 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHassan Taherian
Multi-channel Conversational Speaker Separation via Neural Diarization
Nov 15, 2023
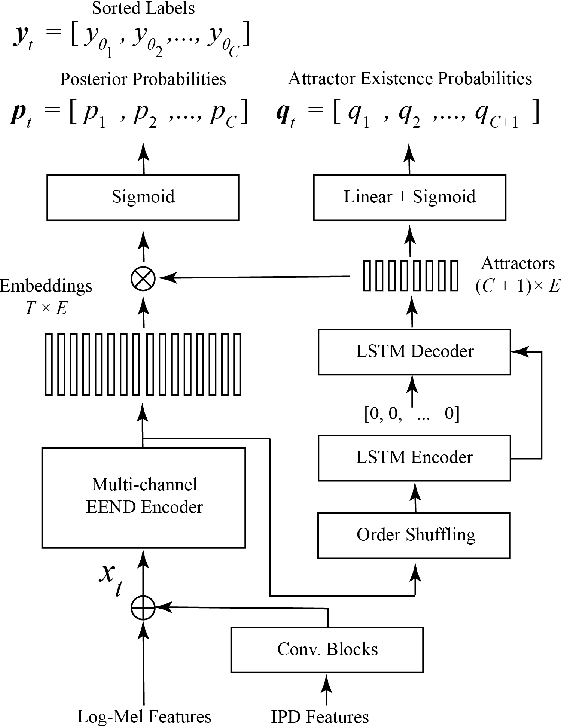
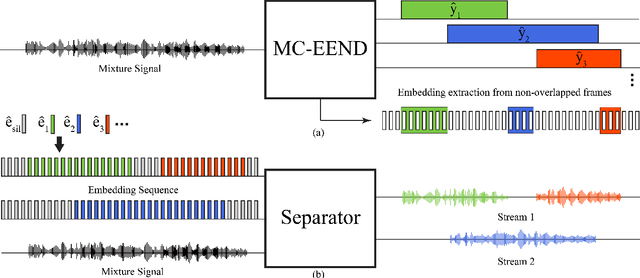
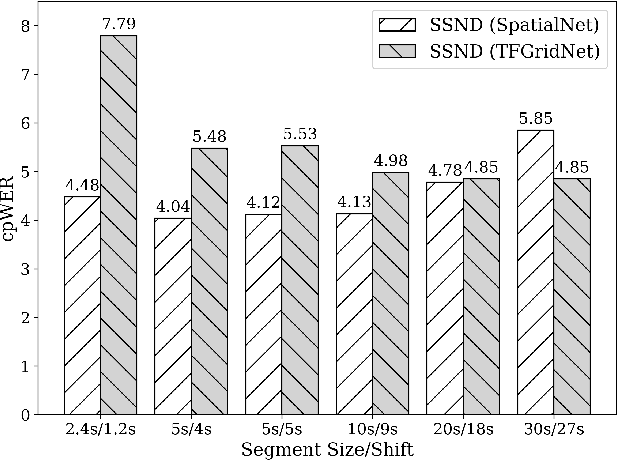
When dealing with overlapped speech, the performance of automatic speech recognition (ASR) systems substantially degrades as they are designed for single-talker speech. To enhance ASR performance in conversational or meeting environments, continuous speaker separation (CSS) is commonly employed. However, CSS requires a short separation window to avoid many speakers inside the window and sequential grouping of discontinuous speech segments. To address these limitations, we introduce a new multi-channel framework called "speaker separation via neural diarization" (SSND) for meeting environments. Our approach utilizes an end-to-end diarization system to identify the speech activity of each individual speaker. By leveraging estimated speaker boundaries, we generate a sequence of embeddings, which in turn facilitate the assignment of speakers to the outputs of a multi-talker separation model. SSND addresses the permutation ambiguity issue of talker-independent speaker separation during the diarization phase through location-based training, rather than during the separation process. This unique approach allows multiple non-overlapped speakers to be assigned to the same output stream, making it possible to efficiently process long segments-a task impossible with CSS. Additionally, SSND is naturally suitable for speaker-attributed ASR. We evaluate our proposed diarization and separation methods on the open LibriCSS dataset, advancing state-of-the-art diarization and ASR results by a large margin.
