 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongbo Li
Traj-LLM: A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models
May 08, 2024
Predicting the future trajectories of dynamic traffic actors is a cornerstone task in autonomous driving. Though existing notable efforts have resulted in impressive performance improvements, a gap persists in scene cognitive and understanding of the complex traffic semantics. This paper proposes Traj-LLM, the first to investigate the potential of using Large Language Models (LLMs) without explicit prompt engineering to generate future motion from agents' past/observed trajectories and scene semantics. Traj-LLM starts with sparse context joint coding to dissect the agent and scene features into a form that LLMs understand. On this basis, we innovatively explore LLMs' powerful comprehension abilities to capture a spectrum of high-level scene knowledge and interactive information. Emulating the human-like lane focus cognitive function and enhancing Traj-LLM's scene comprehension, we introduce lane-aware probabilistic learning powered by the pioneering Mamba module. Finally, a multi-modal Laplace decoder is designed to achieve scene-compliant multi-modal predictions. Extensive experiments manifest that Traj-LLM, fortified by LLMs' strong prior knowledge and understanding prowess, together with lane-aware probability learning, outstrips state-of-the-art methods across evaluation metrics. Moreover, the few-shot analysis further substantiates Traj-LLM's performance, wherein with just 50% of the dataset, it outperforms the majority of benchmarks relying on complete data utilization. This study explores equipping the trajectory prediction task with advanced capabilities inherent in LLMs, furnishing a more universal and adaptable solution for forecasting agent motion in a new way.
Human-in-the-loop Learning for Dynamic Congestion Games
Apr 24, 2024Today mobile users learn and share their traffic observations via crowdsourcing platforms (e.g., Waze). Yet such platforms simply cater to selfish users' myopic interests to recommend the shortest path, and do not encourage enough users to travel and learn other paths for future others. Prior studies focus on one-shot congestion games without considering users' information learning, while our work studies how users learn and alter traffic conditions on stochastic paths in a human-in-the-loop manner. Our analysis shows that the myopic routing policy leads to severe under-exploration of stochastic paths. This results in a price of anarchy (PoA) greater than $2$, as compared to the socially optimal policy in minimizing the long-term social cost. Besides, the myopic policy fails to ensure the correct learning convergence about users' traffic hazard beliefs. To address this, we focus on informational (non-monetary) mechanisms as they are easier to implement than pricing. We first show that existing information-hiding mechanisms and deterministic path-recommendation mechanisms in Bayesian persuasion literature do not work with even (\text{PoA}=\infty). Accordingly, we propose a new combined hiding and probabilistic recommendation (CHAR) mechanism to hide all information