 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHessam Mahdavifar
Iterative Sketching for Secure Coded Regression
Aug 08, 2023
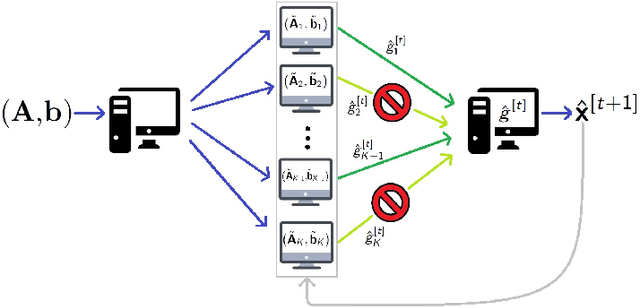
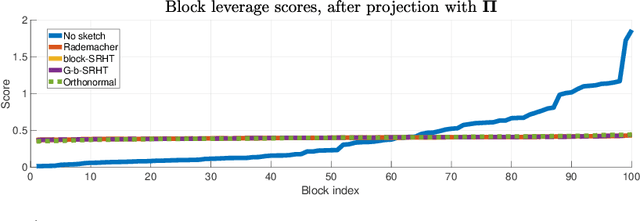
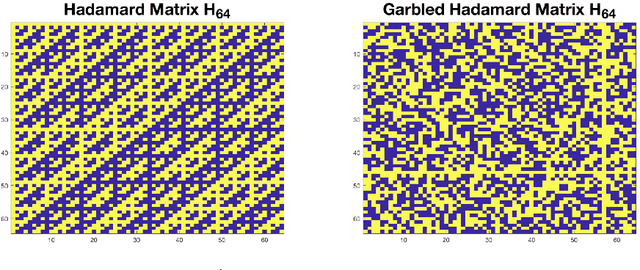
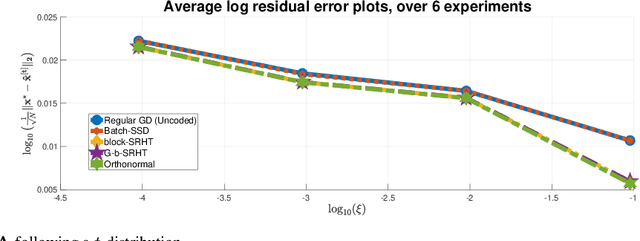
In this work, we propose methods for speeding up linear regression distributively, while ensuring security. We leverage randomized sketching techniques, and improve straggler resilience in asynchronous systems. Specifically, we apply a random orthonormal matrix and then subsample \textit{blocks}, to simultaneously secure the information and reduce the dimension of the regression problem. In our setup, the transformation corresponds to an encoded encryption in an \textit{approximate gradient coding scheme}, and the subsampling corresponds to the responses of the non-straggling workers; in a centralized coded computing network. This results in a distributive \textit{iterative sketching} approach for an $\ell_2$-subspace embedding, \textit{i.e.} a new sketch is considered at each iteration. We also focus on the special case of the \textit{Subsampled Randomized Hadamard Transform}, which we generalize to block sampling; and discuss how it can be modified in order to secure the data.
Capacity-achieving Polar-based Codes with Sparsity Constraints on the Generator Matrices
Mar 16, 2023



In this paper, we leverage polar codes and the well-established channel polarization to design capacity-achieving codes with a certain constraint on the weights of all the columns in the generator matrix (GM) while having a low-complexity decoding algorithm. We first show that given a binary-input memoryless symmetric (BMS) channel $W$ and a constant $s \in (0, 1]$, there exists a polarization kernel such that the corresponding polar code is capacity-achieving with the \textit{rate of polarization} $s/2$, and the GM column weights being bounded from above by $N^s$. To improve the sparsity versus error rate trade-off, we devise a column-splitting algorithm and two coding schemes for BEC and then for general BMS channels. The \textit{polar-based} codes generated by the two schemes inherit several fundamental properties of polar codes with the original $2 \times 2$ kernel including the decay in error probability, decoding complexity, and the capacity-achieving property. Furthermore, they demonstrate the additional property that their GM column weights are bounded from above sublinearly in $N$, while the original polar codes have some column weights that are linear in $N$. In particular, for any BEC and $\beta <0.5$, the existence of a sequence of capacity-achieving polar-based codes where all the GM column weights are bounded from above by $N^\lambda$ with $\lambda \approx 0.585$, and with the error probability bounded by $O(2^{-N^{\beta}} )$ under a decoder with complexity $O(N\log N)$, is shown. The existence of similar capacity-achieving polar-based codes with the same decoding complexity is shown for any BMS channel and $\beta <0.5$ with $\lambda \approx 0.631$.
