 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHao Xin
Multi-level Multiple Instance Learning with Transformer for Whole Slide Image Classification
Jun 08, 2023
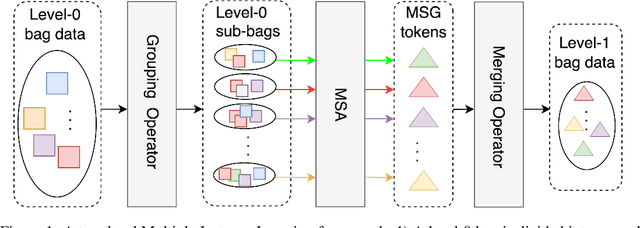
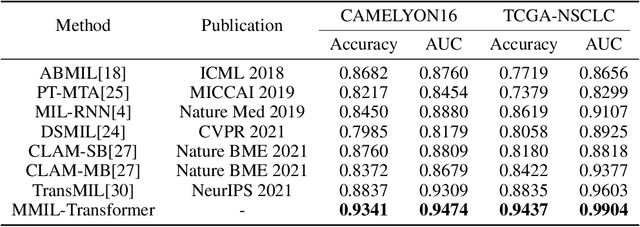
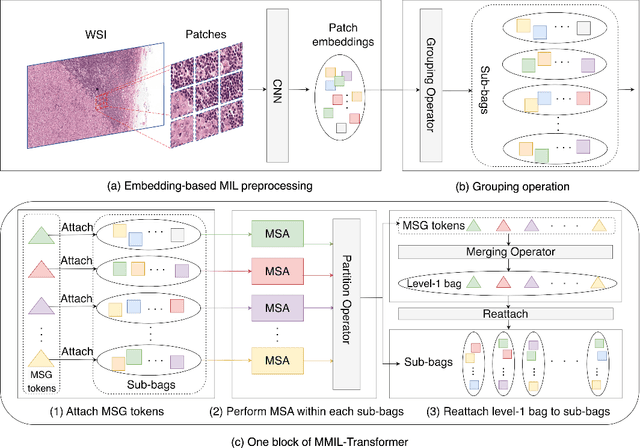
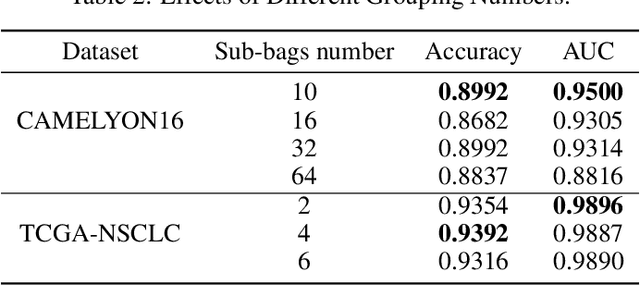
Whole slide image (WSI) refers to a type of high-resolution scanned tissue image, which is extensively employed in computer-assisted diagnosis (CAD). The extremely high resolution and limited availability of region-level annotations make it challenging to employ deep learning methods for WSI-based digital diagnosis. Multiple instance learning (MIL) is a powerful tool to address the weak annotation problem, while Transformer has shown great success in the field of visual tasks. The combination of both should provide new insights for deep learning based image diagnosis. However, due to the limitations of single-level MIL and the attention mechanism's constraints on sequence length, directly applying Transformer to WSI-based MIL tasks is not practical. To tackle this issue, we propose a Multi-level MIL with Transformer (MMIL-Transformer) approach. By introducing a hierarchical structure to MIL, this approach enables efficient handling of MIL tasks that involve a large number of instances. To validate its effectiveness, we conducted a set of experiments on WSIs classification task, where MMIL-Transformer demonstrate superior performance compared to existing