edge learning, along with an exploration of different frameworks, libraries, and simulation tools available for EL. In doing so, the paper contributes to a holistic understanding of the current landscape and future directions in the intersection of edge computing and machine learning, paving the way for informed comparisons between optimization methods and techniques designed for edge learning.
MAGNETO: Edge AI for Human Activity Recognition -- Privacy and Personalization
Feb 14, 2024Human activity recognition (HAR) is a well-established field, significantly advanced by modern machine learning (ML) techniques. While companies have successfully integrated HAR into consumer products, they typically rely on a predefined activity set, which limits personalizations at the user level (edge devices). Despite advancements in Incremental Learning for updating models with new data, this often occurs on the Cloud, necessitating regular data transfers between cloud and edge devices, thus leading to data privacy issues. In this paper, we propose MAGNETO, an Edge AI platform that pushes HAR tasks from the Cloud to the Edge. MAGNETO allows incremental human activity learning directly on the Edge devices, without any data exchange with the Cloud. This enables strong privacy guarantees, low processing latency, and a high degree of personalization for users. In particular, we demonstrate MAGNETO in an Android device, validating the whole pipeline from data collection to result visualization.
Practical Insights on Incremental Learning of New Human Physical Activity on the Edge
Aug 22, 2023Edge Machine Learning (Edge ML), which shifts computational intelligence from cloud-based systems to edge devices, is attracting significant interest due to its evident benefits including reduced latency, enhanced data privacy, and decreased connectivity reliance. While these advantages are compelling, they introduce unique challenges absent in traditional cloud-based approaches. In this paper, we delve into the intricacies of Edge-based learning, examining the interdependencies among: (i) constrained data storage on Edge devices, (ii) limited computational power for training, and (iii) the number of learning classes. Through experiments conducted using our MAGNETO system, that focused on learning human activities via data collected from mobile sensors, we highlight these challenges and offer valuable perspectives on Edge ML.
Opportunistic Air Quality Monitoring and Forecasting with Expandable Graph Neural Networks
Jul 29, 2023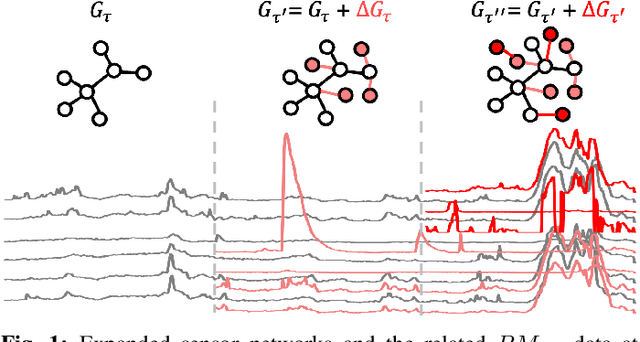
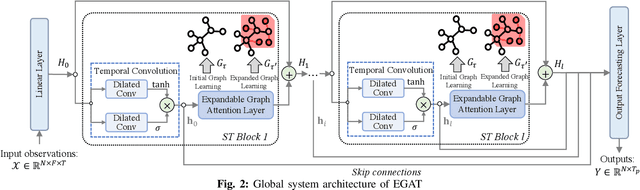

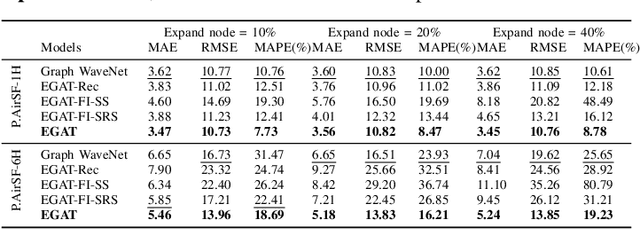
Air Quality Monitoring and Forecasting has been a popular research topic in recent years. Recently, data-driven approaches for air quality forecasting have garnered significant attention, owing to the availability of well-established data collection facilities in urban areas. Fixed infrastructures, typically deployed by national institutes or tech giants, often fall short in meeting the requirements of diverse personalized scenarios, e.g., forecasting in areas without any existing infrastructure. Consequently, smaller institutes or companies with limited budgets are compelled to seek tailored solutions by introducing more flexible infrastructures for data collection. In this paper, we propose an expandable graph attention network (EGAT) model, which digests data collected from existing and newly-added infrastructures, with different spatial structures. Additionally, our proposal can be embedded into any air quality forecasting models, to apply to the scenarios with evolving spatial structures. The proposal is validated over real air quality data from PurpleAir.
Unleashing Realistic Air Quality Forecasting: Introducing the Ready-to-Use PurpleAirSF Dataset
Jun 24, 2023



