 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamid R. Rabiee
CRISPR: Ensemble Model
Mar 05, 2024
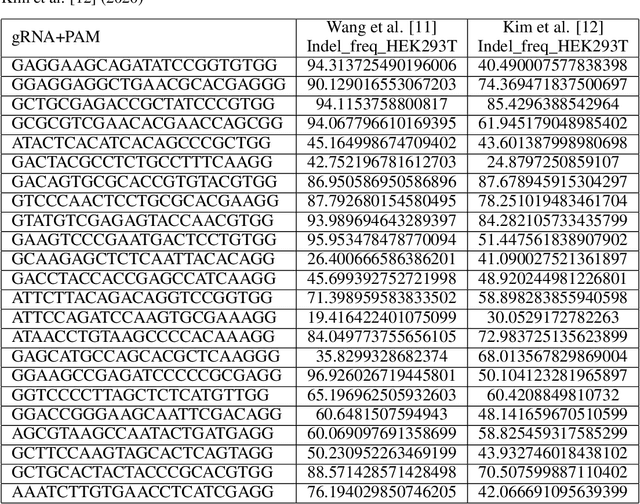
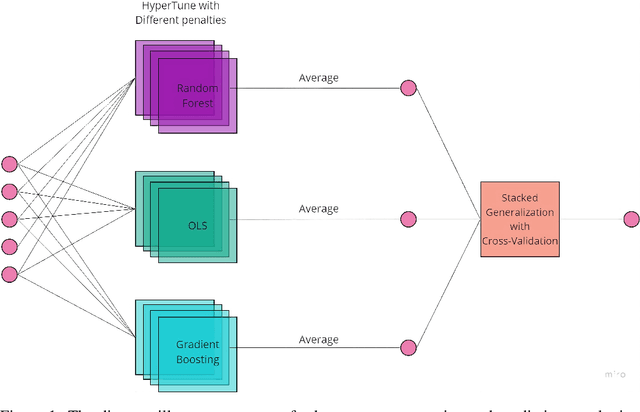
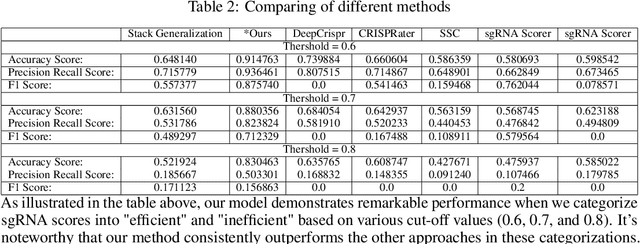
Clustered Regularly Interspaced Short Palindromic Repeats (CRISPR) is a gene editing technology that has revolutionized the fields of biology and medicine. However, one of the challenges of using CRISPR is predicting the on-target efficacy and off-target sensitivity of single-guide RNAs (sgRNAs). This is because most existing methods are trained on separate datasets with different genes and cells, which limits their generalizability. In this paper, we propose a novel ensemble learning method for sgRNA design that is accurate and generalizable. Our method combines the predictions of multiple machine learning models to produce a single, more robust prediction. This approach allows us to learn from a wider range of data, which improves the generalizability of our model. We evaluated our method on a benchmark dataset of sgRNA designs and found that it outperformed existing methods in terms of both accuracy and generalizability. Our results suggest that our method can be used to design sgRNAs with high sensitivity and specificity, even for new genes or cells. This could have important implications for the clinical use of CRISPR, as it would allow researchers to design more effective and safer treatments for a variety of diseases.
