 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHanbin Zhao
APISR: Anime Production Inspired Real-World Anime Super-Resolution
Mar 03, 2024
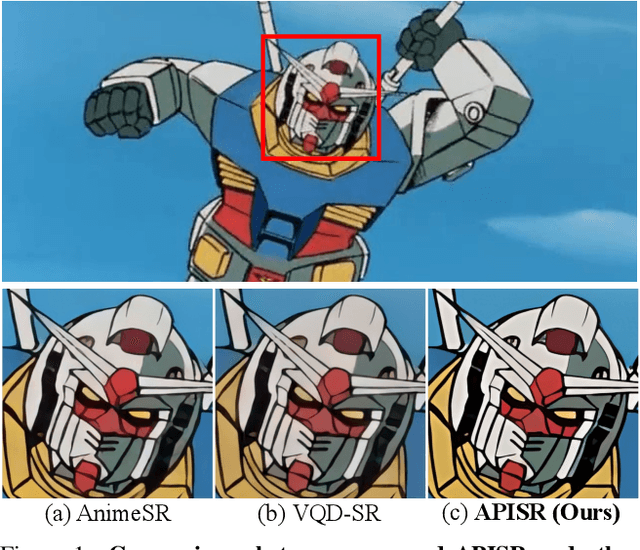
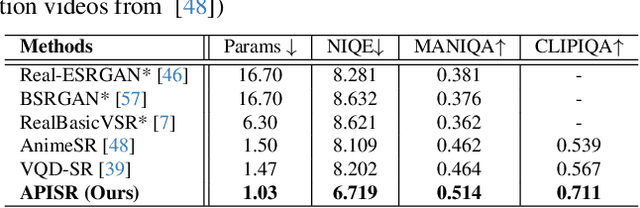
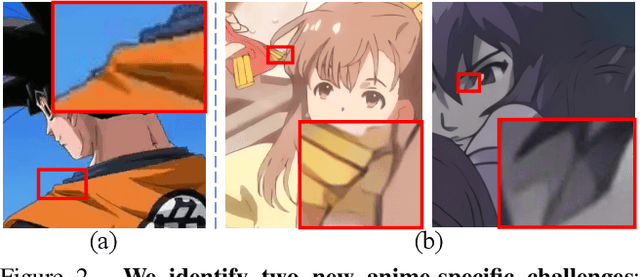
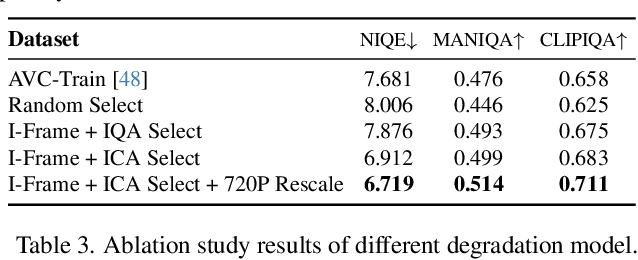
While real-world anime super-resolution (SR) has gained increasing attention in the SR community, existing methods still adopt techniques from the photorealistic domain. In this paper, we analyze the anime production workflow and rethink how to use characteristics of it for the sake of the real-world anime SR. First, we argue that video networks and datasets are not necessary for anime SR due to the repetition use of hand-drawing frames. Instead, we propose an anime image collection pipeline by choosing the least compressed and the most informative frames from the video sources. Based on this pipeline, we introduce the Anime Production-oriented Image (API) dataset. In addition, we identify two anime-specific challenges of distorted and faint hand-drawn lines and unwanted color artifacts. We address the first issue by introducing a prediction-oriented compression module in the image degradation model and a pseudo-ground truth preparation with enhanced hand-drawn lines. In addition, we introduce the balanced twin perceptual loss combining both anime and photorealistic high-level features to mitigate unwanted color artifacts and increase visual clarity. We evaluate our method through extensive experiments on the public benchmark, showing our method outperforms state-of-the-art approaches by a large margin.
Neural Sinkhorn Gradient Flow
Jan 25, 2024Wasserstein Gradient Flows (WGF) with respect to specific functionals have been widely used in the machine learning literature. Recently, neural networks have been adopted to approximate certain intractable parts of the underlying Wasserstein gradient flow and result in efficient inference procedures. In this paper, we introduce the Neural Sinkhorn Gradient Flow (NSGF) model, which parametrizes the time-varying velocity field of