 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHanqing Zhao
Construction of a Syntactic Analysis Map for Yi Shui School through Text Mining and Natural Language Processing Research
Feb 16, 2024
Entity and relationship extraction is a crucial component in natural language processing tasks such as knowledge graph construction, question answering system design, and semantic analysis. Most of the information of the Yishui school of traditional Chinese Medicine (TCM) is stored in the form of unstructured classical Chinese text. The key information extraction of TCM texts plays an important role in mining and studying the academic schools of TCM. In order to solve these problems efficiently using artificial intelligence methods, this study constructs a word segmentation and entity relationship extraction model based on conditional random fields under the framework of natural language processing technology to identify and extract the entity relationship of traditional Chinese medicine texts, and uses the common weighting technology of TF-IDF information retrieval and data mining to extract important key entity information in different ancient books. The dependency syntactic parser based on neural network is used to analyze the grammatical relationship between entities in each ancient book article, and it is represented as a tree structure visualization, which lays the foundation for the next construction of the knowledge graph of Yishui school and the use of artificial intelligence methods to carry out the research of TCM academic schools.
X-Paste: Revisit Copy-Paste at Scale with CLIP and StableDiffusion
Dec 07, 2022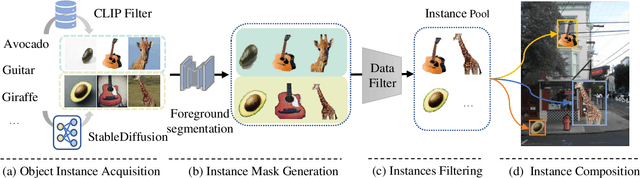
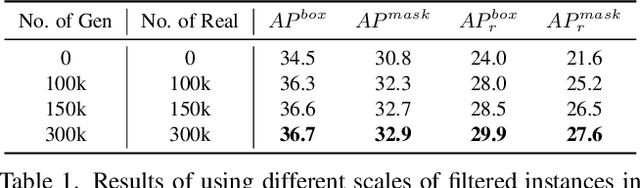

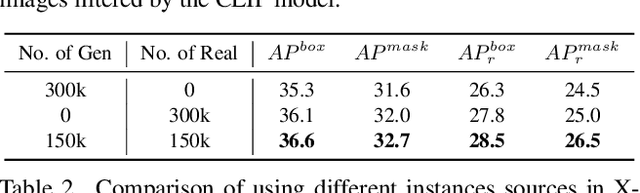
Copy-Paste is a simple and effective data augmentation strategy for instance segmentation. By randomly pasting object instances onto new background images, it creates new training data for free and significantly boosts the segmentation performance, especially for rare object categories. Although diverse, high-quality object instances used in Copy-Paste result in more performance gain, previous works utilize object instances either from human-annotated instance segmentation datasets or rendered from 3D object models, and both approaches are too expensive to scale up to obtain good diversity. In this paper, we revisit Copy-Paste at scale with the power of newly emerged zero-shot recognition models (e.g., CLIP) and text2image models (e.g., StableDiffusion). We demonstrate for the first time that using a text2image model to generate images or zero-shot recognition model to filter noisily crawled images for different object categories is a feasible way to make Copy-Paste truly scalable. To make such success happen, we design a data acquisition and processing framework, dubbed "X-Paste", upon which a systematic study is conducted. On the LVIS dataset, X-Paste provides impressive improvements over the strong baseline CenterNet2 with Swin-L as the backbone. Specifically, it archives +2.6 box AP and +2.1 mask AP gains on all classes and even more significant gains with +6.8 box AP +6.5 mask AP on long-tail classes.