Epsilon non-Greedy: A Bandit Approach for Unbiased Recommendation via Uniform Data
Oct 07, 2023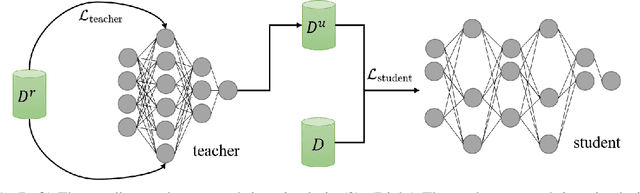
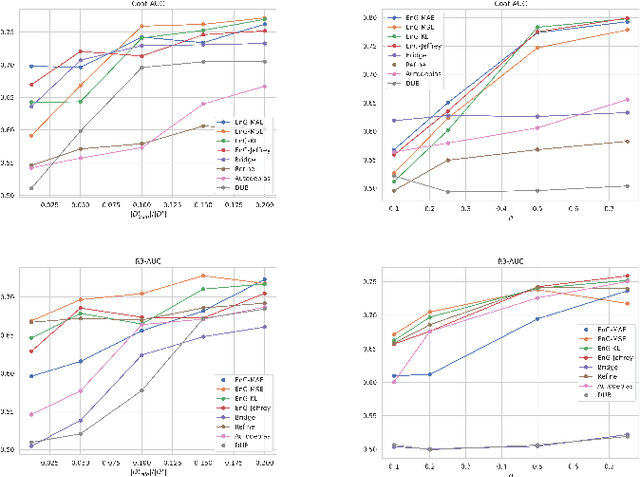
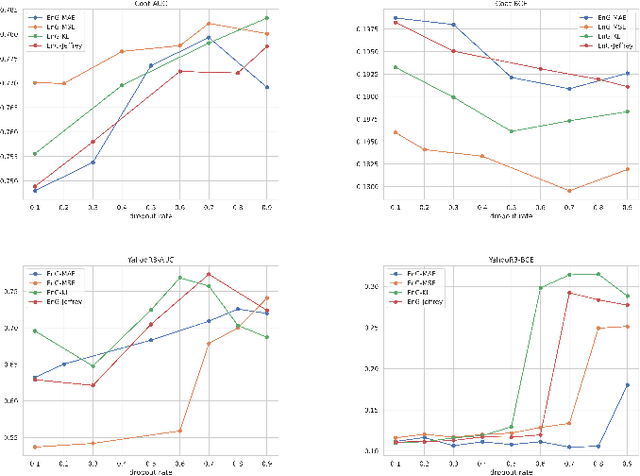
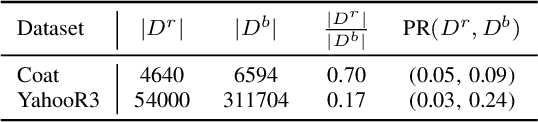
Often, recommendation systems employ continuous training, leading to a self-feedback loop bias in which the system becomes biased toward its previous recommendations. Recent studies have attempted to mitigate this bias by collecting small amounts of unbiased data. While these studies have successfully developed less biased models, they ignore the crucial fact that the recommendations generated by the model serve as the training data for subsequent training sessions. To address this issue, we propose a framework that learns an unbiased estimator using a small amount of uniformly collected data and focuses on generating improved training data for subsequent training iterations. To accomplish this, we view recommendation as a contextual multi-arm bandit problem and emphasize on exploring items that the model has a limited understanding of. We introduce a new offline sequential training schema that simulates real-world continuous training scenarios in recommendation systems, offering a more appropriate framework for studying self-feedback bias. We demonstrate the superiority of our model over state-of-the-art debiasing methods by conducting extensive experiments using the proposed training schema.
DANI: Fast Diffusion Aware Network Inference with Preserving Topological Structure Property
Oct 02, 2023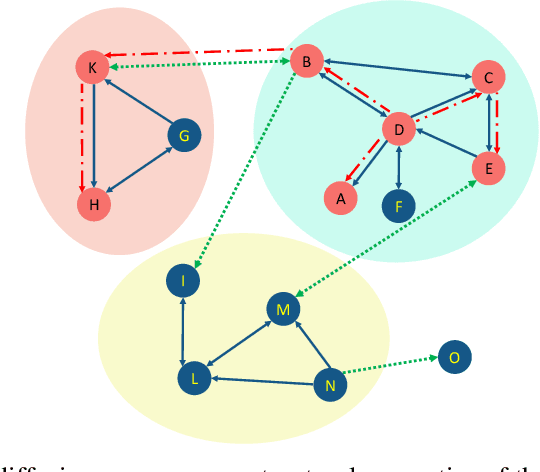

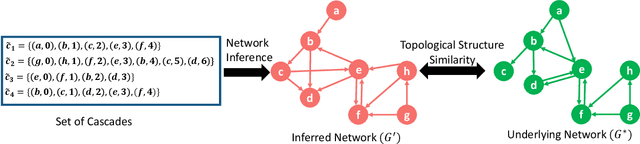

The fast growth of social networks and their data access limitations in recent years has led to increasing difficulty in obtaining the complete topology of these networks. However, diffusion information over these networks is available, and many algorithms have been proposed to infer the underlying networks using this information. The previously proposed algorithms only focus on inferring more links and ignore preserving the critical topological characteristics of the underlying social networks. In this paper, we propose a novel method called DANI to infer the underlying network while preserving its structural properties. It is based on the Markov transition matrix derived from time series cascades, as well as the node-node similarity that can be observed in the cascade behavior from a structural point of view. In addition, the presented method has linear time complexity (increases linearly with the number of nodes, number of cascades, and square of the average length of cascades), and its distributed version in the MapReduce framework is also scalable. We applied the proposed approach to both real and synthetic networks. The experimental results showed that DANI has higher accuracy and lower run time while maintaining structural properties, including modular structure, degree distribution, connected components, density, and clustering coefficients, than well-known network inference methods.
