 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeming Sun
Attack and Defense Analysis of Learned Image Compression
Jan 18, 2024
Learned image compression (LIC) is becoming more and more popular these years with its high efficiency and outstanding compression quality. Still, the practicality against modified inputs added with specific noise could not be ignored. White-box attacks such as FGSM and PGD use only gradient to compute adversarial images that mislead LIC models to output unexpected results. Our experiments compare the effects of different dimensions such as attack methods, models, qualities, and targets, concluding that in the worst case, there is a 61.55% decrease in PSNR or a 19.15 times increase in bit rate under the PGD attack. To improve their robustness, we conduct adversarial training by adding adversarial images into the training datasets, which obtains a 95.52% decrease in the R-D cost of the most vulnerable LIC model. We further test the robustness of H.266, whose better performance on reconstruction quality extends its possibility to defend one-step or iterative adversarial attacks.
Accelerating Learnt Video Codecs with Gradient Decay and Layer-wise Distillation
Dec 05, 2023In recent years, end-to-end learnt video codecs have demonstrated their potential to compete with conventional coding algorithms in term of compression efficiency. However, most learning-based video compression models are associated with high computational complexity and latency, in particular at the decoder side, which limits their deployment in practical applications. In this paper, we present a novel model-agnostic pruning scheme based on gradient decay and adaptive layer-wise distillation. Gradient decay enhances parameter exploration during sparsification whilst preventing runaway sparsity and is superior to the standard Straight-Through Estimation. The adaptive layer-wise distillation regulates the sparse training in various stages based on the distortion of intermediate features. This stage-wise design efficiently updates parameters with minimal computational overhead. The proposed approach has been applied to three popular end-to-end learnt video codecs, FVC, DCVC, and DCVC-HEM. Results confirm that our method yields up to 65% reduction in MACs and 2x speed-up with less than 0.3dB drop in BD-PSNR. Supporting code and supplementary material can be downloaded from: https://jasminepp.github.io/lightweightdvc/
SCP: Spherical-Coordinate-based Learned Point Cloud Compression
Aug 24, 2023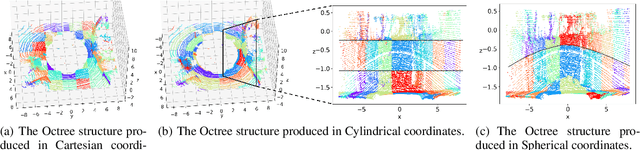
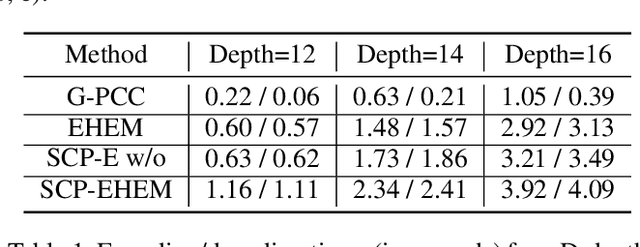
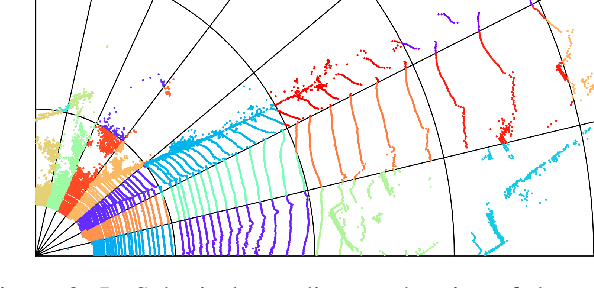

In recent years, the task of learned point cloud compression has gained prominence. An important type of point cloud, the spinning LiDAR point cloud, is generated by spinning LiDAR on vehicles. This process results in numerous circular shapes and azimuthal angle invariance features within the point clouds. However, these two features have been largely overlooked by previous methodologies. In this paper, we introduce a model-agnostic method called Spherical-Coordinate-based learned Point cloud compression (SCP), designed to leverage the aforementioned features fully. Additionally, we propose a multi-level Octree for SCP to mitigate the reconstruction error for distant areas within the Spherical-coordinate-based Octree. SCP exhibits excellent universality, making it applicable to various learned point cloud compression techniques. Experimental results demonstrate that SCP surpasses previous state-of-the-art methods by up to 29.14% in point-to-point PSNR BD-Rate.