Machine Learning-Aided Efficient Decoding of Reed-Muller Subcodes
Jan 16, 2023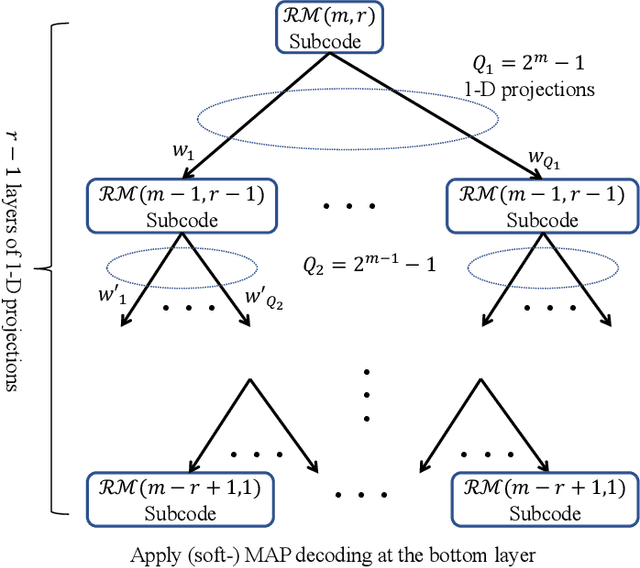
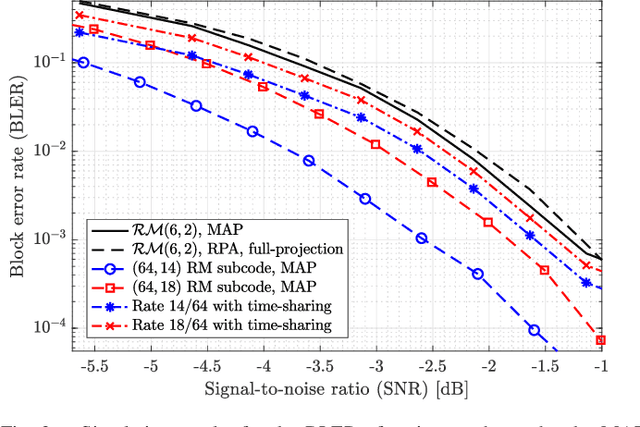
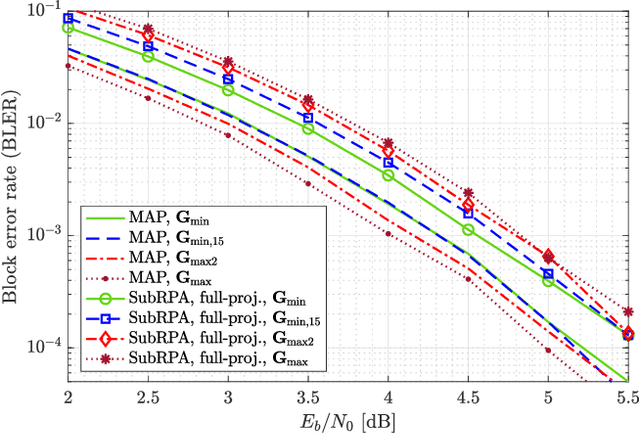
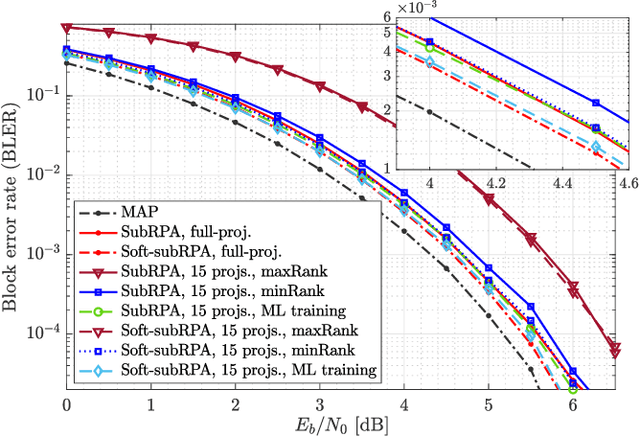
Reed-Muller (RM) codes achieve the capacity of general binary-input memoryless symmetric channels and have a comparable performance to that of random codes in terms of scaling laws. However, they lack efficient decoders with performance close to that of a maximum-likelihood decoder for general code parameters. Also, they only admit limited sets of rates. In this paper, we focus on subcodes of RM codes with flexible rates. We first extend the recently-introduced recursive projection-aggregation (RPA) decoding algorithm to RM subcodes. To lower the complexity of our decoding algorithm, referred to as subRPA, we investigate different approaches to prune the projections. Next, we derive the soft-decision based version of our algorithm, called soft-subRPA, that not only improves upon the performance of subRPA but also enables a differentiable decoding algorithm. Building upon the soft-subRPA algorithm, we then provide a framework for training a machine learning (ML) model to search for \textit{good} sets of projections that minimize the decoding error rate. Training our ML model enables achieving very close to the performance