Multi-resolution location-based training for multi-channel continuous speech separation
Jan 16, 2023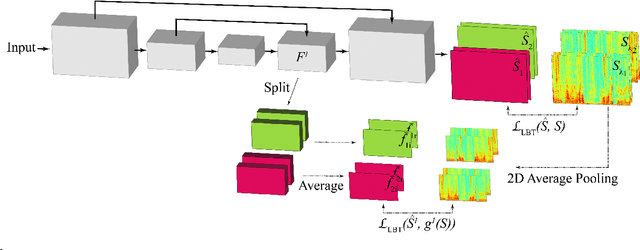
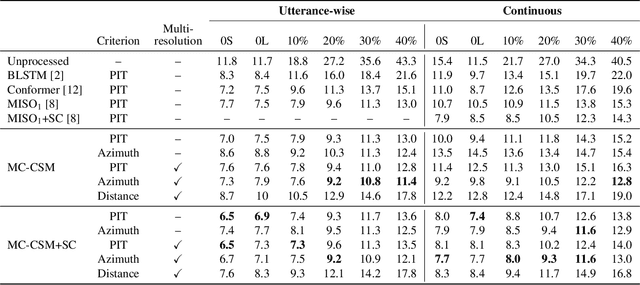
The performance of automatic speech recognition (ASR) systems severely degrades when multi-talker speech overlap occurs. In meeting environments, speech separation is typically performed to improve the robustness of ASR systems. Recently, location-based training (LBT) was proposed as a new training criterion for multi-channel talker-independent speaker separation. Assuming fixed array geometry, LBT outperforms widely-used permutation-invariant training in fully overlapped utterances and matched reverberant conditions. This paper extends LBT to conversational multi-channel speaker separation. We introduce multi-resolution LBT to estimate the complex spectrograms from low to high time and frequency resolutions. With multi-resolution LBT, convolutional kernels are assigned consistently based on speaker locations in physical space. Evaluation results show that multi-resolution LBT consistently outperforms other competitive methods on the recorded LibriCSS corpus.
Breaking the trade-off in personalized speech enhancement with cross-task knowledge distillation
Nov 05, 2022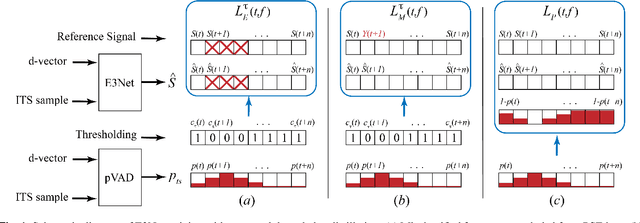
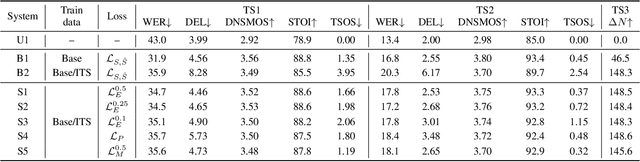

Personalized speech enhancement (PSE) models achieve promising results compared with unconditional speech enhancement models due to their ability to remove interfering speech in addition to background noise. Unlike unconditional speech enhancement, causal PSE models may occasionally remove the target speech by mistake. The PSE models also tend to leak interfering speech when the target speaker is silent for an extended period. We show that existing PSE methods suffer from a trade-off between speech over-suppression and interference leakage by addressing one problem at the expense of the other. We propose a new PSE model training framework using cross-task knowledge distillation to mitigate this trade-off. Specifically, we utilize a personalized voice activity detector (pVAD) during training to exclude the non-target speech frames that are wrongly identified as containing the target speaker with hard or soft classification. This prevents the PSE model from being too aggressive while still allowing the model to learn to suppress the input speech when it is likely to be spoken by interfering speakers. Comprehensive evaluation results are presented, covering various PSE usage scenarios.