state-of-the-art methods. Our proposed approach achieves test AUC 94.74% and test accuracy 93.41% on CAMELYON16 dataset, test AUC 99.04% and test accuracy 94.37% on TCGA-NSCLC dataset, respectively. All code and pre-trained models are available at: https://github.com/hustvl/MMIL-Transformer
WeakTr: Exploring Plain Vision Transformer for Weakly-supervised Semantic Segmentation
Apr 27, 2023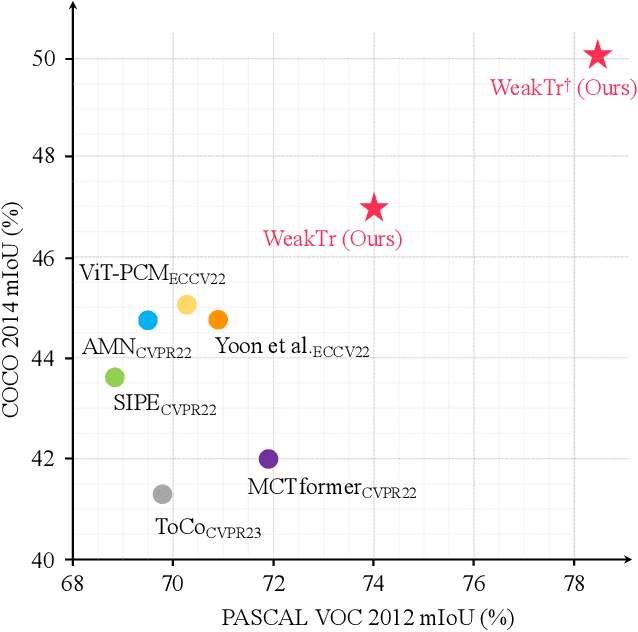
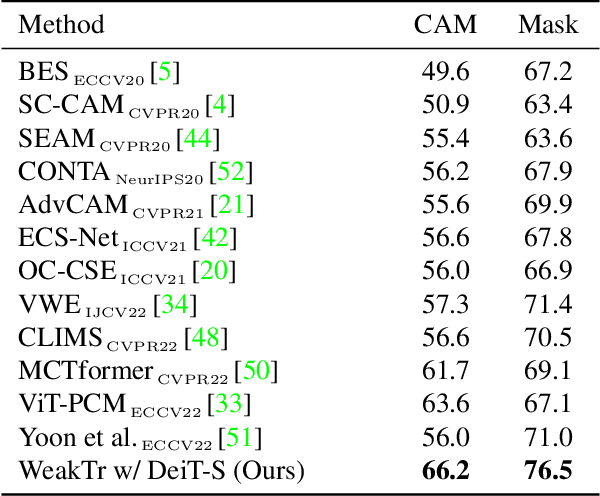
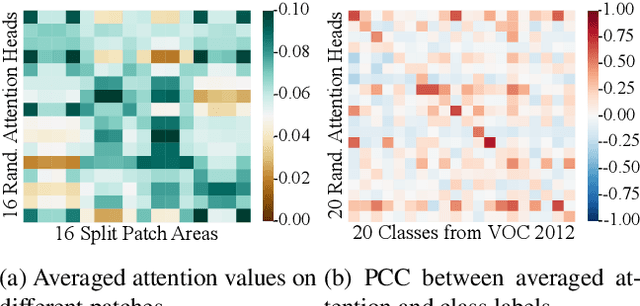

This paper explores the properties of the plain Vision Transformer (ViT) for Weakly-supervised Semantic Segmentation (WSSS). The class activation map (CAM) is of critical importance for understanding a classification network and launching WSSS. We observe that different attention heads of ViT focus on different image areas. Thus a novel weight-based method is proposed to end-to-end estimate the importance of attention heads, while the self-attention maps are adaptively fused for high-quality CAM results that tend to have more complete objects. Besides, we propose a ViT-based gradient clipping decoder for online retraining with the CAM results to complete the WSSS task. We name this plain Transformer-based Weakly-supervised learning framework WeakTr. It achieves the state-of-the-art WSSS performance on standard benchmarks, i.e., 78.4% mIoU on the val set of PASCAL VOC 2012 and 50.3% mIoU on the val set of COCO 2014. Code is available at https://github.com/hustvl/WeakTr.