Air quality forecasting has garnered significant attention recently, with data-driven models taking center stage due to advancements in machine learning and deep learning models. However, researchers face challenges with complex data acquisition and the lack of open-sourced datasets, hindering efficient model validation. This paper introduces PurpleAirSF, a comprehensive and easily accessible dataset collected from the PurpleAir network. With its high temporal resolution, various air quality measures, and diverse geographical coverage, this dataset serves as a useful tool for researchers aiming to develop novel forecasting models, study air pollution patterns, and investigate their impacts on health and the environment. We present a detailed account of the data collection and processing methods employed to build PurpleAirSF. Furthermore, we conduct preliminary experiments using both classic and modern spatio-temporal forecasting models, thereby establishing a benchmark for future air quality forecasting tasks.
Regularization of the policy updates for stabilizing Mean Field Games
Apr 13, 2023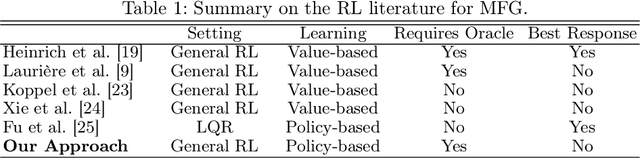
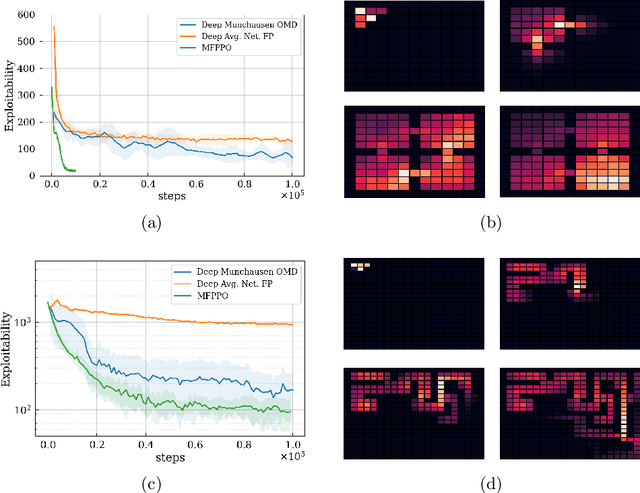

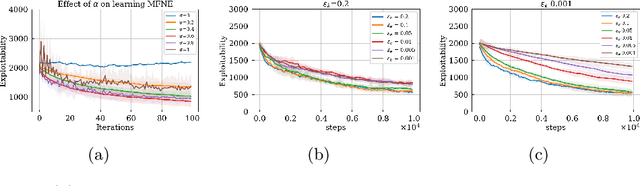
This work studies non-cooperative Multi-Agent Reinforcement Learning (MARL) where multiple agents interact in the same environment and whose goal is to maximize the individual returns. Challenges arise when scaling up the number of agents due to the resultant non-stationarity that the many agents introduce. In order to address this issue, Mean Field Games (MFG) rely on the symmetry and homogeneity assumptions to approximate games with very large populations. Recently, deep Reinforcement Learning has been used to scale MFG to games with larger number of states. Current methods rely on smoothing techniques such as averaging the q-values or the updates on the mean-field distribution. This work presents a different approach to stabilize the learning based on proximal updates on the mean-field policy. We name our algorithm Mean Field Proximal Policy Optimization (MF-PPO), and we empirically show the effectiveness of our method in the OpenSpiel framework.
On Handling Catastrophic Forgetting for Incremental Learning of Human Physical Activity on the Edge
Feb 18, 2023



Human activity recognition (HAR) has been a classic research problem. In particular, with recent machine learning (ML) techniques, the recognition task has been largely investigated by companies and integrated into their products for customers. However, most of them apply a predefined activity set and conduct the learning process on the cloud, hindering specific personalizations from end users (i.e., edge devices). Even though recent progress in Incremental Learning allows learning new-class data on the fly, the learning process is generally conducted on the cloud, requiring constant data exchange between cloud and edge devices, thus leading to data privacy issues. In this paper, we propose PILOTE, which pushes the incremental learning process to the extreme edge, while providing reliable data privacy and practical utility, e.g., low processing latency, personalization, etc. In particular, we consider the practical challenge of extremely limited data during the incremental learning process on edge, where catastrophic forgetting is required to be handled in a practical way. We validate PILOTE with extensive experiments on human activity data collected from mobile sensors. The results show PILOTE can work on edge devices with extremely limited resources while providing reliable performance.
A Review and a Taxonomy of Edge Machine Learning: Requirements, Paradigms, and Techniques
Feb 16, 2023



The union of Edge Computing (EC) and Artificial Intelligence (AI) has brought forward the Edge AI concept to provide intelligent solutions close to end-user environment, for privacy preservation, low latency to real-time performance, as well as resource optimization. Machine Learning (ML), as the most advanced branch of AI in the past few years, has shown encouraging results and applications in the edge environment. Nevertheless, edge powered ML solutions are more complex to realize due to the joint constraints from both edge computing and AI domains, and the corresponding solutions are expected to be efficient and adapted in technologies such as data processing, model compression, distributed inference, and advanced learning paradigms for Edge ML requirements. Despite that a great attention of Edge ML is gained in both academic and industrial communities, we noticed the lack of a complete survey on existing Edge ML technologies to provide a common understanding of this concept. To tackle this, this paper aims at providing a comprehensive taxonomy and a systematic review of Edge ML techniques: we start by identifying the Edge ML requirements driven by the joint constraints. We then survey more than twenty paradigms and techniques along with their representative work, covering two main parts: edge inference, and edge learning. In particular, we analyze how each technique fits into Edge ML by meeting a subset of the identified requirements. We also summarize Edge ML open issues to shed light on future directions for Edge ML.