Self-supervised Transformer for Deepfake Detection
Mar 02, 2022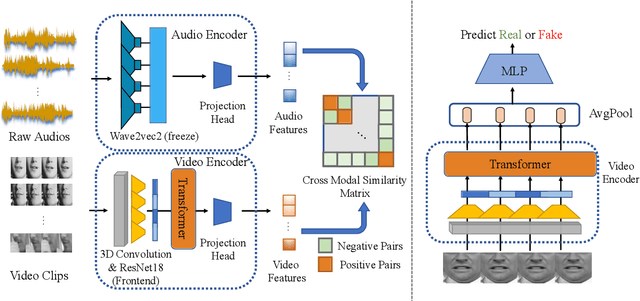
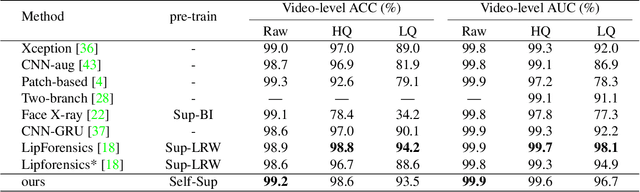
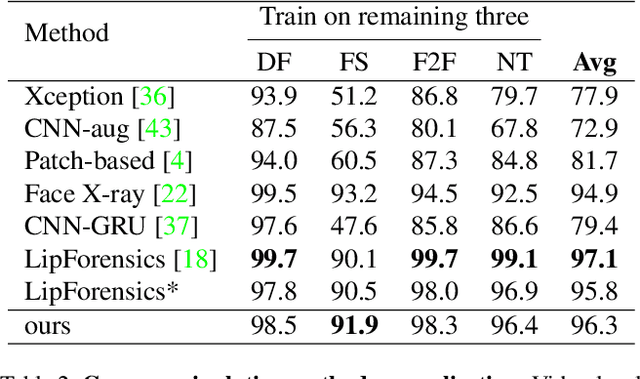
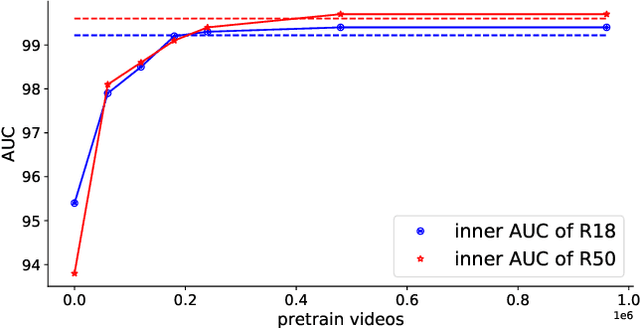
The fast evolution and widespread of deepfake techniques in real-world scenarios require stronger generalization abilities of face forgery detectors. Some works capture the features that are unrelated to method-specific artifacts, such as clues of blending boundary, accumulated up-sampling, to strengthen the generalization ability. However, the effectiveness of these methods can be easily corrupted by post-processing operations such as compression. Inspired by transfer learning, neural networks pre-trained on other large-scale face-related tasks may provide useful features for deepfake detection. For example, lip movement has been proved to be a kind of robust and good-transferring highlevel semantic feature, which can be learned from the lipreading task. However, the existing method pre-trains the lip feature extraction model in a supervised manner, which requires plenty of human resources in data annotation and increases the difficulty of obtaining training data. In this paper, we propose a self-supervised transformer based audio-visual contrastive learning method. The proposed method learns mouth motion representations by encouraging the paired video and audio representations to be close while unpaired ones to be diverse. After pre-training with our method, the model will then be partially fine-tuned for deepfake detection task. Extensive experiments show that our self-supervised method performs comparably or even better than the supervised pre-training counterpart.
Intelligent Online Selling Point Extraction for E-Commerce Recommendation
Dec 16, 2021


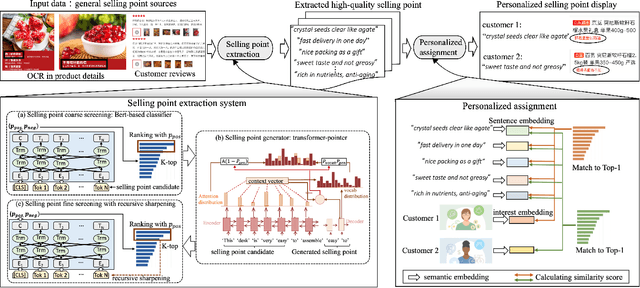
In the past decade, automatic product description generation for e-commerce have witnessed significant advancement. As the services provided by e-commerce platforms become diverse, it is necessary to dynamically adapt the patterns of descriptions generated. The selling point of products is an important type of product description for which the length should be as short as possible while still conveying key information. In addition, this kind of product description should be eye-catching to the readers. Currently, product selling points are normally written by human experts. Thus, the creation and maintenance of these contents incur high costs. These costs can be significantly reduced if product selling points can be automatically generated by machines. In this paper, we report our experience developing and deploying the Intelligent Online Selling Point Extraction (IOSPE) system to serve the recommendation system in the JD.com e-commerce platform. Since July 2020, IOSPE has become a core service for 62 key categories of products (covering more than 4 million products). So far, it has generated more than 0.1 billion selling points, thereby significantly scaling up the selling point creation operation and saving human labour. These IOSPE generated selling points have increased the click-through rate (CTR) by 1.89\% and the average duration the customers spent on the products by more than 2.03\% compared to the previous practice, which are significant improvements for such a large-scale e-commerce platform.