of full-projection decoding with a significantly smaller number of projections. We also show that the choice of the projections in decoding RM subcodes matters significantly, and our ML-aided projection pruning scheme is able to find a \textit{good} selection, i.e., with negligible performance degradation compared to the full-projection case, given a reasonable number of projections.
New Bounds on the Size of Binary Codes with Large Minimum Distance
Feb 07, 2022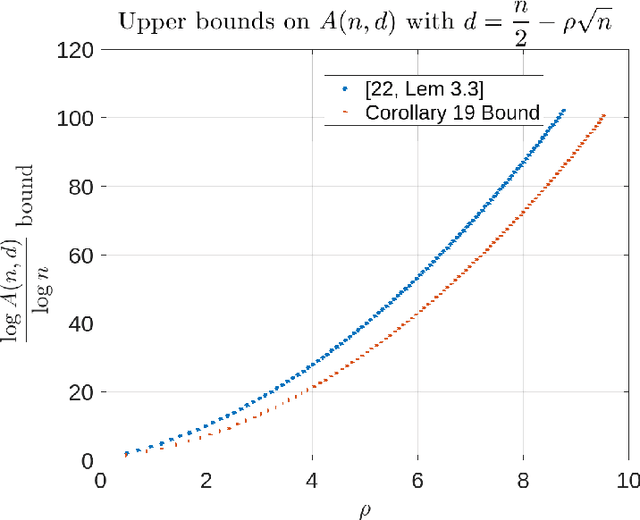
Let A(n, d) denote the maximum number of codewords in a binary code of length n and minimum Hamming distance d. Deriving upper and lower bounds on A(n, d) have been a subject for extensive research in coding theory. In this paper, we examine upper and lower bounds on A(n, d) in the high-minimum distance regime, in particular, when $d = n/2 - \Theta(\sqrt{n})$. We will first provide a lower bound based on a cyclic construction for codes of length $n= 2^m -1$ and show that $A(n, d= n/2 - 2^{c-1}\sqrt{n}) \geq n^c$, where c is an integer with $1 \leq c \leq m/2-1$. With a Fourier-analytic view of Delsarte's linear program, novel upper bounds on $A(n, n/2 - \sqrt{n})$ and $A(n, n/2 - 2 \sqrt{n})$ are obtained, and, to the best of the authors' knowledge, are the first upper bounds scaling polynomially in n for the regime with $d = n/2 - \Theta(\sqrt{n})$.