ClusterSeq: Enhancing Sequential Recommender Systems with Clustering based Meta-Learning
Jul 25, 2023In practical scenarios, the effectiveness of sequential recommendation systems is hindered by the user cold-start problem, which arises due to limited interactions for accurately determining user preferences. Previous studies have attempted to address this issue by combining meta-learning with user and item-side information. However, these approaches face inherent challenges in modeling user preference dynamics, particularly for "minor users" who exhibit distinct preferences compared to more common or "major users." To overcome these limitations, we present a novel approach called ClusterSeq, a Meta-Learning Clustering-Based Sequential Recommender System. ClusterSeq leverages dynamic information in the user sequence to enhance item prediction accuracy, even in the absence of side information. This model preserves the preferences of minor users without being overshadowed by major users, and it capitalizes on the collective knowledge of users within the same cluster. Extensive experiments conducted on various benchmark datasets validate the effectiveness of ClusterSeq. Empirical results consistently demonstrate that ClusterSeq outperforms several state-of-the-art meta-learning recommenders. Notably, compared to existing meta-learning methods, our proposed approach achieves a substantial improvement of 16-39% in Mean Reciprocal Rank (MRR).
Domain Adaptation and Generalization on Functional Medical Images: A Systematic Survey
Dec 04, 2022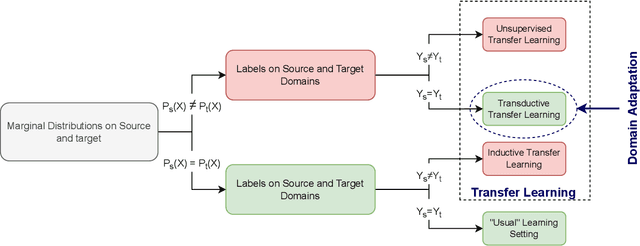
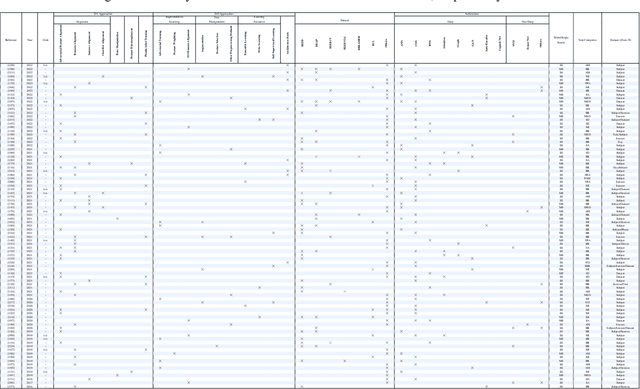
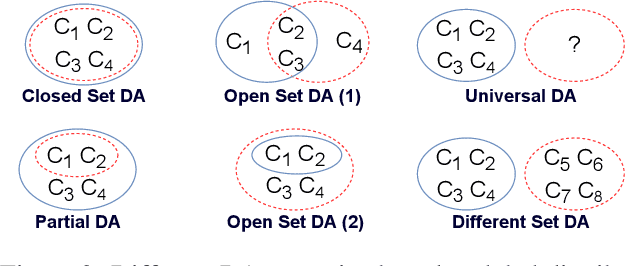
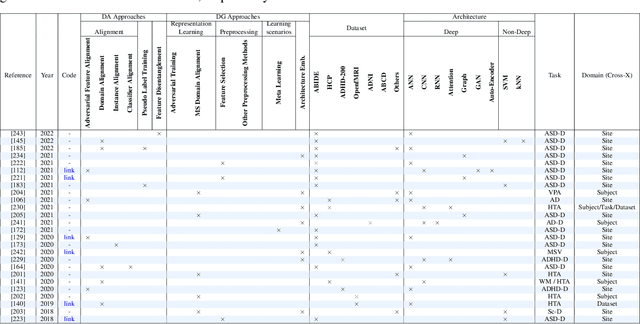
Machine learning algorithms have revolutionized different fields, including natural language processing, computer vision, signal processing, and medical data processing. Despite the excellent capabilities of machine learning algorithms in various tasks and areas, the performance of these models mainly deteriorates when there is a shift in the test and training data distributions. This gap occurs due to the violation of the fundamental assumption that the training and test data are independent and identically distributed (i.i.d). In real-world scenarios where collecting data from all possible domains for training is costly and even impossible, the i.i.d assumption can hardly be satisfied. The problem is even more severe in the case of medical images and signals because it requires either expensive equipment or a meticulous experimentation setup to collect data, even for a single domain. Additionally, the decrease in performance may have severe consequences in the analysis of medical records. As a result of such problems, the ability to generalize and adapt under distribution shifts (domain generalization (DG) and domain adaptation (DA)) is essential for the analysis of medical data. This paper provides the first systematic review of DG and DA on functional brain signals to fill the gap of the absence of a comprehensive study in this era. We provide detailed explanations and categorizations of datasets, approaches, and architectures used in DG and DA on functional brain images. We further address the attention-worthy future tracks in this field.