One model to enhance them all: array geometry agnostic multi-channel personalized speech enhancement
Oct 20, 2021



With the recent surge of video conferencing tools usage, providing high-quality speech signals and accurate captions have become essential to conduct day-to-day business or connect with friends and families. Single-channel personalized speech enhancement (PSE) methods show promising results compared with the unconditional speech enhancement (SE) methods in these scenarios due to their ability to remove interfering speech in addition to the environmental noise. In this work, we leverage spatial information afforded by microphone arrays to improve such systems' performance further. We investigate the relative importance of speaker embeddings and spatial features. Moreover, we propose a new causal array-geometry-agnostic multi-channel PSE model, which can generate a high-quality enhanced signal from arbitrary microphone geometry. Experimental results show that the proposed geometry agnostic model outperforms the model trained on a specific microphone array geometry in both speech quality and automatic speech recognition accuracy. We also demonstrate the effectiveness of the proposed approach for unseen array geometries.
Location-based training for multi-channel talker-independent speaker separation
Oct 08, 2021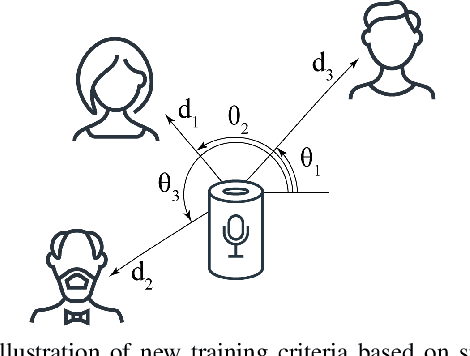
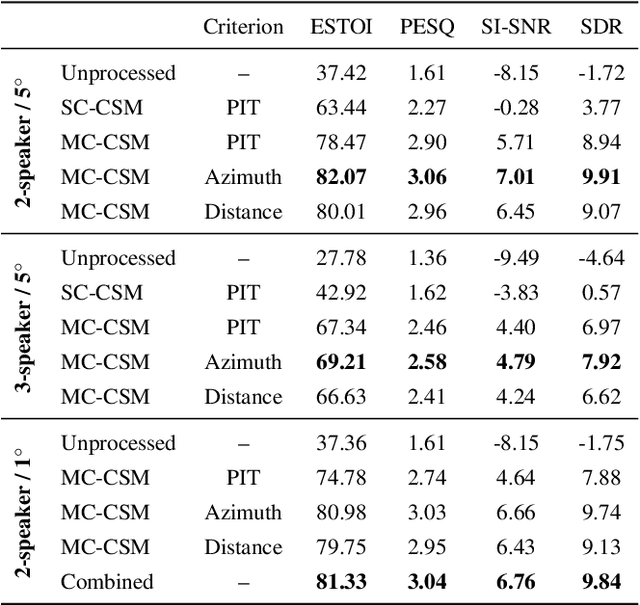
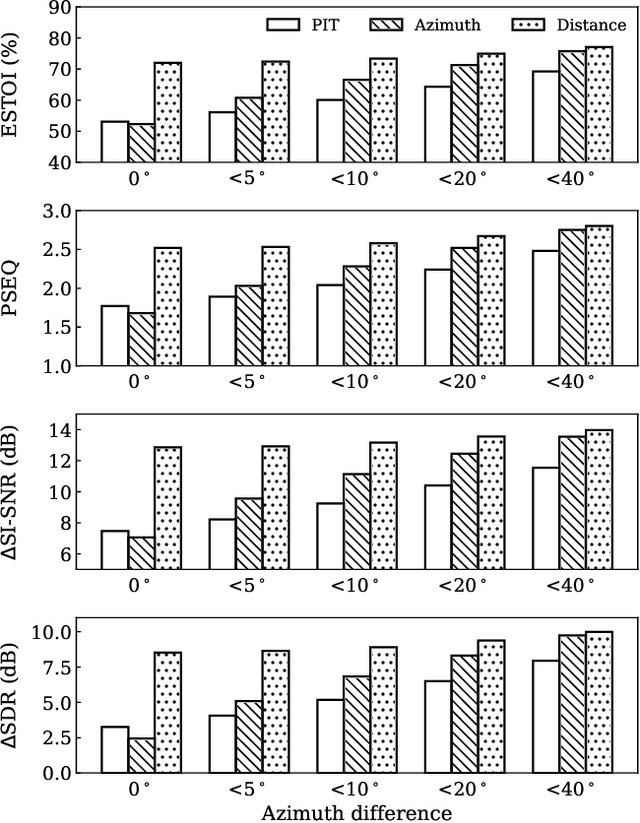
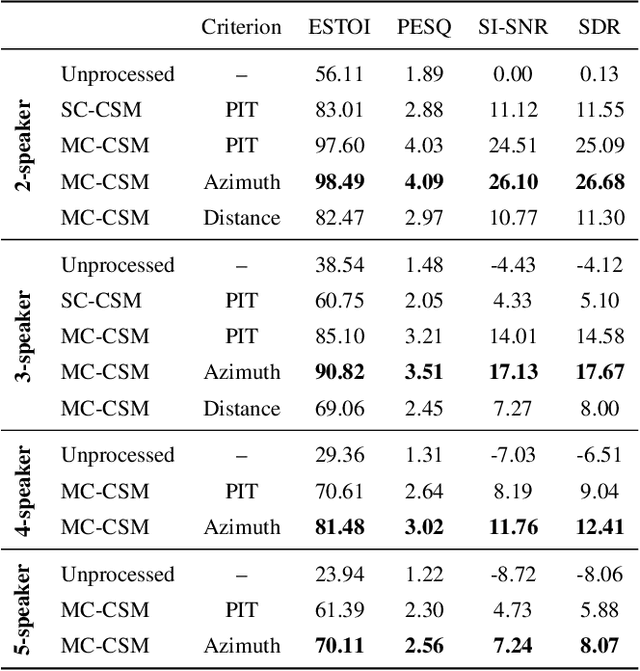
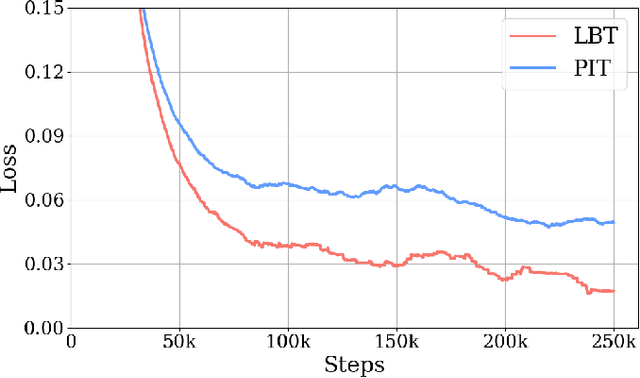