Attacking and Defending Machine Learning Applications of Public Cloud
Jul 27, 2020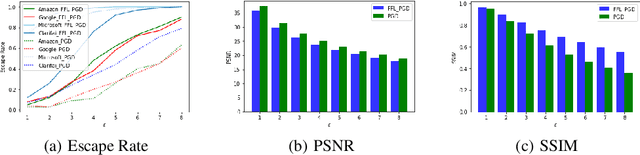


Adversarial attack breaks the boundaries of traditional security defense. For adversarial attack and the characteristics of cloud services, we propose Security Development Lifecycle for Machine Learning applications, e.g., SDL for ML. The SDL for ML helps developers build more secure software by reducing the number and severity of vulnerabilities in ML-as-a-service, while reducing development cost.
Advbox: a toolbox to generate adversarial examples that fool neural networks
Feb 21, 2020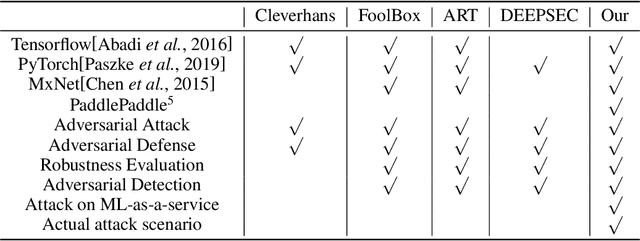



In recent years, neural networks have been extensively deployed for computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance. Recent studies have shown that they are all vulnerable to the attack of adversarial examples. Small and often imperceptible perturbations to the input images are sufficient to fool the most powerful neural networks. \emph{Advbox} is a toolbox to generate adversarial examples that fool neural networks in PaddlePaddle, PyTorch, Caffe2, MxNet, Keras, TensorFlow and it can benchmark the robustness of machine learning models. Compared to previous work, our platform supports black box attacks on Machine-Learning-as-a-service, as well as more attack scenarios, such as Face Recognition Attack, Stealth T-shirt, and DeepFake Face Detect. The code is licensed under the Apache 2.0 and is openly available at https://github.com/advboxes/AdvBox. Advbox now supports Python 3.
Subjective Knowledge Acquisition and Enrichment Powered By Crowdsourcing
May 16, 2017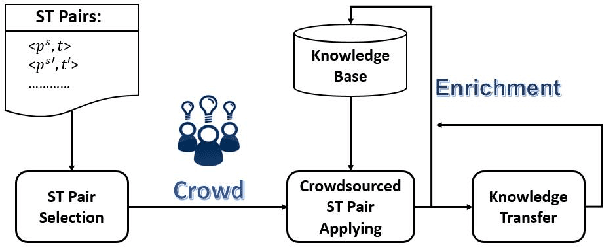
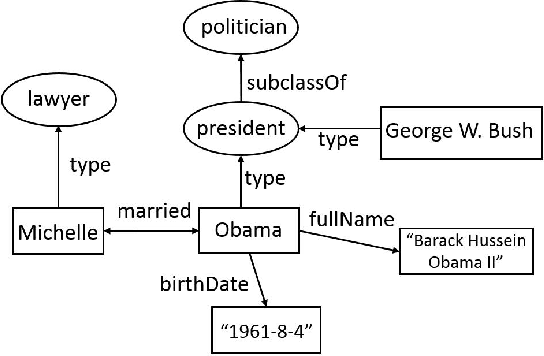

Knowledge bases (KBs) have attracted increasing attention due to its great success in various areas, such as Web and mobile search.Existing KBs are restricted to objective factual knowledge, such as city population or fruit shape, whereas,subjective knowledge, such as big city, which is commonly mentioned in Web and mobile queries, has been neglected. Subjective knowledge differs from objective knowledge in that it has no documented or observed ground truth. Instead, the truth relies on people's dominant opinion. Thus, we can use the crowdsourcing technique to get opinion from the crowd. In our work, we propose a system, called crowdsourced subjective knowledge acquisition (CoSKA),for subjective knowledge acquisition powered by crowdsourcing and existing KBs. The acquired knowledge can be used to enrich existing KBs in the subjective dimension which bridges the gap between existing objective knowledge and subjective queries.The main challenge of CoSKA is the conflict between large scale knowledge facts and limited crowdsourcing resource. To address this challenge, in this work, we define knowledge inference rules and then select the seed knowledge judiciously for crowdsourcing to maximize the inference power under the resource constraint. Our experimental results on real knowledge base and crowdsourcing platform verify the effectiveness of CoSKA system.