 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoruo Peng
Solving Hard Coreference Problems
Jul 11, 2019
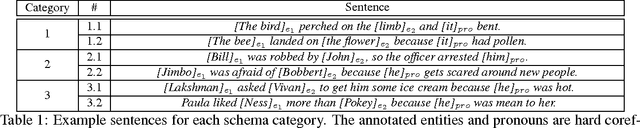


Coreference resolution is a key problem in natural language understanding that still escapes reliable solutions. One fundamental difficulty has been that of resolving instances involving pronouns since they often require deep language understanding and use of background knowledge. In this paper, we propose an algorithmic solution that involves a new representation for the knowledge required to address hard coreference problems, along with a constrained optimization framework that uses this knowledge in coreference decision making. Our representation, Predicate Schemas, is instantiated with knowledge acquired in an unsupervised way, and is compiled automatically into constraints that impact the coreference decision. We present a general coreference resolution system that significantly improves state-of-the-art performance on hard, Winograd-style, pronoun resolution cases, while still performing at the state-of-the-art level on standard coreference resolution datasets.
CogCompTime: A Tool for Understanding Time in Natural Language Text
Jun 12, 2019
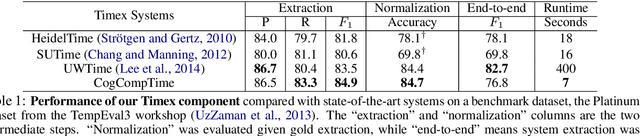
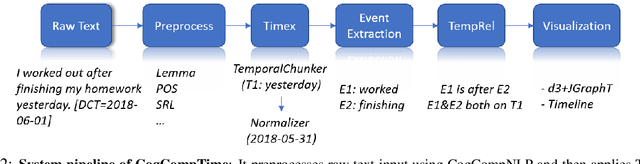
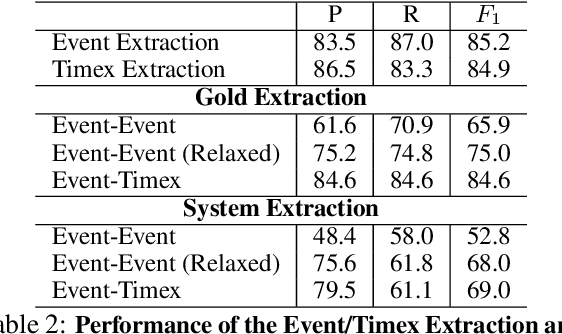
Automatic extraction of temporal information in text is an important component of natural language understanding. It involves two basic tasks: (1) Understanding time expressions that are mentioned explicitly in text (e.g., February 27, 1998 or tomorrow), and (2) Understanding temporal information that is conveyed implicitly via relations. In this paper, we introduce CogCompTime, a system that has these two important functionalities. It incorporates the most recent progress, achieves state-of-the-art performance, and is publicly available.1 We believe that this demo will be useful for multiple time-aware applications and provide valuable insight for future research in temporal understanding.
Improving Temporal Relation Extraction with a Globally Acquired Statistical Resource
Apr 17, 2018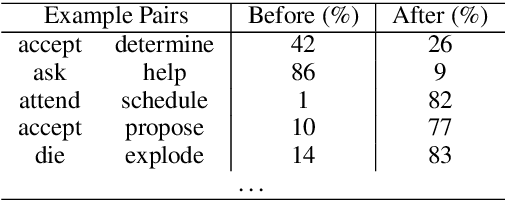
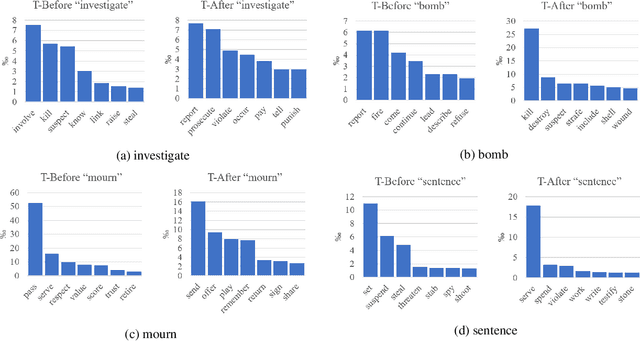
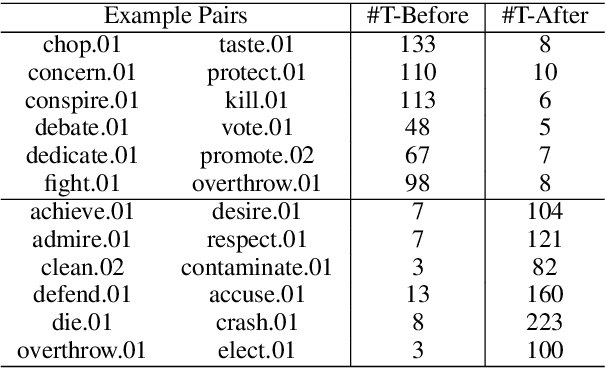
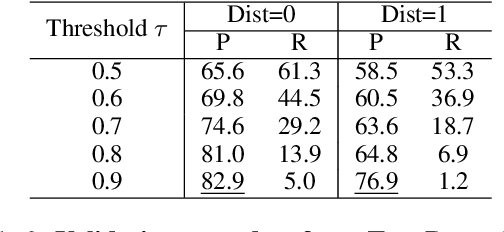
Extracting temporal relations (before, after, overlapping, etc.) is a key aspect of understanding events described in natural language. We argue that this task would gain from the availability of a resource that provides prior knowledge in the form of the temporal order that events usually follow. This paper develops such a resource -- a probabilistic knowledge base acquired in the news domain -- by extracting temporal relations between events from the New York Times (NYT) articles over a 20-year span (1987--2007). We show that existing temporal extraction systems can be improved via this resource. As a byproduct, we also show that interesting statistics can be retrieved from this resource, which can potentially benefit other time-aware tasks. The proposed system and resource are both publicly available.