Prompt-ICM: A Unified Framework towards Image Coding for Machines with Task-driven Prompts
May 04, 2023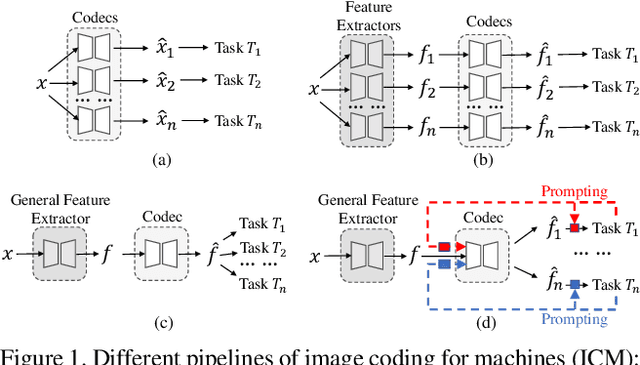
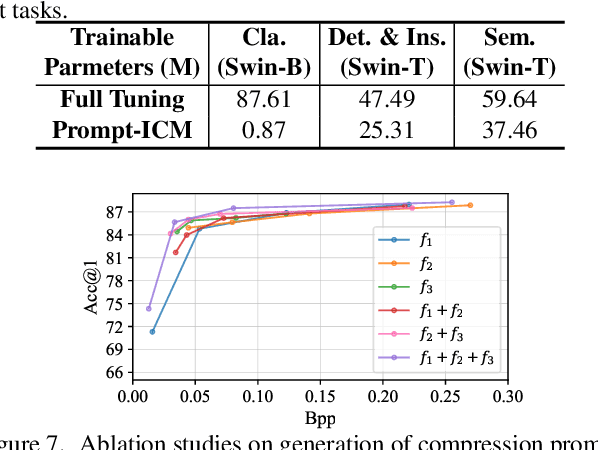
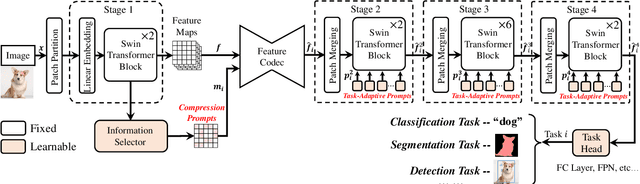
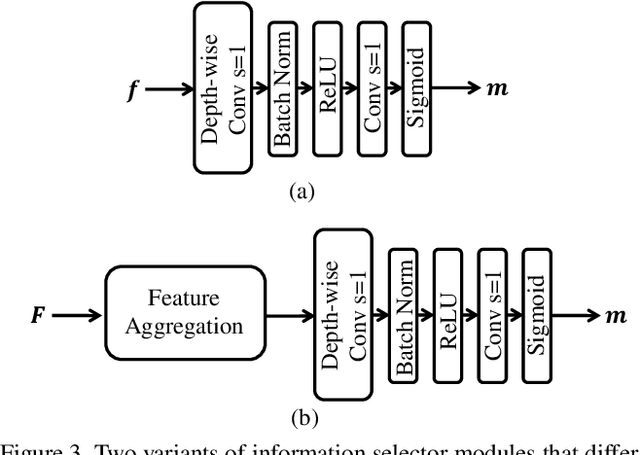
Image coding for machines (ICM) aims to compress images to support downstream AI analysis instead of human perception. For ICM, developing a unified codec to reduce information redundancy while empowering the compressed features to support various vision tasks is very important, which inevitably faces two core challenges: 1) How should the compression strategy be adjusted based on the downstream tasks? 2) How to well adapt the compressed features to different downstream tasks? Inspired by recent advances in transferring large-scale pre-trained models to downstream tasks via prompting, in this work, we explore a new ICM framework, termed Prompt-ICM. To address both challenges by carefully learning task-driven prompts to coordinate well the compression process and downstream analysis. Specifically, our method is composed of two core designs: a) compression prompts, which are implemented as importance maps predicted by an information selector, and used to achieve different content-weighted bit allocations during compression according to different downstream tasks; b) task-adaptive prompts, which are instantiated as a few learnable parameters specifically for tuning compressed features for the specific intelligent task. Extensive experiments demonstrate that with a single feature codec and a few extra parameters, our proposed framework could efficiently support different kinds of intelligent tasks with much higher coding efficiency.
