 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeming Du
Affective Behaviour Analysis via Integrating Multi-Modal Knowledge
Mar 16, 2024
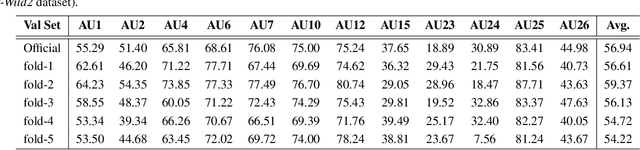

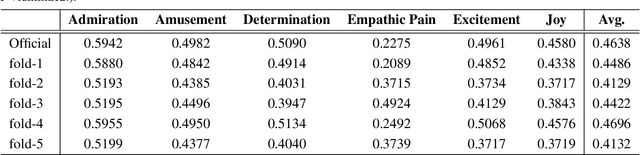
Affective Behavior Analysis aims to facilitate technology emotionally smart, creating a world where devices can understand and react to our emotions as humans do. To comprehensively evaluate the authenticity and applicability of emotional behavior analysis techniques in natural environments, the 6th competition on Affective Behavior Analysis in-the-wild (ABAW) utilizes the Aff-Wild2, Hume-Vidmimic2, and C-EXPR-DB datasets to set up five competitive tracks, i.e., Valence-Arousal (VA) Estimation, Expression (EXPR) Recognition, Action Unit (AU) Detection, Compound Expression (CE) Recognition, and Emotional Mimicry Intensity (EMI) Estimation. In this paper, we present our method designs for the five tasks. Specifically, our design mainly includes three aspects: 1) Utilizing a transformer-based feature fusion module to fully integrate emotional information provided by audio signals, visual images, and transcripts, offering high-quality expression features for the downstream tasks. 2) To achieve high-quality facial feature representations, we employ Masked-Auto Encoder as the visual features extraction model and fine-tune it with our facial dataset. 3) Considering the complexity of the video collection scenes, we conduct a more detailed dataset division based on scene characteristics and train the classifier for each scene. Extensive experiments demonstrate the superiority of our designs.
Divide and Ensemble: Progressively Learning for the Unknown
Oct 09, 2023
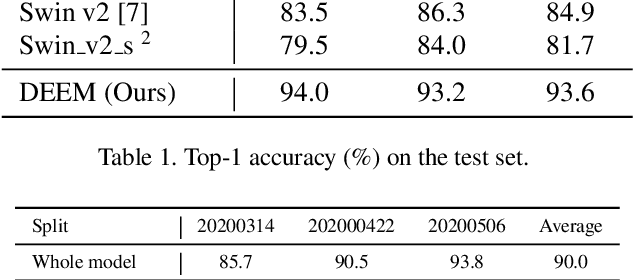
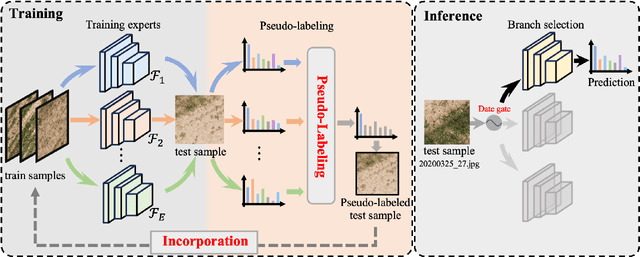

In the wheat nutrient deficiencies classification challenge, we present the DividE and EnseMble (DEEM) method for progressive test data predictions. We find that (1) test images are provided in the challenge; (2) samples are equipped with their collection dates; (3) the samples of different dates show notable discrepancies. Based on the findings, we partition the dataset into discrete groups by the dates and train models on each divided group. We then adopt the pseudo-labeling approach to label the test data and incorporate those with high confidence into the training set. In pseudo-labeling, we leverage models ensemble with different architectures to enhance the reliability of predictions. The pseudo-labeling and ensembled model training are iteratively conducted until all test samples are labeled. Finally, the separated models for each group are unified to obtain the model for the whole dataset. Our method achieves an average of 93.6\% Top-1 test accuracy~(94.0\% on WW2020 and 93.2\% on WR2021) and wins the 1$st$ place in the Deep Nutrient Deficiency Challenge~\footnote{https://cvppa2023.github.io/challenges/}.
When 3D Bounding-Box Meets SAM: Point Cloud Instance Segmentation with Weak-and-Noisy Supervision
Sep 02, 2023