SCGG: A Deep Structure-Conditioned Graph Generative Model
Sep 20, 2022
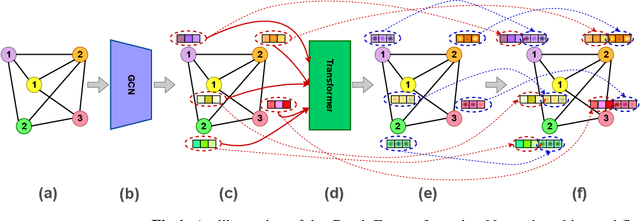
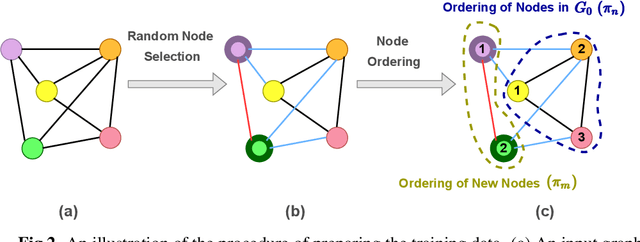

Deep learning-based graph generation approaches have remarkable capacities for graph data modeling, allowing them to solve a wide range of real-world problems. Making these methods able to consider different conditions during the generation procedure even increases their effectiveness by empowering them to generate new graph samples that meet the desired criteria. This paper presents a conditional deep graph generation method called SCGG that considers a particular type of structural conditions. Specifically, our proposed SCGG model takes an initial subgraph and autoregressively generates new nodes and their corresponding edges on top of the given conditioning substructure. The architecture of SCGG consists of a graph representation learning network and an autoregressive generative model, which is trained end-to-end. Using this model, we can address graph completion, a rampant and inherently difficult problem of recovering missing nodes and their associated edges of partially observed graphs. Experimental results on both synthetic and real-world datasets demonstrate the superiority of our method compared with state-of-the-art baselines.
SOInter: A Novel Deep Energy Based Interpretation Method for Explaining Structured Output Models
Feb 20, 2022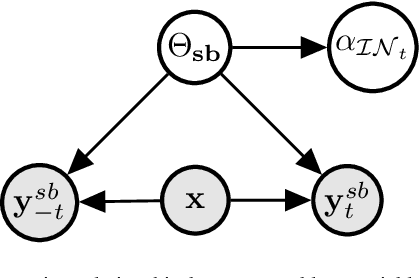
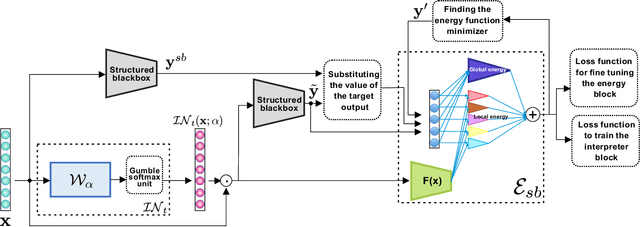
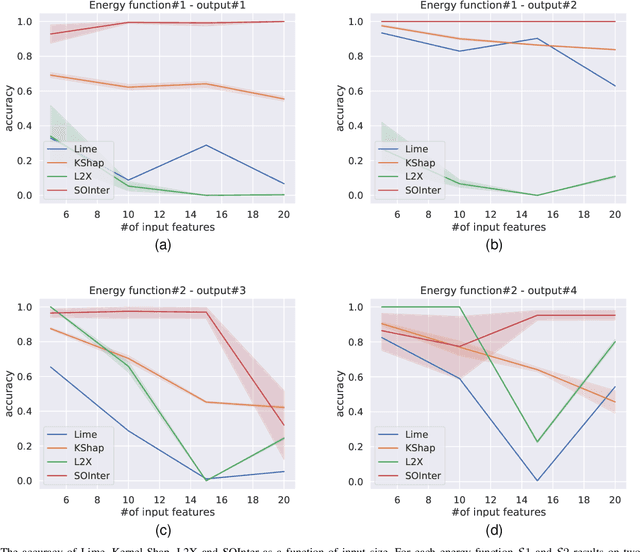
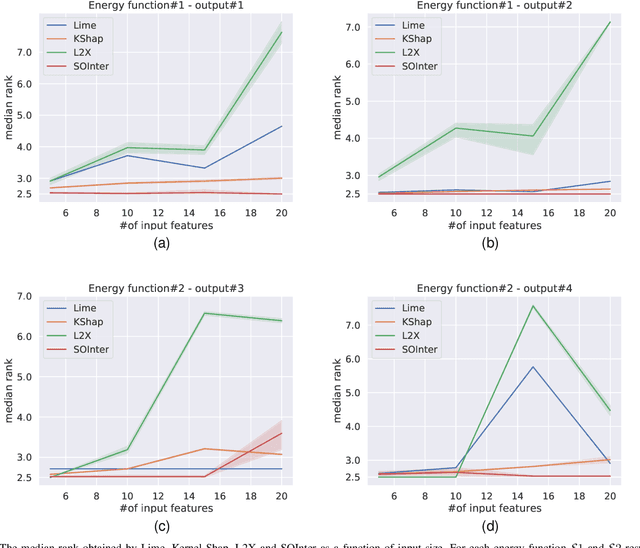
We propose a novel interpretation technique to explain the behavior of structured output models, which learn mappings between an input vector to a set of output variables simultaneously. Because of the complex relationship between the computational path of output variables in structured models, a feature can affect the value of output through other ones. We focus on one of the outputs as the target and try to find the most important features utilized by the structured model to decide