 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHe Lyu
Implicit regularization in Heavy-ball momentum accelerated stochastic gradient descent
Feb 02, 2023
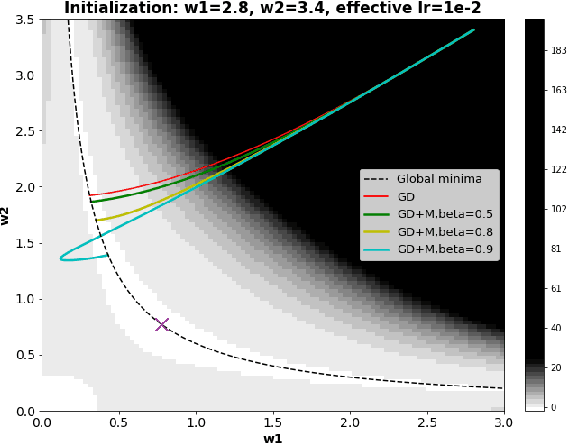
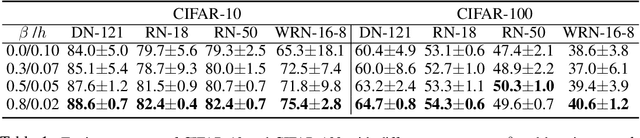

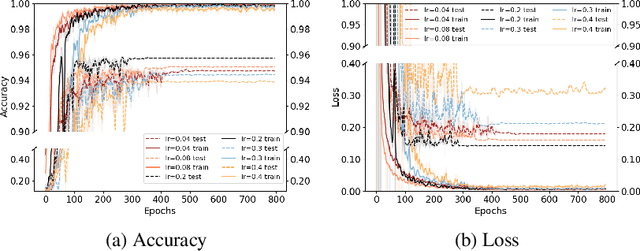
It is well known that the finite step-size ($h$) in Gradient Descent (GD) implicitly regularizes solutions to flatter minima. A natural question to ask is "Does the momentum parameter $\beta$ play a role in implicit regularization in Heavy-ball (H.B) momentum accelerated gradient descent (GD+M)?". To answer this question, first, we show that the discrete H.B momentum update (GD+M) follows a continuous trajectory induced by a modified loss, which consists of an original loss and an implicit regularizer. Then, we show that this implicit regularizer for (GD+M) is stronger than that of (GD) by factor of $(\frac{1+\beta}{1-\beta})$, thus explaining why (GD+M) shows better generalization performance and higher test accuracy than (GD). Furthermore, we extend our analysis to the stochastic version of gradient descent with momentum (SGD+M) and characterize the continuous trajectory of the update of (SGD+M) in a pointwise sense. We explore the implicit regularization in (SGD+M) and (GD+M) through a series of experiments validating our theory.
Manifold Denoising by Nonlinear Robust Principal Component Analysis
Nov 10, 2019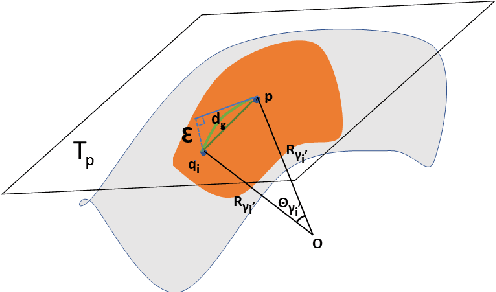
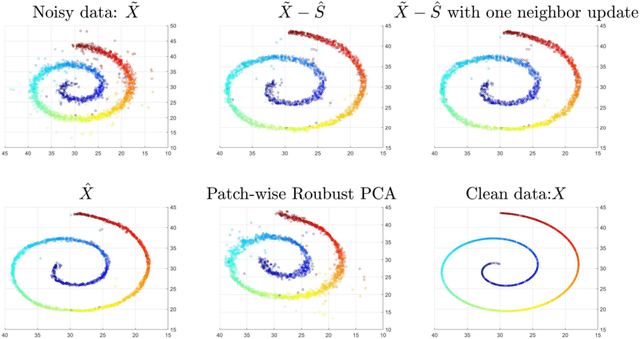
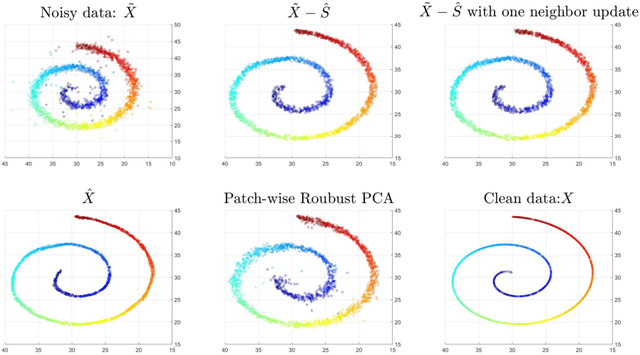
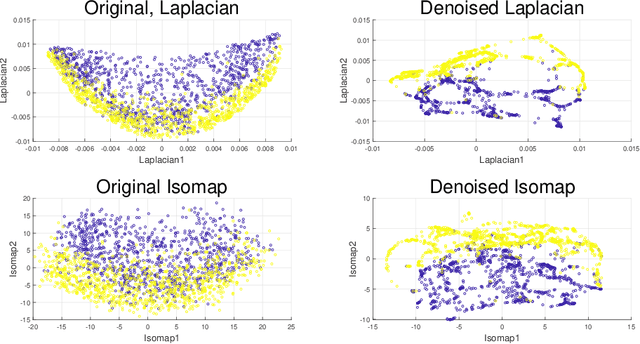
This paper extends robust principal component analysis (RPCA) to nonlinear manifolds. Suppose that the observed data matrix is the sum of a sparse component and a component drawn from some low dimensional manifold. Is it possible to separate them by using similar ideas as RPCA? Is there any benefit in treating the manifold as a whole as opposed to treating each local region independently? We answer these two questions affirmatively by proposing and analyzing an optimization framework that separates the sparse component from the manifold under noisy data. Theoretical error bounds are provided when the tangent spaces of the manifold satisfy certain incoherence conditions. We also provide a near optimal choice of the tuning parameters for the proposed optimization formulation with the help of a new curvature estimation method. The efficacy of our method is demonstrated on both synthetic and real datasets.