Permutation-invariant training (PIT) is a dominant approach for addressing the permutation ambiguity problem in talker-independent speaker separation. Leveraging spatial information afforded by microphone arrays, we propose a new training approach to resolving permutation ambiguities for multi-channel speaker separation. The proposed approach, named location-based training (LBT), assigns speakers on the basis of their spatial locations. This training strategy is easy to apply, and organizes speakers according to their positions in physical space. Specifically, this study investigates azimuth angles and source distances for location-based training. Evaluation results on separating two- and three-speaker mixtures show that azimuth-based training consistently outperforms PIT, and distance-based training further improves the separation performance when speaker azimuths are close. Furthermore, we dynamically select azimuth-based or distance-based training by estimating the azimuths of separated speakers, which further improves separation performance. LBT has a linear training complexity with respect to the number of speakers, as opposed to the factorial complexity of PIT. We further demonstrate the effectiveness of LBT for the separation of four and five concurrent speakers.
End-to-end attention-based distant speech recognition with Highway LSTM
Oct 17, 2016

End-to-end attention-based models have been shown to be competitive alternatives to conventional DNN-HMM models in the Speech Recognition Systems. In this paper, we extend existing end-to-end attention-based models that can be applied for Distant Speech Recognition (DSR) task. Specifically, we propose an end-to-end attention-based speech recognizer with multichannel input that performs sequence prediction directly at the character level. To gain a better performance, we also incorporate Highway long short-term memory (HLSTM) which outperforms previous models on AMI distant speech recognition task.