on the target in each locality of the input space. In this paper, we assume an arbitrary structured output model is available as a black box and argue how considering the correlations between output variables can improve the explanation performance. The goal is to train a function as an interpreter for the target output variable over the input space. We introduce an energy-based training process for the interpreter function, which effectively considers the structural information incorporated into the model to be explained. The effectiveness of the proposed method is confirmed using a variety of simulated and real data sets.
LAP: An Attention-Based Module for Faithful Interpretation and Knowledge Injection in Convolutional Neural Networks
Jan 27, 2022
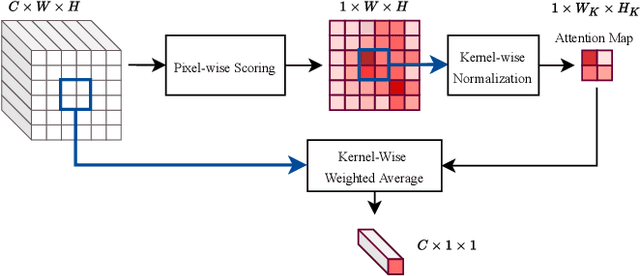
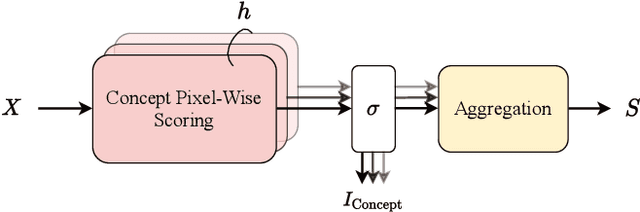

Despite the state-of-the-art performance of deep convolutional neural networks, they are susceptible to bias and malfunction in unseen situations. The complex computation behind their reasoning is not sufficiently human-understandable to develop trust. External explainer methods have tried to interpret the network decisions in a human-understandable way, but they are accused of fallacies due to their assumptions and simplifications. On the other side, the inherent self-interpretability of models, while being more robust to the mentioned fallacies, cannot be applied to the already trained models. In this work, we propose a new attention-based pooling layer, called Local Attention Pooling (LAP), that accomplishes self-interpretability and the possibility for knowledge injection while improving the model's performance. Moreover, several weakly-supervised knowledge injection methodologies are provided to enhance the process of training. We verified our claims by evaluating several LAP-extended models on three different datasets, including Imagenet. The proposed framework offers more valid human-understandable and more faithful-to-the-model interpretations than the commonly used white-box explainer methods.