Learned Image Compression with Mixed Transformer-CNN Architectures
Mar 27, 2023
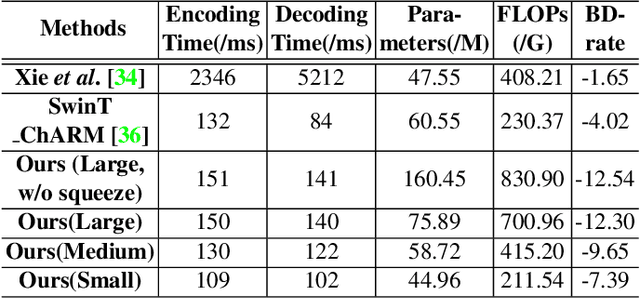
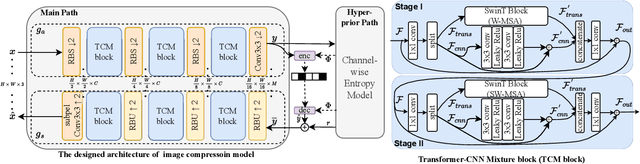
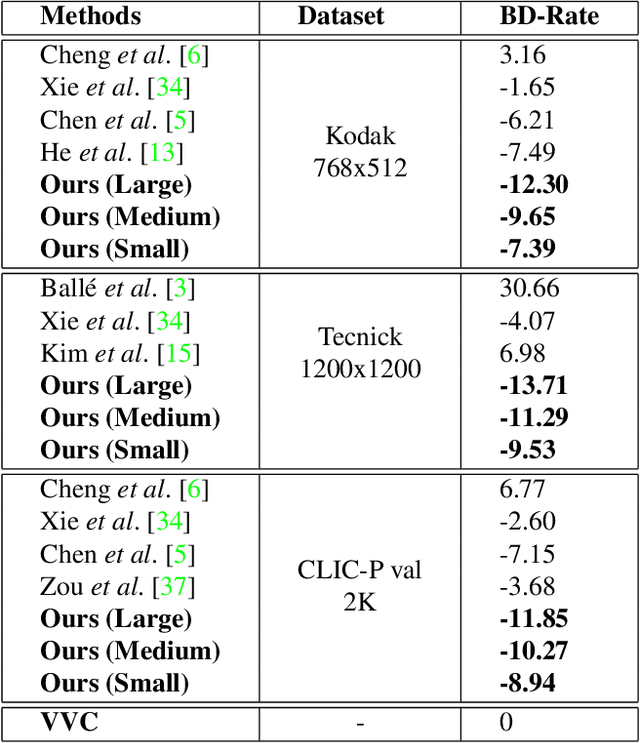
Learned image compression (LIC) methods have exhibited promising progress and superior rate-distortion performance compared with classical image compression standards. Most existing LIC methods are Convolutional Neural Networks-based (CNN-based) or Transformer-based, which have different advantages. Exploiting both advantages is a point worth exploring, which has two challenges: 1) how to effectively fuse the two methods? 2) how to achieve higher performance with a suitable complexity? In this paper, we propose an efficient parallel Transformer-CNN Mixture (TCM) block with a controllable complexity to incorporate the local modeling ability of CNN and the non-local modeling ability of transformers to improve the overall architecture of image compression models. Besides, inspired by the recent progress of entropy estimation models and attention modules, we propose a channel-wise entropy model with parameter-efficient swin-transformer-based attention (SWAtten) modules by using channel squeezing. Experimental results demonstrate our proposed method achieves state-of-the-art rate-distortion performances on three different resolution datasets (i.e., Kodak, Tecnick, CLIC Professional Validation) compared to existing LIC methods. The code is at https://github.com/jmliu206/LIC_TCM.