Orthonormal Sketches for Secure Coded Regression}
Jan 21, 2022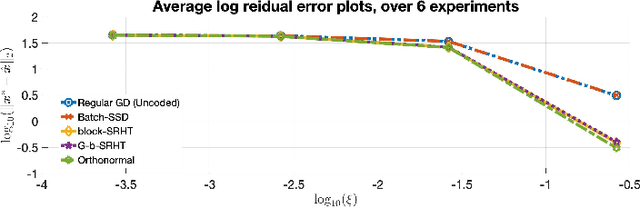
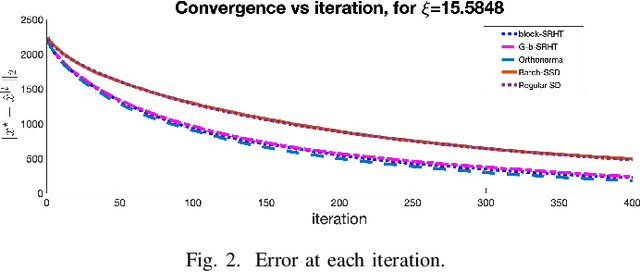
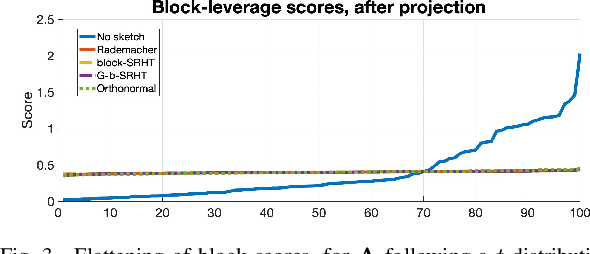
In this work, we propose a method for speeding up linear regression distributively, while ensuring security. We leverage randomized sketching techniques, and improve straggler resilience in asynchronous systems. Specifically, we apply a random orthonormal matrix and then subsample in \textit{blocks}, to simultaneously secure the information and reduce the dimension of the regression problem. In our setup, the transformation corresponds to an encoded encryption in an \textit{approximate} gradient coding scheme, and the subsampling corresponds to the responses of the non-straggling workers; in a centralized coded computing network. We focus on the special case of the \textit{Subsampled Randomized Hadamard Transform}, which we generalize to block sampling; and discuss how it can be used to secure the data. We illustrate the performance through numerical experiments.
FeO2: Federated Learning with Opt-Out Differential Privacy
Oct 28, 2021



Federated learning (FL) is an emerging privacy-preserving paradigm, where a global model is trained at a central server while keeping client data local. However, FL can still indirectly leak private client information through model updates during training. Differential privacy (DP) can be employed to provide privacy guarantees within FL, typically at the cost of degraded final trained model. In this work, we consider a heterogeneous DP setup where clients are considered private by default, but some might choose to opt out of DP. We propose a new algorithm for federated learning with opt-out DP, referred to as \emph{FeO2}, along with a discussion on its advantages compared to the baselines of private and personalized FL algorithms. We prove that the server-side and client-side procedures in \emph{FeO2} are optimal for a simplified linear problem. We also analyze the incentive for opting out of DP in terms of performance gain. Through numerical experiments, we show that \emph{FeO2} provides up to $9.27\%$ performance gain in the global model compared to the baseline DP FL for the considered datasets. Additionally, we show a gap in the average performance of personalized models between non-private and private clients of up to $3.49\%$, empirically illustrating an incentive for clients to opt out.
ApproxIFER: A Model-Agnostic Approach to Resilient and Robust Prediction Serving Systems
Sep 20, 2021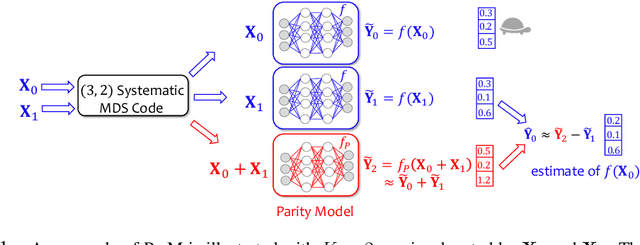
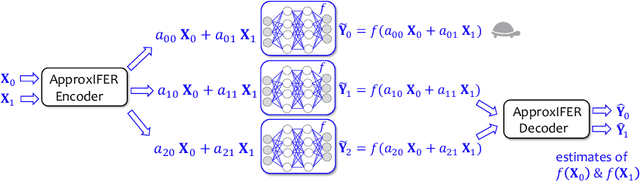
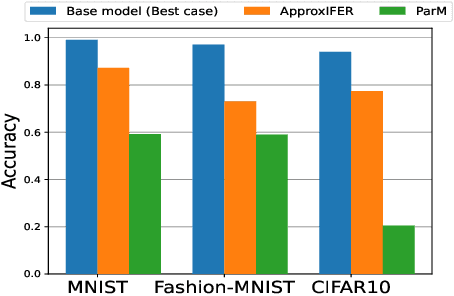