Learning from bounding-boxes annotations has shown great potential in weakly-supervised 3D point cloud instance segmentation. However, we observed that existing methods would suffer severe performance degradation with perturbed bounding box annotations. To tackle this issue, we propose a complementary image prompt-induced weakly-supervised point cloud instance segmentation (CIP-WPIS) method. CIP-WPIS leverages pretrained knowledge embedded in the 2D foundation model SAM and 3D geometric prior to achieve accurate point-wise instance labels from the bounding box annotations. Specifically, CP-WPIS first selects image views in which 3D candidate points of an instance are fully visible. Then, we generate complementary background and foreground prompts from projections to obtain SAM 2D instance mask predictions. According to these, we assign the confidence values to points indicating the likelihood of points belonging to the instance. Furthermore, we utilize 3D geometric homogeneity provided by superpoints to decide the final instance label assignments. In this fashion, we achieve high-quality 3D point-wise instance labels. Extensive experiments on both Scannet-v2 and S3DIS benchmarks demonstrate that our method is robust against noisy 3D bounding-box annotations and achieves state-of-the-art performance.
RVD: A Handheld Device-Based Fundus Video Dataset for Retinal Vessel Segmentation
Jul 13, 2023Retinal vessel segmentation is generally grounded in image-based datasets collected with bench-top devices. The static images naturally lose the dynamic characteristics of retina fluctuation, resulting in diminished dataset richness, and the usage of bench-top devices further restricts dataset scalability due to its limited accessibility. Considering these limitations, we introduce the first video-based retinal dataset by employing handheld devices for data acquisition. The dataset comprises 635 smartphone-based fundus videos collected from four different clinics, involving 415 patients from 50 to 75 years old. It delivers comprehensive and precise annotations of retinal structures in both spatial and temporal dimensions, aiming to advance the landscape of vasculature segmentation. Specifically, the dataset provides three levels of spatial annotations: binary vessel masks for overall retinal structure delineation, general vein-artery masks for distinguishing the vein and artery, and fine-grained vein-artery masks for further characterizing the granularities of each artery and vein. In addition, the dataset offers temporal annotations that capture the vessel pulsation characteristics, assisting in detecting ocular diseases that require fine-grained recognition of hemodynamic fluctuation. In application, our dataset exhibits a significant domain shift with respect to data captured by bench-top devices, thus posing great challenges to existing methods. In the experiments, we provide evaluation metrics and benchmark results on our dataset, reflecting both the potential and challenges it offers for vessel segmentation tasks. We hope this challenging dataset would significantly contribute to the development of eye disease diagnosis and early prevention.
SEFormer: Structure Embedding Transformer for 3D Object Detection
Sep 05, 2022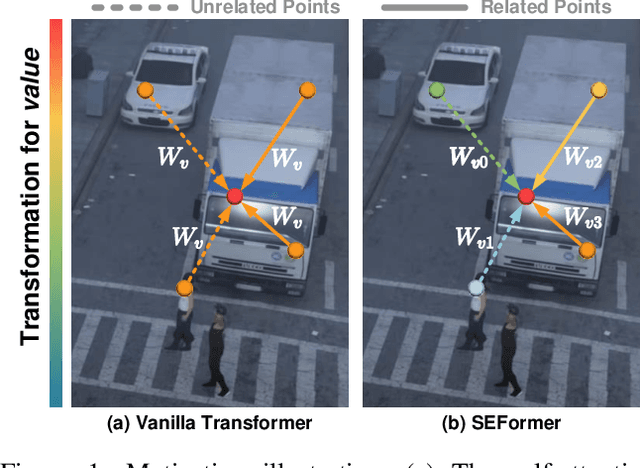
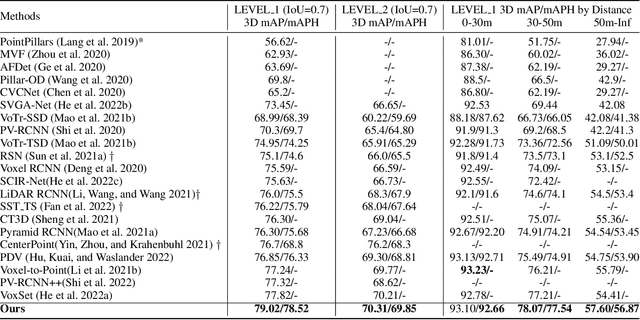
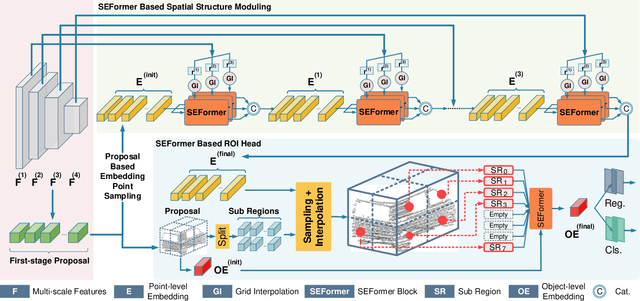