Multistage Spatial Context Models for Learned Image Compression
Feb 18, 2023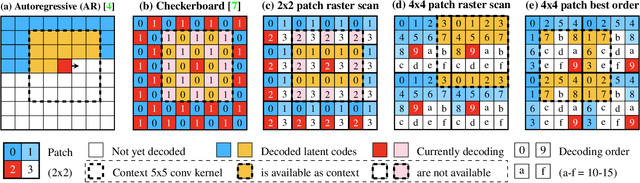

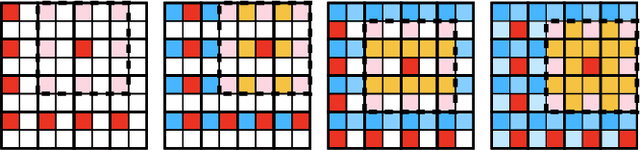
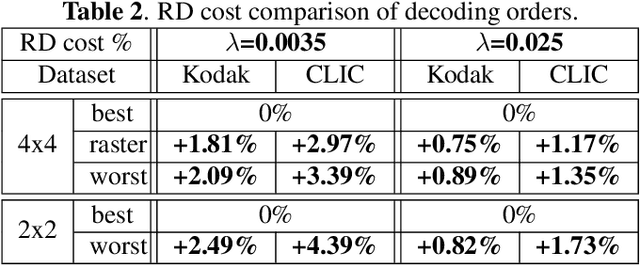
Recent state-of-the-art Learned Image Compression methods feature spatial context models, achieving great rate-distortion improvements over hyperprior methods. However, the autoregressive context model requires serial decoding, limiting runtime performance. The Checkerboard context model allows parallel decoding at a cost of reduced RD performance. We present a series of multistage spatial context models allowing both fast decoding and better RD performance. We split the latent space into square patches and decode serially within each patch while different patches are decoded in parallel. The proposed method features a comparable decoding speed to Checkerboard while reaching the RD performance of Autoregressive and even also outperforming Autoregressive. Inside each patch, the decoding order must be carefully decided as a bad order negatively impacts performance; therefore, we also propose a decoding order optimization algorithm.
ABCAS: Adaptive Bound Control of spectral norm as Automatic Stabilizer
Nov 12, 2022
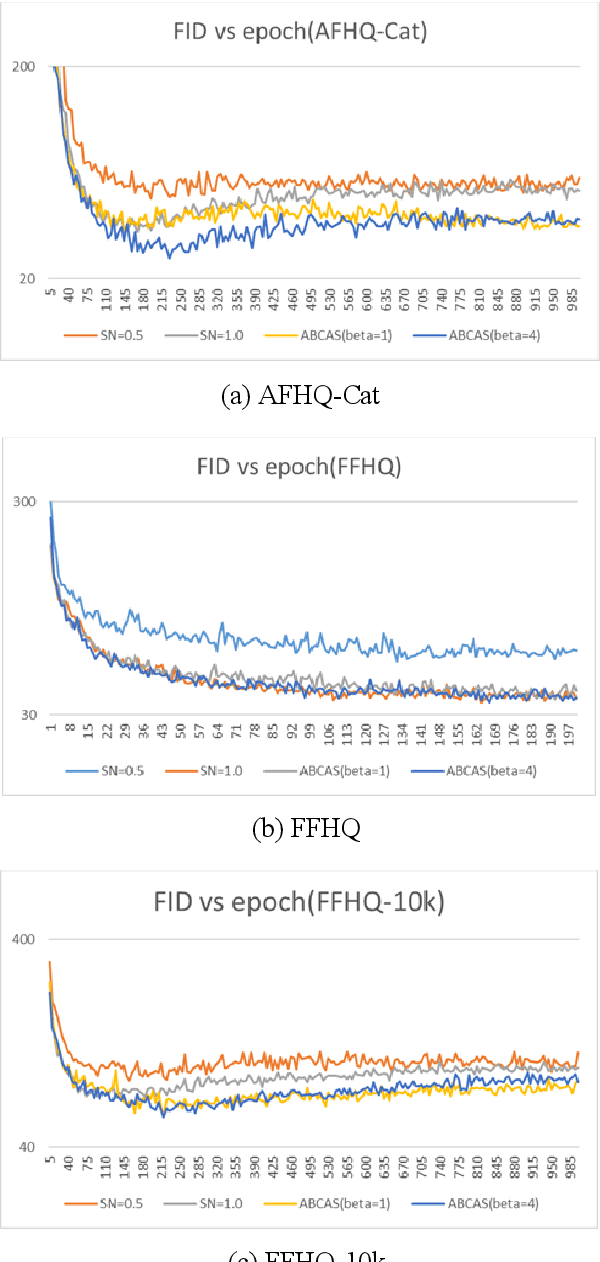
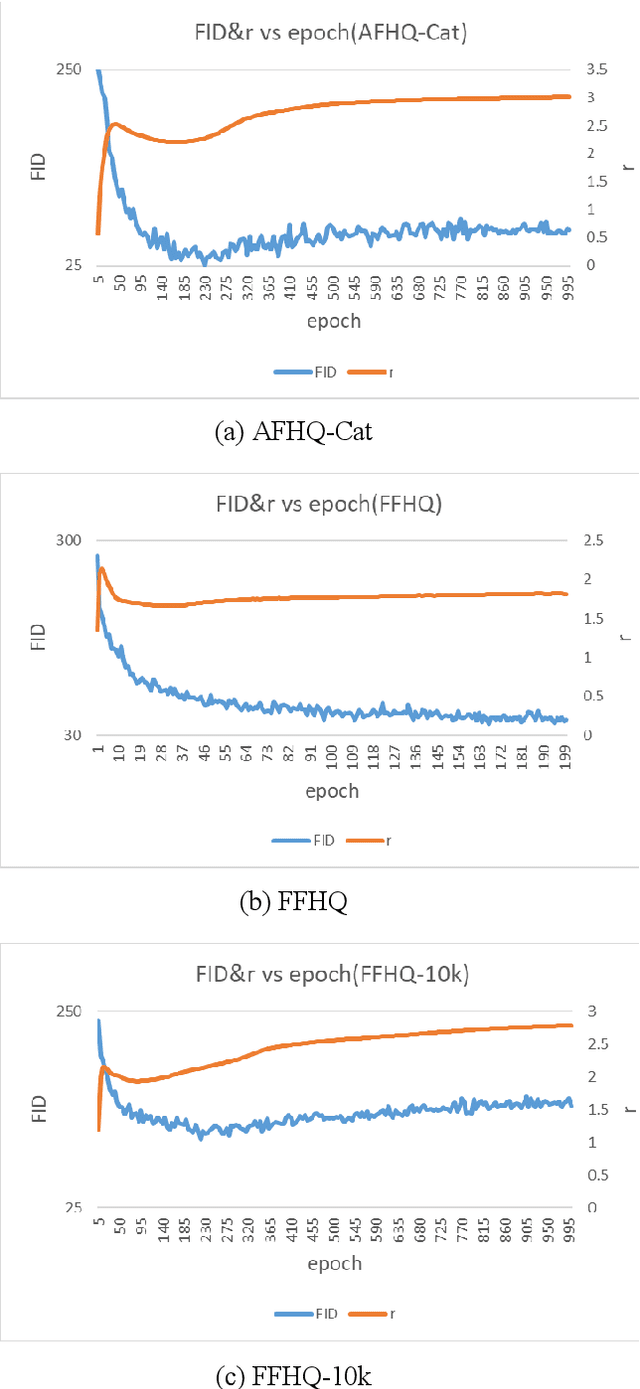

Spectral Normalization is one of the best methods for stabilizing the training of Generative Adversarial Network. Spectral Normalization limits the gradient of discriminator between the distribution between real data and fake data. However, even with this normalization, GAN's training sometimes fails. In this paper, we reveal that more severe restriction