FNR: A Similarity and Transformer-Based Approachto Detect Multi-Modal FakeNews in Social Media
Dec 02, 2021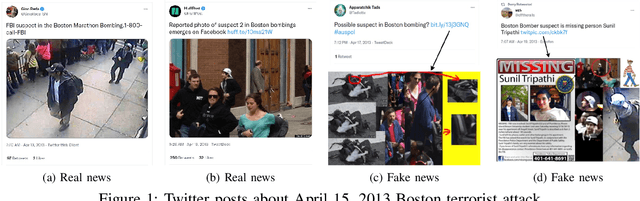
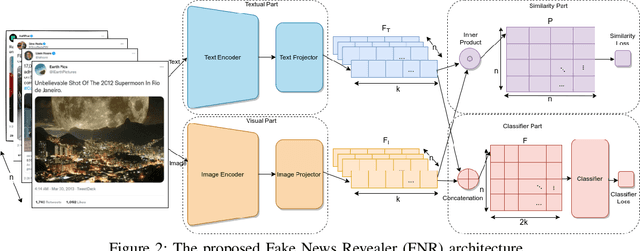
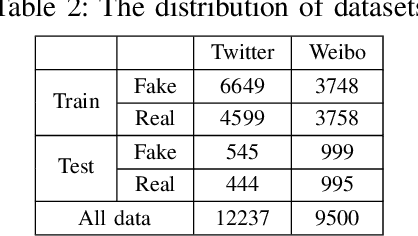
The availability and interactive nature of social media have made them the primary source of news around the globe. The popularity of social media tempts criminals to pursue their immoral intentions by producing and disseminating fake news using seductive text and misleading images. Therefore, verifying social media news and spotting fakes is crucial. This work aims to analyze multi-modal features from texts and images in social media for detecting fake news. We propose a Fake News Revealer (FNR) method that utilizes transform learning to extract contextual and semantic features and contrastive loss to determine the similarity between image and text. We applied FNR on two real social media datasets. The results show the proposed method achieves higher accuracies in detecting fake news compared to the previous works.
CCGG: A Deep Autoregressive Model for Class-Conditional Graph Generation
Oct 07, 2021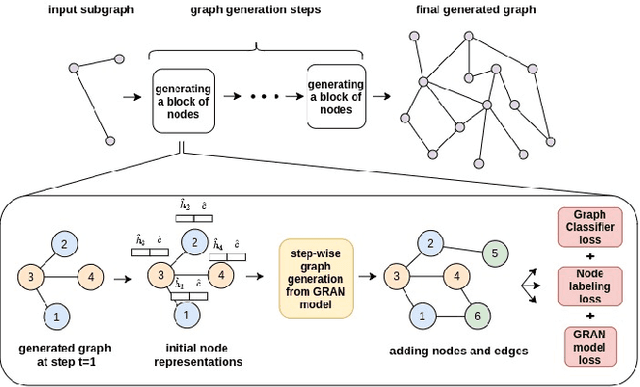
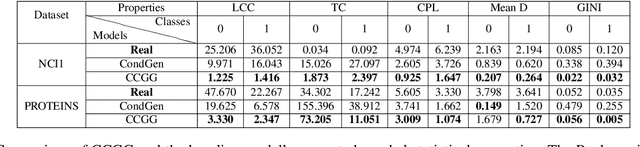
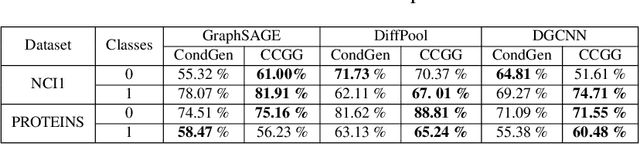

Graph data structures are fundamental for studying connected entities. With an increase in the number of applications where data is represented as graphs, the problem of graph generation has recently become a hot topic in many signal processing areas. However, despite its significance, conditional graph generation that creates graphs with desired features is relatively less explored in previous studies. This paper addresses the problem of class-conditional graph generation that uses class labels as generation constraints by introducing the Class Conditioned Graph Generator (CCGG). We built CCGG by adding the class information as an additional input to a graph generator model and including a classification loss in its total loss along with a gradient passing trick. Our experiments show that CCGG outperforms existing conditional graph generation methods on various datasets. It also manages to maintain the quality of the generated graphs in terms of distribution-based evaluation metrics.