Effectively preserving and encoding structure features from objects in irregular and sparse LiDAR points is a key challenge to 3D object detection on point cloud. Recently, Transformer has demonstrated promising performance on many 2D and even 3D vision tasks. Compared with the fixed and rigid convolution kernels, the self-attention mechanism in Transformer can adaptively exclude the unrelated or noisy points and thus suitable for preserving the local spatial structure in irregular LiDAR point cloud. However, Transformer only performs a simple sum on the point features, based on the self-attention mechanism, and all the points share the same transformation for value. Such isotropic operation lacks the ability to capture the direction-distance-oriented local structure which is important for 3D object detection. In this work, we propose a Structure-Embedding transFormer (SEFormer), which can not only preserve local structure as traditional Transformer but also have the ability to encode the local structure. Compared to the self-attention mechanism in traditional Transformer, SEFormer learns different feature transformations for value points based on the relative directions and distances to the query point. Then we propose a SEFormer based network for high-performance 3D object detection. Extensive experiments show that the proposed architecture can achieve SOTA results on Waymo Open Dataset, the largest 3D detection benchmark for autonomous driving. Specifically, SEFormer achieves 79.02% mAP, which is 1.2% higher than existing works. We will release the codes.
VTNet: Visual Transformer Network for Object Goal Navigation
May 20, 2021



Object goal navigation aims to steer an agent towards a target object based on observations of the agent. It is of pivotal importance to design effective visual representations of the observed scene in determining navigation actions. In this paper, we introduce a Visual Transformer Network (VTNet) for learning informative visual representation in navigation. VTNet is a highly effective structure that embodies two key properties for visual representations: First, the relationships among all the object instances in a scene are exploited; Second, the spatial locations of objects and image regions are emphasized so that directional navigation signals can be learned. Furthermore, we also develop a pre-training scheme to associate the visual representations with navigation signals, and thus facilitate navigation policy learning. In a nutshell, VTNet embeds object and region features with their location cues as spatial-aware descriptors and then incorporates all the encoded descriptors through attention operations to achieve informative representation for navigation. Given such visual representations, agents are able to explore the correlations between visual observations and navigation actions. For example, an agent would prioritize "turning right" over "turning left" when the visual representation emphasizes on the right side of activation map. Experiments in the artificial environment AI2-Thor demonstrate that VTNet significantly outperforms state-of-the-art methods in unseen testing environments.
Learning Object Relation Graph and Tentative Policy for Visual Navigation
Jul 21, 2020



Target-driven visual navigation aims at navigating an agent towards a given target based on the observation of the agent. In this task, it is critical to learn informative visual representation and robust navigation policy. Aiming to improve these two components, this paper proposes three complementary techniques, object relation graph (ORG), trial-driven imitation learning (IL), and a memory-augmented tentative policy network (TPN). ORG improves visual representation learning by integrating object relationships, including category closeness and spatial correlations, e.g., a TV usually co-occurs with a remote spatially. Both Trial-driven IL and TPN underlie robust navigation policy, instructing the agent to escape from deadlock states, such as looping or being stuck. Specifically, trial-driven IL is a type of supervision used in policy network training, while TPN, mimicking the IL supervision in unseen environment, is applied in testing. Experiment in the artificial environment AI2-Thor validates that each of the techniques is effective. When combined, the techniques bring significantly improvement over baseline methods in navigation effectiveness and efficiency in unseen environments. We report 22.8% and 23.5% increase in success rate and Success weighted by Path Length (SPL), respectively. The code is available at https://github.com/xiaobaishu0097/ECCV-VN.git.