from a selected user group and provide state-dependent probabilistic recommendations to the other user group. Our CHAR successfully ensures PoA less than (\frac{5}{4}), which cannot be further reduced by any other informational (non-monetary) mechanism. Besides the parallel network, we further extend our analysis and CHAR to more general linear path graphs with multiple intermediate nodes, and we prove that the PoA results remain unchanged. Additionally, we carry out experiments with real-world datasets to further extend our routing graphs and verify the close-to-optimal performance of our CHAR.
Path Planning Considering Time-Varying and Uncertain Movement Speed in Multi-Robot Automatic Warehouses: Problem Formulation and Algorithm
Dec 01, 2022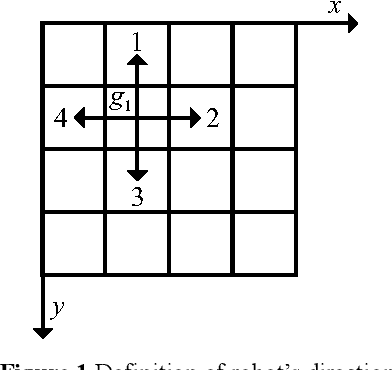

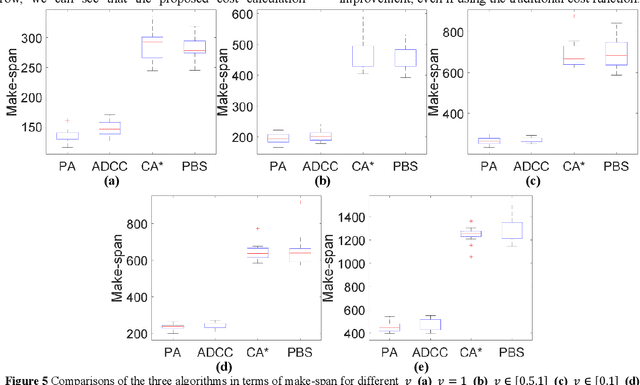
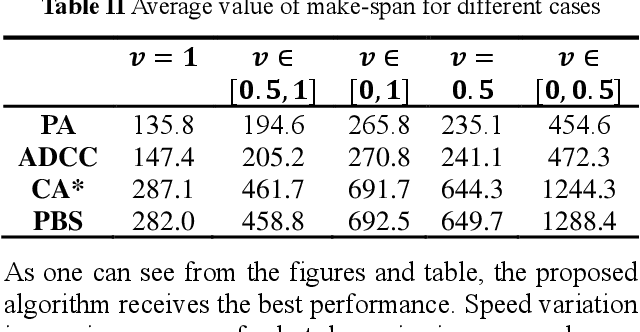
Path planning in the multi-robot system refers to calculating a set of actions for each robot, which will move each robot to its goal without conflicting with other robots. Lately, the research topic has received significant attention for its extensive applications, such as airport ground, drone swarms, and automatic warehouses. Despite these available research results, most of the existing investigations are concerned with the cases of robots with a fixed movement speed without considering uncertainty. Therefore, in this work, we study the problem of path-planning in the multi-robot automatic warehouse context, which considers the time-varying and uncertain robots' movement speed. Specifically, the path-planning module searches a path with as few conflicts as possible for a single agent by calculating traffic cost based on customarily distributed conflict probability and combining it with the classic A* algorithm. However, this probability-based method cannot eliminate all conflicts, and speed's uncertainty will constantly cause new conflicts. As a supplement, we propose the other two modules. The conflict detection and re-planning module chooses objects requiring re-planning paths from the agents involved in different types of conflicts periodically by our designed rules. Also, at each step, the scheduling module fills up the agent's preserved queue and decides who has a higher priority when the same element is assigned to two agents simultaneously. Finally, we compare the proposed algorithm with other algorithms from academia and industry, and the results show that the proposed method is validated as the best performance.
Finding and Exploring Promising Search Space for the 0-1 Multidimensional Knapsack Problem
Oct 08, 2022

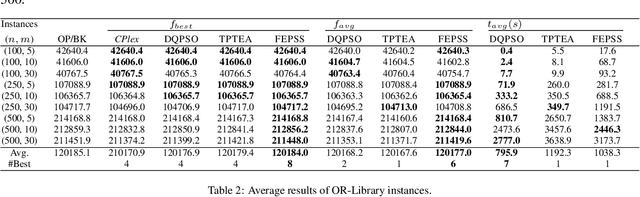
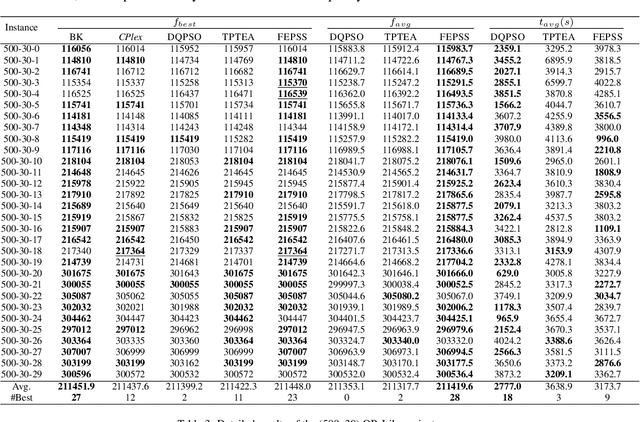
The 0-1 multidimensional knapsack problem(MKP) is a classical NP-hard combinatorial optimization problem. In this paper, we propose a novel heuristic algorithm simulating evolutionary computation and large neighbourhood search for the MKP. It maintains a set of solutions and abstracts information from the solution set to generate good partial assignments. To find high-quality solutions, integer programming is employed to explore the promising search space specified by the good partial assignments. Extensive experimentation with commonly used benchmark sets shows that our approach outperforms the state of the art heuristic algorithms, TPTEA and DQPSO, in solution quality. It finds new lower bound for 8 large and hard instances