Due to the surge of cloud-assisted AI services, the problem of designing resilient prediction serving systems that can effectively cope with stragglers/failures and minimize response delays has attracted much interest. The common approach for tackling this problem is replication which assigns the same prediction task to multiple workers. This approach, however, is very inefficient and incurs significant resource overheads. Hence, a learning-based approach known as parity model (ParM) has been recently proposed which learns models that can generate parities for a group of predictions in order to reconstruct the predictions of the slow/failed workers. While this learning-based approach is more resource-efficient than replication, it is tailored to the specific model hosted by the cloud and is particularly suitable for a small number of queries (typically less than four) and tolerating very few (mostly one) number of stragglers. Moreover, ParM does not handle Byzantine adversarial workers. We propose a different approach, named Approximate Coded Inference (ApproxIFER), that does not require training of any parity models, hence it is agnostic to the model hosted by the cloud and can be readily applied to different data domains and model architectures. Compared with earlier works, ApproxIFER can handle a general number of stragglers and scales significantly better with the number of queries. Furthermore, ApproxIFER is robust against Byzantine workers. Our extensive experiments on a large number of datasets and model architectures also show significant accuracy improvement by up to 58% over the parity model approaches.
KO codes: Inventing Nonlinear Encoding and Decoding for Reliable Wireless Communication via Deep-learning
Aug 29, 2021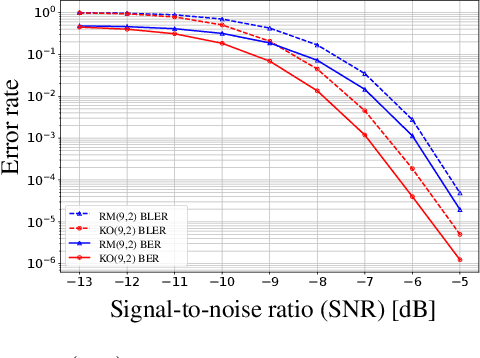

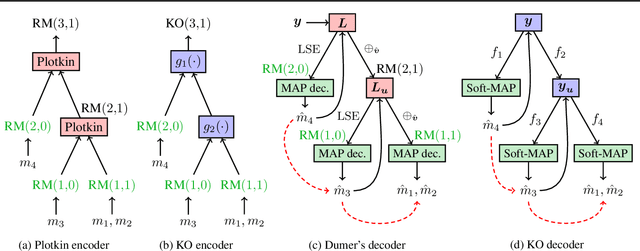
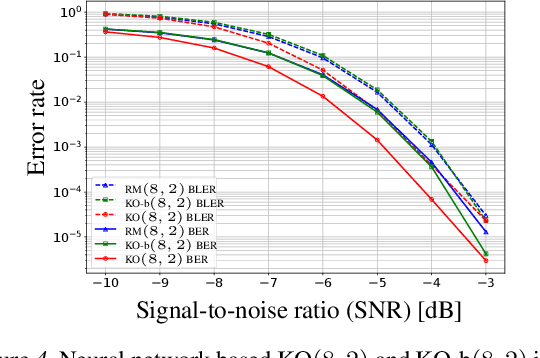
Landmark codes underpin reliable physical layer communication, e.g., Reed-Muller, BCH, Convolution, Turbo, LDPC and Polar codes: each is a linear code and represents a mathematical breakthrough. The impact on humanity is huge: each of these codes has been used in global wireless communication standards (satellite, WiFi, cellular). Reliability of communication over the classical additive white Gaussian noise (AWGN) channel enables benchmarking and ranking of the different codes. In this paper, we construct KO codes, a computationaly efficient family of deep-learning driven (encoder, decoder) pairs that outperform the state-of-the-art reliability performance on the standardized AWGN channel. KO codes beat state-of-the-art Reed-Muller and Polar codes, under the low-complexity successive cancellation decoding, in the challenging short-to-medium block length regime on the AWGN channel. We show that the gains of KO codes are primarily due to the nonlinear mapping of information bits directly to transmit real symbols (bypassing modulation) and yet possess an efficient, high performance decoder. The key technical innovation that renders this possible is design of a novel family of neural architectures inspired by the computation tree of the {\bf K}ronecker {\bf O}peration (KO) central to Reed-Muller and Polar codes. These architectures pave way for the discovery of a much richer class of hitherto unexplored nonlinear algebraic structures. The code is available at \href{https://github.com/deepcomm/KOcodes}{https://github.com/deepcomm/KOcodes}