is sometimes needed depending on the training dataset, then we propose a novel stabilizer which offers an adaptive normalization method, called ABCAS. Our method decides discriminator's Lipschitz constant adaptively, by checking the distance of distributions of real and fake data. Our method improves the stability of the training of Generative Adversarial Network and achieved better Fr\'echet Inception Distance score of generated images. We also investigated suitable spectral norm for three datasets. We show the result as an ablation study.
Semantic Segmentation in Learned Compressed Domain
Sep 03, 2022
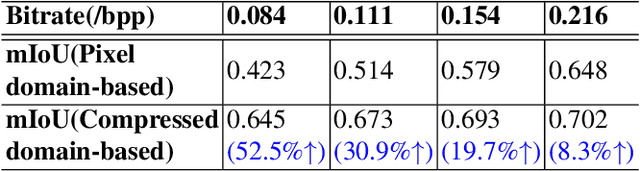
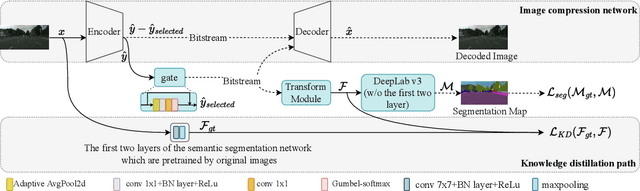

Most machine vision tasks (e.g., semantic segmentation) are based on images encoded and decoded by image compression algorithms (e.g., JPEG). However, these decoded images in the pixel domain introduce distortion, and they are optimized for human perception, making the performance of machine vision tasks suboptimal. In this paper, we propose a method based on the compressed domain to improve segmentation tasks. i) A dynamic and a static channel selection method are proposed to reduce the redundancy of compressed representations that are obtained by encoding. ii) Two different transform modules are explored and analyzed to help the compressed representation be transformed as the features in the segmentation network. The experimental results show that we can save up to 15.8\% bitrates compared with a state-of-the-art compressed domain-based work while saving up to about 83.6\% bitrates and 44.8\% inference time compared with the pixel domain-based method.