Two Discourse Driven Language Models for Semantics
Jun 27, 2016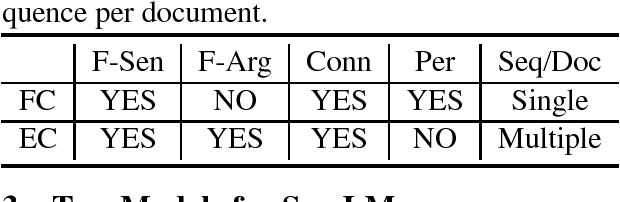
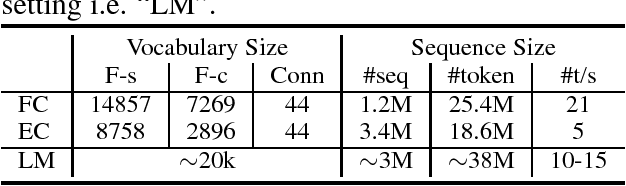
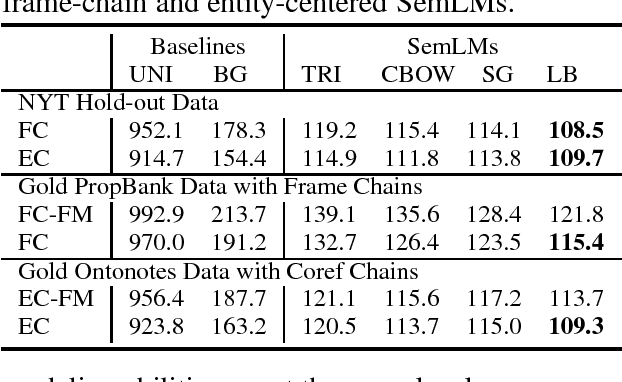
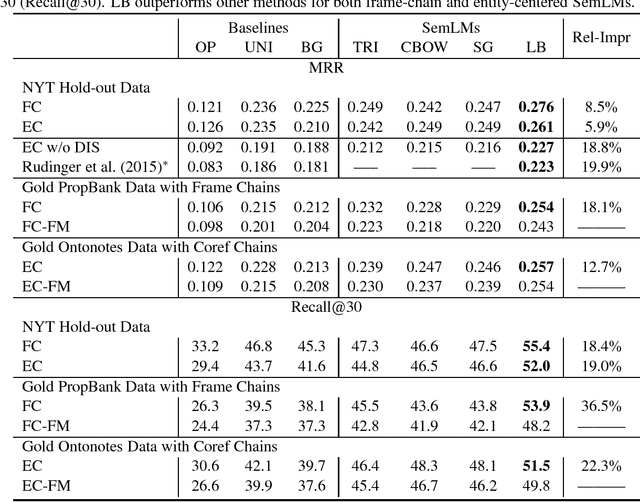
Natural language understanding often requires deep semantic knowledge. Expanding on previous proposals, we suggest that some important aspects of semantic knowledge can be modeled as a language model if done at an appropriate level of abstraction. We develop two distinct models that capture semantic frame chains and discourse information while abstracting over the specific mentions of predicates and entities. For each model, we investigate four implementations: a "standard" N-gram language model and three discriminatively trained "neural" language models that generate embeddings for semantic frames. The quality of the semantic language models (SemLM) is evaluated both intrinsically, using perplexity and a narrative cloze test and extrinsically - we show that our SemLM helps improve performance on semantic natural language processing tasks such as co-reference resolution and discourse parsing.