Multi-attentional Deepfake Detection
Mar 08, 2021
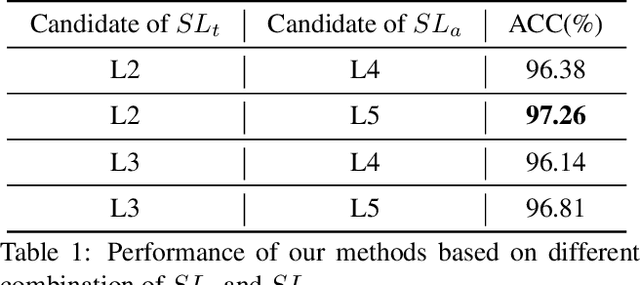
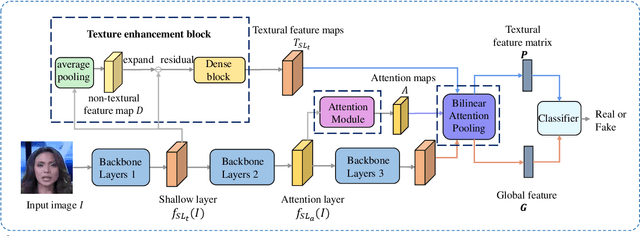
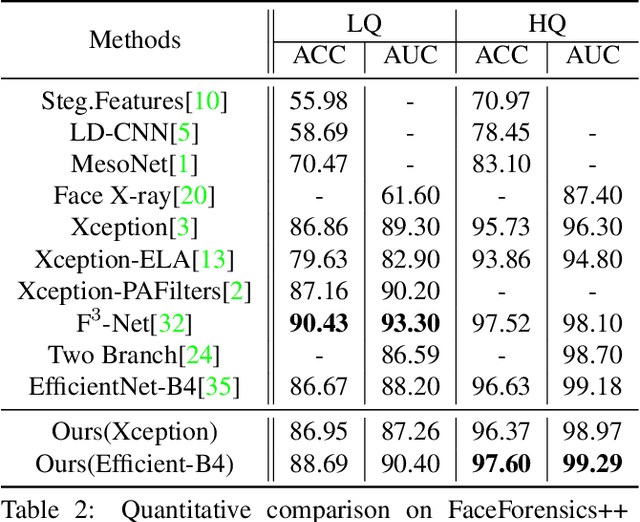
Face forgery by deepfake is widely spread over the internet and has raised severe societal concerns. Recently, how to detect such forgery contents has become a hot research topic and many deepfake detection methods have been proposed. Most of them model deepfake detection as a vanilla binary classification problem, i.e, first use a backbone network to extract a global feature and then feed it into a binary classifier (real/fake). But since the difference between the real and fake images in this task is often subtle and local, we argue this vanilla solution is not optimal. In this paper, we instead formulate deepfake detection as a fine-grained classification problem and propose a new multi-attentional deepfake detection network. Specifically, it consists of three key components: 1) multiple spatial attention heads to make the network attend to different local parts; 2) textural feature enhancement block to zoom in the subtle artifacts in shallow features; 3) aggregate the low-level textural feature and high-level semantic features guided by the attention maps. Moreover, to address the learning difficulty of this network, we further introduce a new regional independence loss and an attention guided data augmentation strategy. Through extensive experiments on different datasets, we demonstrate the superiority of our method over the vanilla binary classifier counterparts, and achieve state-of-the-art performance.