Learned Lossless Image Compression With Combined Autoregressive Models And Attention Modules
Aug 30, 2022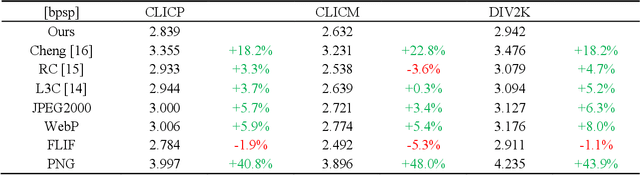
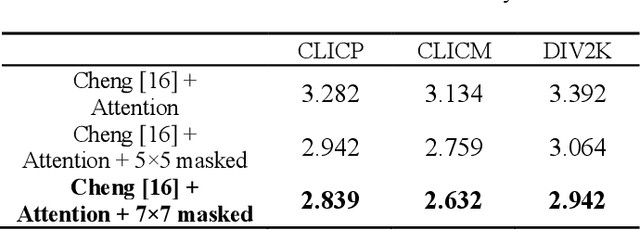

Lossless image compression is an essential research field in image compression. Recently, learning-based image compression methods achieved impressive performance compared with traditional lossless methods, such as WebP, JPEG2000, and FLIF. However, there are still many impressive lossy compression methods that can be applied to lossless compression. Therefore, in this paper, we explore the methods widely used in lossy compression and apply them to lossless compression. Inspired by the impressive performance of the Gaussian mixture model (GMM) shown in lossy compression, we generate a lossless network architecture with GMM. Besides noticing the successful achievements of attention modules and autoregressive models, we propose to utilize attention modules and add an extra autoregressive model for raw images in our network architecture to boost the performance. Experimental results show that our approach outperforms most classical lossless compression methods and existing learning-based methods.
Streaming-capable High-performance Architecture of Learned Image Compression Codecs
Aug 02, 2022
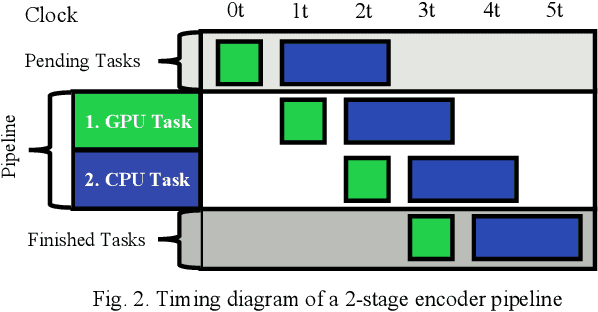
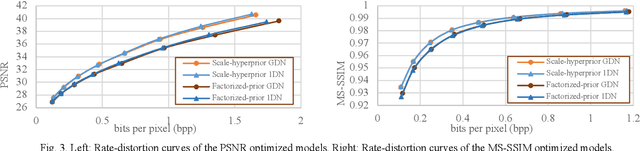
Learned image compression allows achieving state-of-the-art accuracy and compression ratios, but their relatively slow runtime performance limits their usage. While previous attempts on optimizing learned image codecs focused more on the neural model and entropy coding, we present an alternative method to improving the runtime performance of various learned image compression models. We introduce multi-threaded pipelining and an optimized memory model to enable GPU and CPU workloads asynchronous execution, fully taking advantage of computational resources. Our architecture alone already produces excellent performance without any change to the neural model itself. We also demonstrate that combining our architecture with previous tweaks to the neural models can further improve runtime performance. We show that our implementations excel in throughput and latency compared to the baseline and demonstrate the performance of our implementations by creating a real-time video streaming encoder-decoder sample application, with the encoder running on an embedded device.