the Wasserstein gradient flow w.r.t. the Sinkhorn divergence to the target distribution starting a given source distribution. We utilize the velocity field matching training scheme in NSGF, which only requires samples from the source and target distribution to compute an empirical velocity field approximation. Our theoretical analyses show that as the sample size increases to infinity, the mean-field limit of the empirical approximation converges to the true underlying velocity field. To further enhance model efficiency on high-dimensional tasks, a two-phase NSGF++ model is devised, which first follows the Sinkhorn flow to approach the image manifold quickly ($\le 5$ NFEs) and then refines the samples along a simple straight flow. Numerical experiments with synthetic and real-world benchmark datasets support our theoretical results and demonstrate the effectiveness of the proposed methods.
GAD-PVI: A General Accelerated Dynamic-Weight Particle-Based Variational Inference Framework
Dec 27, 2023Particle-based Variational Inference (ParVI) methods approximate the target distribution by iteratively evolving finite weighted particle systems. Recent advances of ParVI methods reveal the benefits of accelerated position update strategies and dynamic weight adjustment approaches. In this paper, we propose the first ParVI framework that possesses both accelerated position update and dynamical weight adjustment simultaneously, named the General Accelerated Dynamic-Weight Particle-based Variational Inference (GAD-PVI) framework. Generally, GAD-PVI simulates the semi-Hamiltonian gradient flow on a novel Information-Fisher-Rao space, which yields an additional decrease on the local functional dissipation. GAD-PVI is compatible with different dissimilarity functionals and associated smoothing approaches under three information metrics. Experiments on both synthetic and real-world data demonstrate the faster convergence and reduced approximation error of GAD-PVI methods over the state-of-the-art.
Adma-GAN: Attribute-Driven Memory Augmented GANs for Text-to-Image Generation
Sep 28, 2022