Adaptive Task Planning for Large-Scale Robotized Warehouses
Apr 24, 2022
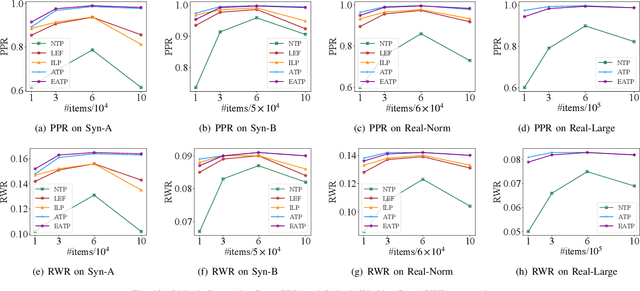
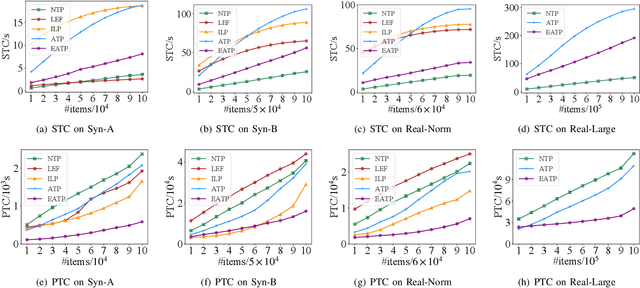
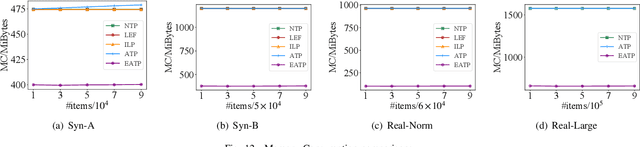
Robotized warehouses are deployed to automatically distribute millions of items brought by the massive logistic orders from e-commerce. A key to automated item distribution is to plan paths for robots, also known as task planning, where each task is to deliver racks with items to pickers for processing and then return the rack back. Prior solutions are unfit for large-scale robotized warehouses due to the inflexibility to time-varying item arrivals and the low efficiency for high throughput. In this paper, we propose a new task planning problem called TPRW, which aims to minimize the end-to-end makespan that incorporates the entire item distribution pipeline, known as a fulfilment cycle. Direct extensions from state-of-the-art path finding methods are ineffective to solve the TPRW problem because they fail to adapt to the bottleneck variations of fulfillment cycles. In response, we propose Efficient Adaptive Task Planning, a framework for large-scale robotized warehouses with time-varying item arrivals. It adaptively selects racks to fulfill at each timestamp via reinforcement learning, accounting for the time-varying bottleneck of the fulfillment cycles. Then it finds paths for robots to transport the selected racks. The framework adopts a series of efficient optimizations on both time and memory to handle large-scale item throughput. Evaluations on both synthesized and real data show an improvement of $37.1\%$ in effectiveness and $75.5\%$ in efficiency over the state-of-the-arts.
Robopheus: A Virtual-Physical Interactive Mobile Robotic Testbed
Mar 07, 2021
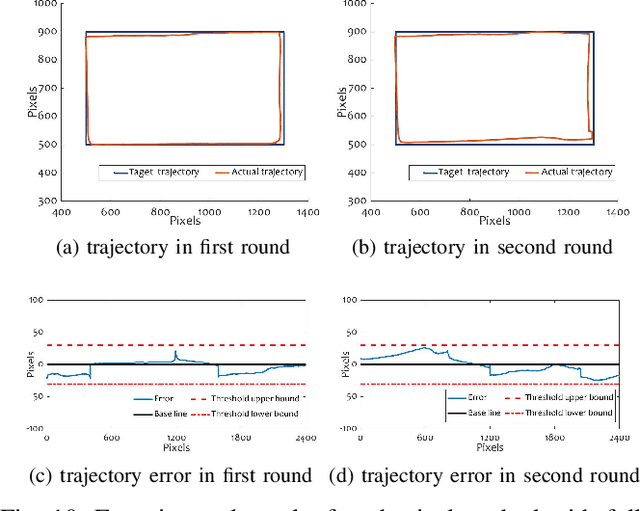

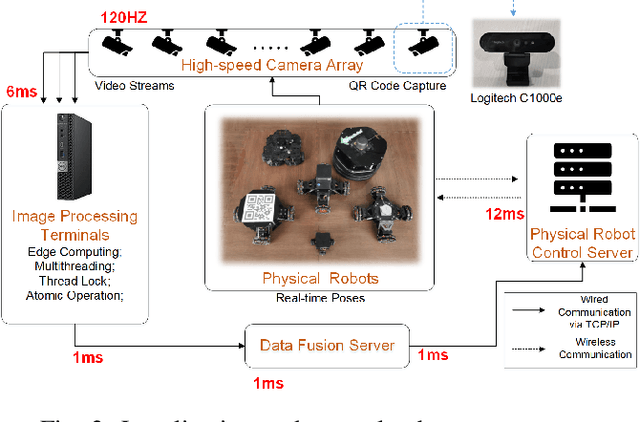
The mobile robotic testbed is an essential and critical support to verify the effectiveness of mobile robotics research. This paper introduces a novel multi-robot testbed, named Robopheus, which exploits the ideas of virtual-physical modeling in digital-twin. Unlike most existing testbeds, the developed Robopheus constructs a bridge that connects the traditional physical hardware and virtual simulation testbeds, providing scalable, interactive, and high-fidelity simulations-tests on both sides. Another salient feature of the Robopheus is that it enables a new form to learn the actual models from the physical environment dynamically and is compatible with heterogeneous robot chassis and controllers. In turn, the virtual world's learned models are further leveraged to approximate the robot dynamics online on the physical side. Extensive experiments demonstrate the extraordinary performance of the Robopheus. Significantly, the physical-virtual interaction design increases the trajectory accuracy of a real robot by 300%, compared with that of not using the interaction.