Improved Image Matting via Real-time User Clicks and Uncertainty Estimation
Dec 15, 2020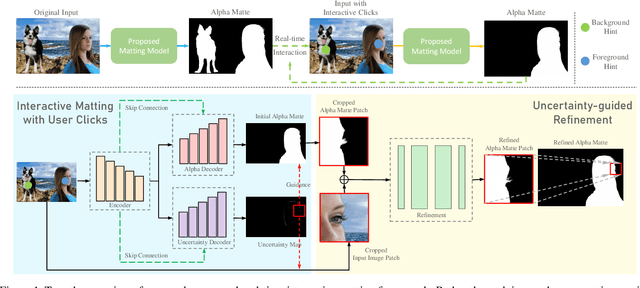
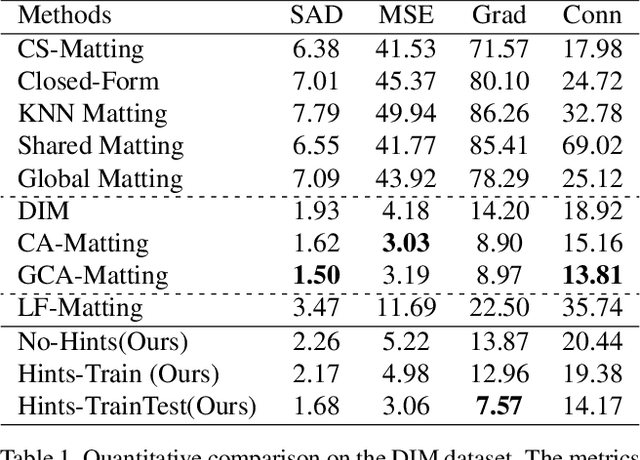

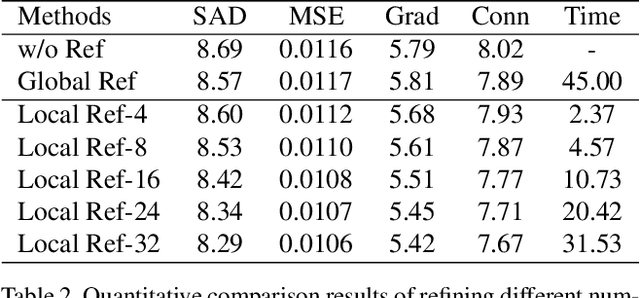
Image matting is a fundamental and challenging problem in computer vision and graphics. Most existing matting methods leverage a user-supplied trimap as an auxiliary input to produce good alpha matte. However, obtaining high-quality trimap itself is arduous, thus restricting the application of these methods. Recently, some trimap-free methods have emerged, however, the matting quality is still far behind the trimap-based methods. The main reason is that, without the trimap guidance in some cases, the target network is ambiguous about which is the foreground target. In fact, choosing the foreground is a subjective procedure and depends on the user's intention. To this end, this paper proposes an improved deep image matting framework which is trimap-free and only needs several user click interactions to eliminate the ambiguity. Moreover, we introduce a new uncertainty estimation module that can predict which parts need polishing and a following local refinement module. Based on the computation budget, users can choose how many local parts to improve with the uncertainty guidance. Quantitative and qualitative results show that our method performs better than existing trimap-free methods and comparably to state-of-the-art trimap-based methods with minimal user effort.
An $O(N)$ Sorting Algorithm: Machine Learning Sort
Aug 15, 2018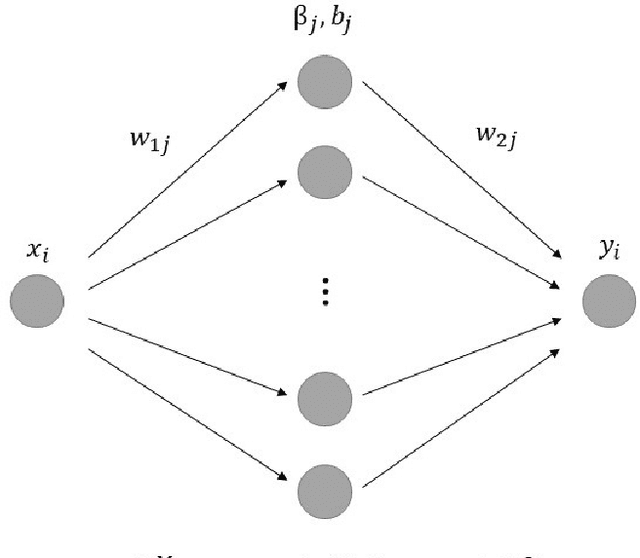

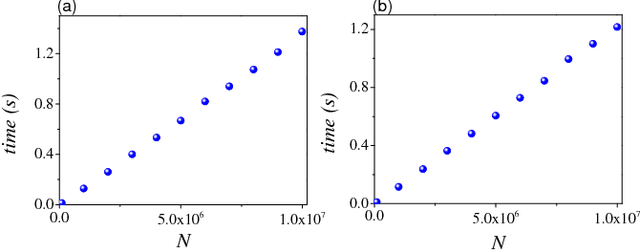
We propose an $O(N\cdot M)$ sorting algorithm by Machine Learning method, which shows a huge potential sorting big data. This sorting algorithm can be applied to parallel sorting and is suitable for GPU or TPU acceleration. Furthermore, we discuss the application of this algorithm to sparse hash table.