As a challenging task, text-to-image generation aims to generate photo-realistic and semantically consistent images according to the given text descriptions. Existing methods mainly extract the text information from only one sentence to represent an image and the text representation effects the quality of the generated image well. However, directly utilizing the limited information in one sentence misses some key attribute descriptions, which are the crucial factors to describe an image accurately. To alleviate the above problem, we propose an effective text representation method with the complements of attribute information. Firstly, we construct an attribute memory to jointly control the text-to-image generation with sentence input. Secondly, we explore two update mechanisms, sample-aware and sample-joint mechanisms, to dynamically optimize a generalized attribute memory. Furthermore, we design an attribute-sentence-joint conditional generator learning scheme to align the feature embeddings among multiple representations, which promotes the cross-modal network training. Experimental results illustrate that the proposed method obtains substantial performance improvements on both the CUB (FID from 14.81 to 8.57) and COCO (FID from 21.42 to 12.39) datasets.
RBC: Rectifying the Biased Context in Continual Semantic Segmentation
Mar 16, 2022



Recent years have witnessed a great development of Convolutional Neural Networks in semantic segmentation, where all classes of training images are simultaneously available. In practice, new images are usually made available in a consecutive manner, leading to a problem called Continual Semantic Segmentation (CSS). Typically, CSS faces the forgetting problem since previous training images are unavailable, and the semantic shift problem of the background class. Considering the semantic segmentation as a context-dependent pixel-level classification task, we explore CSS from a new perspective of context analysis in this paper. We observe that the context of old-class pixels in the new images is much more biased on new classes than that in the old images, which can sharply aggravate the old-class forgetting and new-class overfitting. To tackle the obstacle, we propose a biased-context-rectified CSS framework with a context-rectified image-duplet learning scheme and a biased-context-insensitive consistency loss. Furthermore, we propose an adaptive re-weighting class-balanced learning strategy for the biased class distribution. Our approach outperforms state-of-the-art methods by a large margin in existing CSS scenarios.
When Video Classification Meets Incremental Classes
Jun 30, 2021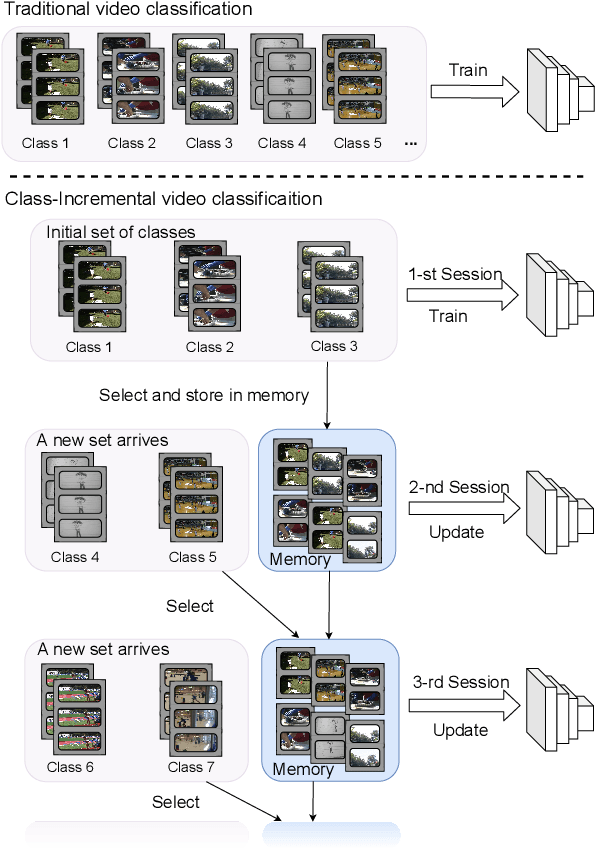

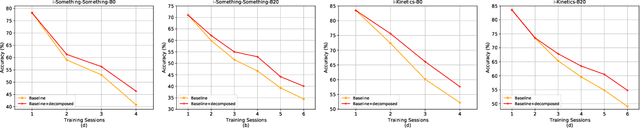
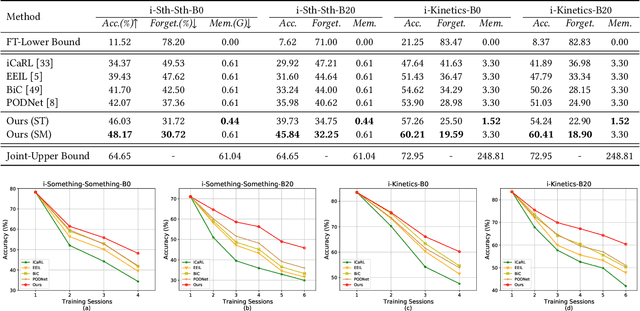
With the rapid development of social media, tremendous videos with new classes are generated daily, which raise an urgent demand for video classification methods that can continuously update new classes while maintaining the knowledge of old videos with limited storage and computing resources. In this paper, we summarize this task as \textit{Class-Incremental Video Classification (CIVC)} and propose a novel framework to address it. As a subarea of incremental learning tasks, the challenge of \textit{catastrophic forgetting} is unavoidable in CIVC. To better alleviate it, we utilize some characteristics of videos. First, we decompose the spatio-temporal knowledge before distillation rather than treating it as a whole in the knowledge transfer process; trajectory is also used to refine the decomposition. Second, we propose a dual granularity exemplar selection method to select and store representative video instances of old classes and key-frames inside videos under a tight storage budget. We benchmark our method and previous SOTA class-incremental learning methods on Something-Something V2 and Kinetics datasets, and our method outperforms previous methods significantly.
Progressive Class-based Expansion Learning For Image Classification
Jun 28, 2021