List-Decodable Coded Computing: Breaking the Adversarial Toleration Barrier
Jan 27, 2021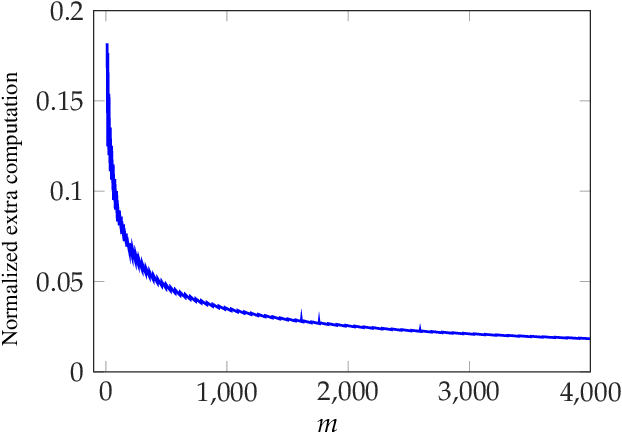
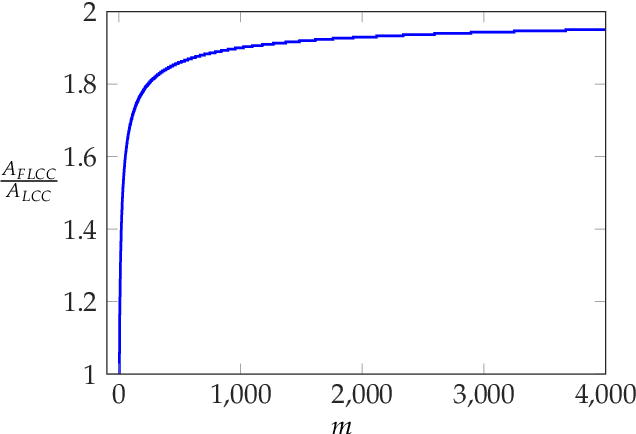
We consider the problem of coded computing where a computational task is performed in a distributed fashion in the presence of adversarial workers. We propose techniques to break the adversarial toleration threshold barrier previously known in coded computing. More specifically, we leverage list-decoding techniques for folded Reed-Solomon (FRS) codes and propose novel algorithms to recover the correct codeword using side information. In the coded computing setting, we show how the master node can perform certain carefully designed extra computations in order to obtain the side information. This side information will be then utilized to prune the output of list decoder in order to uniquely recover the true outcome. We further propose folded Lagrange coded computing, referred to as folded LCC or FLCC, to incorporate the developed techniques into a specific coded computing setting. Our results show that FLCC outperforms LCC by breaking the barrier on the number of adversaries that can be tolerated. In particular, the corresponding threshold in FLCC is improved by a factor of two compared to that of LCC.
Coded Machine Unlearning
Dec 31, 2020



Models trained in machine learning processes may store information about individual samples used in the training process. There are many cases where the impact of an individual sample may need to be deleted and unlearned (i.e., removed) from the model. Retraining the model from scratch after removing a sample from its training set guarantees perfect unlearning, however, it becomes increasingly expensive as the size of training dataset increases. One solution to this issue is utilizing an ensemble learning method that splits the dataset into disjoint shards and assigns them to non-communicating weak learners and then aggregates their models using a pre-defined rule. This framework introduces a trade-off between performance and unlearning cost which may result in an unreasonable performance degradation, especially as the number of shards increases. In this paper, we present a coded learning protocol where the dataset is linearly coded before the learning phase. We also present the corresponding unlearning protocol for the aforementioned coded learning model along with a discussion on the proposed protocol's success in ensuring perfect unlearning. Finally, experimental results show the effectiveness of the coded machine unlearning protocol in terms of performance versus unlearning cost trade-off.