In this paper, we propose a novel image process scheme called class-based expansion learning for image classification, which aims at improving the supervision-stimulation frequency for the samples of the confusing classes. Class-based expansion learning takes a bottom-up growing strategy in a class-based expansion optimization fashion, which pays more attention to the quality of learning the fine-grained classification boundaries for the preferentially selected classes. Besides, we develop a class confusion criterion to select the confusing class preferentially for training. In this way, the classification boundaries of the confusing classes are frequently stimulated, resulting in a fine-grained form. Experimental results demonstrate the effectiveness of the proposed scheme on several benchmarks.
PcmNet: Position-Sensitive Context Modeling Network for Temporal Action Localization
Mar 09, 2021



Temporal action localization is an important and challenging task that aims to locate temporal regions in real-world untrimmed videos where actions occur and recognize their classes. It is widely acknowledged that video context is a critical cue for video understanding, and exploiting the context has become an important strategy to boost localization performance. However, previous state-of-the-art methods focus more on exploring semantic context which captures the feature similarity among frames or proposals, and neglect positional context which is vital for temporal localization. In this paper, we propose a temporal-position-sensitive context modeling approach to incorporate both positional and semantic information for more precise action localization. Specifically, we first augment feature representations with directed temporal positional encoding, and then conduct attention-based information propagation, in both frame-level and proposal-level. Consequently, the generated feature representations are significantly empowered with the discriminative capability of encoding the position-aware context information, and thus benefit boundary detection and proposal evaluation. We achieve state-of-the-art performance on both two challenging datasets, THUMOS-14 and ActivityNet-1.3, demonstrating the effectiveness and generalization ability of our method.
Unsupervised Domain Adaptation for Image Classification via Structure-Conditioned Adversarial Learning
Mar 04, 2021



Unsupervised domain adaptation (UDA) typically carries out knowledge transfer from a label-rich source domain to an unlabeled target domain by adversarial learning. In principle, existing UDA approaches mainly focus on the global distribution alignment between domains while ignoring the intrinsic local distribution properties. Motivated by this observation, we propose an end-to-end structure-conditioned adversarial learning scheme (SCAL) that is able to preserve the intra-class compactness during domain distribution alignment. By using local structures as structure-aware conditions, the proposed scheme is implemented in a structure-conditioned adversarial learning pipeline. The above learning procedure is iteratively performed by alternating between local structures establishment and structure-conditioned adversarial learning. Experimental results demonstrate the effectiveness of the proposed scheme in UDA scenarios.
Memory Efficient Class-Incremental Learning for Image Classification
Aug 04, 2020



With the memory-resource-limited constraints, class-incremental learning (CIL) usually suffers from the "catastrophic forgetting" problem when updating the joint classification model on the arrival of newly added classes. To cope with the forgetting problem, many CIL methods transfer the knowledge of old classes by preserving some exemplar samples into the size-constrained memory buffer. To utilize the memory buffer more efficiently, we propose to keep more auxiliary low-fidelity exemplar samples rather than the original real high-fidelity exemplar samples. Such memory-efficient exemplar preserving scheme make the old-class knowledge transfer more effective. However, the low-fidelity exemplar samples are often distributed in a different domain away from that of the original exemplar samples, that is, a domain shift. To alleviate this problem, we propose a duplet learning scheme that seeks to construct domain-compatible feature extractors and classifiers, which greatly narrows down the above domain gap. As a result, these low-fidelity auxiliary exemplar samples have the ability to moderately replace the original exemplar samples with a lower memory cost. In addition, we present a robust classifier adaptation scheme, which further refines the biased classifier (learned with the samples containing distillation label knowledge about old classes) with the help of the samples of pure true class labels. Experimental results demonstrate the effectiveness of this work against the state-of-the-art approaches. We will release the code, baselines, and training statistics for all models to facilitate future research.